Voice- this is the sound that is produced under the pressure of exhaled air when tense vocal cords close to each other vibrate in the larynx. The main qualities of any voice are strength, height, timbre. A well-produced voice is also characterized by such properties as euphony, flight, mobility and variety of tone.
The power of the voice- this is its volume, depending on the activity of the respiratory and speech organs. A person must be able to vary the strength of his voice depending on the communication conditions. Therefore, the ability to speak both loudly and quietly is equally necessary.
Voice pitch- this is his ability to tonal changes, that is, his range. An ordinary voice has a range of one and a half octaves, but in everyday speech a person most often uses only 3-4 notes. Expanding the range makes speech more expressive.
Voice timbre- a unique individual coloring, which is determined by the structure of the speech apparatus, mainly by the nature of the overtones formed in the resonators - lower (trachea, bronchi) and upper (oral cavity and nasal cavity). If we cannot arbitrarily control the lower resonators, then the use of the upper resonators can be improved.
Euphony of voice— the purity of its sound, the absence of unpleasant overtones (hoarseness, hoarseness, nasality, etc.). The concept of euphony includes, first of all, sonority. The voice sounds loud when it resonates at the front of the mouth. If the sound is formed near the soft palate, it turns out dull and dull. The sonority of the voice also depends on the concentration of the sound (its concentration at the front teeth), on the direction of the sound, as well as on the activity of the lips.
The euphony of the voice also implies the freedom of its sound, which is achieved by the free functioning of all organs of speech, the absence of tension and muscle tension. This freedom comes at the cost of long exercise. The euphony of the voice should not be equated with the euphony of speech.
Euphony of speech- this is the absence in speech of a combination or frequent repetition of sounds that hurt the ear. The euphony of speech presupposes the most perfect combination of sounds, convenient for pronunciation and pleasant to the ear.
For example, the repetition within a phrase or phrase of whistling and hissing sounds without special stylistic purposes causes cacophony (that is, is assessed as bad-sounding): “in our class there are many students who are conscientiously preparing for the upcoming exams, but there are also quitters”; stringing together words with several consonants in a row: “the gaze of all senses is nobler”; It is not recommended to construct phrases in such a way that there is a gap in the vowels: “and in John.” However, problems of euphony do not relate to speech technique.
Voice mobility- this is his ability to change in strength, height, and tempo without tension. These changes should not be involuntary; for an experienced speaker, changing certain qualities of the voice always pursues a specific goal.
Tone of voice- emotional and expressive coloring of the voice, facilitating the expression in the speaker’s speech, his feelings and intentions. The tone of speech can be kind, angry, enthusiastic, official, friendly, etc. It is created using such means as increasing or weakening the strength of the voice, pauses, accelerating or slowing down the rate of speech.
Speech rate— speed of pronunciation of speech elements (sounds, syllables, words). The absolute rate of speech depends on the individual characteristics of the speaker, the characteristics of his emotional state and communication situation, and pronunciation style.
The tempo of speech is not a direct property of a person’s voice itself, however, the ability to vary, if necessary, the speed of pronunciation of words and phrases can also be attributed to those skills that should be improved in the discipline “Speech Technique”.
Intonation- This is the rhythmic and melodic structure of speech. Intonation includes: pitch, sound strength, tempo, stress and pauses. Means of expressiveness of intonation are conventionally divided into logical and emotional. The main means of logical expressiveness of intonation are logical pause, logical stress, logical melody and logical perspective.
With emotional intonation, words are saturated with emotional content, provided that the thought is properly assessed and one’s attitude towards it is manifested. At the same time, distinctly intense emotional stresses and pauses appear in the intonation, caused by feelings, mood, and desire. They do not always coincide with logical ones, but such a coincidence is desirable.
The human voice is made up of a combination of sounds with different characteristics, which are formed with the participation of the vocal apparatus. The source of voice is the larynx with vibrating vocal cords. The larynx is a tube connecting the windpipe (trachea) and pharynx. The walls of the larynx consist of cartilages: cricoid, thyroid, suprapharyngeal and 2 arytenoids. The muscles of the larynx are divided into external and internal; the external muscles connect the larynx to other parts of the body, raise and lower it. When the internal muscles contract, they move certain cartilages of the larynx, as well as the vocal cords, which expands or narrows the glottis. In the upper part of the larynx there are false vocal cords, the muscle fibers of which are poorly developed (in some cases, when voice disorders are eliminated in patients, a false ligamentous or false-fold voice is formed). Below the false vocal cords are the true vocal cords, which protrude in the form of folds and are mainly composed of muscle fibers; the distance between the vocal cords is called the glottis.
When inhaling, the glottis is fully opened and takes the shape of a triangle with its apex at the thyroid cartilage. During the exhalation phase, the vocal folds move somewhat closer together, but do not close the lumen of the larynx. During phonation, that is, in the process of voice formation, the vocal folds begin to vibrate, allowing portions of air to pass from the lungs. During normal examination, they appear to be closed, since the eye does not detect the speed of the oscillatory movements. When whispering, the vocal folds are opened in the shape of a triangle. The vocal folds do not vibrate, and the air leaving the lungs encounters resistance from the organs of articulation in the form of slits and closures, which creates a specific noise. Innervation of the larynx is carried out by the sympathetic nerve and the 2nd branches of the vagus nerve - the superior and inferior laryngeal nerve.
The concept of sound is considered in line with various sciences. Among the sounds around us, tones and noises are distinguished. Tone sounds are generated by periodic vibrations of a sound source with a certain frequency; noise appears during random vibrations of various physical natures. In the human vocal apparatus, both tonal sounds and noises (vowel sounds and voiceless consonants) are formed.
1) Pitch– this is the subjective perception of the hearing organs of the frequency of oscillatory movements. In conversational speech, the frequency of the fundamental tone of the voice varies in men from 85 to 200 Hz, and in women from 160 to 340 Hz. Voice modulation in height ensures the expressiveness of oral speech (7 types of intonation structures in the Russian language). The concept of tonal range is distinguished, that is, the ability to produce sounds within certain limits, from the lowest tone to the highest. These possibilities are individual for each person. The singing voice has a large range. Vocal proficiency in the 2nd octave is mandatory for vocalists. However, there are known cases of having a voice of 4-5 octaves (sounds in the range of 43 - 2300 Hz).
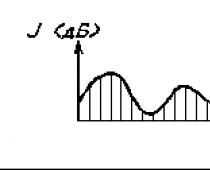
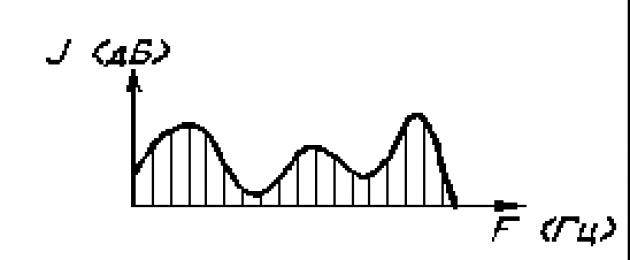
2) The power of the voice– is perceived objectively as the volume of sound and depends on the amplitude of vibrations of the vocal cords, on the degree of subglottic pressure of the air stream. In colloquial speech, the intensity of the voice ranges from 40 to 70 dB, the voice of singers has 90 – 110 dB, and in some cases can reach 120 dB (the noise intensity of an aircraft engine).
Human hearing has adaptive capabilities, thanks to which you can listen to quiet sounds against loud ones, or gradually get used to noise and begin to distinguish sounds. However, even with this, loud sounds are not indifferent to human hearing - at 130 dB the pain threshold occurs, 150 dB is intolerance, and 180 dB is fatal to humans.
The concept of dynamic range of the voice is distinguished, that is, the maximum difference between the quietest and loudest sounds.
A wide range is important for singers (up to 30 dB), as well as for people in voice-speech professions.
3) Voice timbre, that is, its individual painting. Timbre consists of the main tone of the voice and overtones, that is, overtones that have a higher pitch. The appearance of these overtones is due to the fact that the vocal folds vibrate not only along their length, reproducing the main tone, but also in their individual parts. These partial vibrations create overtones that are several times higher than the fundamental tone.
The head resonator includes the cavities of the facial part above the palatine vault (nasal cavity and its paranasal sinuses). The head resonator ensures the sonority and flightiness of the voice.
The chest resonator includes the chest, trachea and large bronchi, providing power and softness to the voice.
The human voice is made up of a combination of sounds with various characteristics, formed with the participation of the vocal apparatus. The source of voice is the larynx with vibrating vocal folds. The distance between the vocal folds is usually called the glottis. When inhaling, the glottis is fully opened and takes the shape of a triangle with an acute angle at the thyroid cartilage (Fig. 1). During the exhalation phase, the vocal folds come somewhat closer together, but do not completely close the lumen of the larynx.
At the moment of phonation, i.e. sound reproduction, the vocal folds begin to vibrate, allowing portions of air to pass from the lungs. During normal examination, they appear to be closed, since the eye does not detect the speed of oscillatory movements (Fig. 2).
The human voice, acoustic properties, and mechanisms of production are studied by a variety of sciences - physiology, phonetics, phoniatry, speech therapy, etc.
Posted on ref.rf
Since the vocal phenomenon is not only a physiological, but also a physical phenomenon, it becomes the subject of research in such a branch of physics as acoustics, which gives clear characteristics of each reproduced sound. According to acoustics, sound is the propagation of vibrations in an elastic medium. A person speaks and sings in the air, because the sound of a voice is the vibration of air particles, propagating in the form of waves of condensation and rarefaction, like waves on water, at a speed of 340 m/s at a temperature of +18°C.
Among the sounds around us, there are tonal sounds and noises. The first ones are generated by periodic oscillations of a sound source with a certain frequency. The frequency of vibrations creates a sensation of pitch in our auditory organ. Noises appear during random vibrations of various physical natures.
Both tone and noise sounds occur in the human vocal apparatus. All vowels have a tone character, and voiceless consonants have a noise character. The more often periodic vibrations occur, the higher the sound we perceive. Thus, pitch- This is the subjective perception by the organ of hearing of the frequency of oscillatory movements. The quality of the pitch of a sound depends on the frequency of vibration of the vocal folds in 1 s. How many closings and openings the vocal folds make during their oscillations and how many portions of condensed subglottic air they pass through, the frequency of the generated sound turns out to be the same, i.e. pitch. The frequency of the fundamental tone is measured in hertz and can vary in the range from 85 to 200 Hz in normal conversational speech for men, and from 160 to 340 Hz for women.
Changing the pitch of the fundamental tone creates expressiveness in speech. One of the components of intonation is melody - relative changes in the pitch of the fundamental tone of sounds. Human speech is very rich in changes in melodic pattern: narrative sentences are characterized by a lowering of tone at the end; Interrogative intonation is achieved by significantly raising the fundamental tone of the word containing the question. The root tone always rises on a stressed syllable. The absence of a noticeable, changing melody of speech makes it unexpressive and usually indicates some kind of pathology.
To characterize a normal voice, there is such a thing as tonal range- voice volume- the ability to produce sounds within certain limits from the lowest tone to the highest. This property is individual for each person. The tonal range of women's spoken voice is within one octave, and for men it is slightly less, i.e. the change in the fundamental tone during a conversation based on emotional coloring fluctuates within 100 Hz. The tonal range of the singing voice is much wider - the singer must have a voice of two octaves. Singers are known whose range reaches four and five octaves: they can take sounds from 43 Hz - the lowest voices - to 2,300 Hz - high voices.
The power of the voice, ᴇᴦο power, depends on the intensity of the amplitude of vibrations of the vocal folds and is measured in decibels; the greater the amplitude of these vibrations, the stronger the voice. However, to a greater extent this depends on the subglottic pressure of air exhaled from the lungs at the time of phonation. That is why, if a person is about to shout loudly, he first takes a breath. The strength of the voice depends not only on the amount of air in the lungs, but also on the ability to expend exhaled air, maintaining constant subglottic pressure. A normal spoken voice, according to various authors, ranges from 40 to 70 dB. The singers' voice has 90-110 dB, and sometimes reaches 120 dB - the noise level of an aircraft engine. Human hearing has adaptive capabilities. We can hear quiet sounds against a background of strong noise or, finding ourselves in a noisy room, at first we do not distinguish anything, then we get used to it and begin to hear spoken language. However, even with the adaptive capabilities of human hearing, strong sounds are not indifferent to the body: at 130 dB the pain threshold occurs, at 150 dB there is intolerance, and a sound strength of 180 dB is fatal for a person.
Of particular importance in characterizing the strength of the voice is dynamic range- the maximum difference between the quietest sound (piano) and the loudest sound (forte). A large dynamic range (up to 30 dB) is a necessary condition for professional singers, but it is important in the spoken voice and for teachers, as it gives speech greater expressiveness.
When the coordination relationship between the tension of the vocal folds and air pressure is disrupted, a loss of voice strength and a change in timbre occurs.
Sound timbre is a significant characteristic of the voice. By this quality we recognize familiar people, famous singers, without yet seeing them with our own eyes. In human speech, all sounds are complex. Timbre reflects their acoustic composition, i.e. structure. It is important to note that each voice sound consists of a fundamental tone, which determines the pitch, and numerous additional or overtones of a higher frequency than the main tone. The frequency of the overtones is two, three, four, and so on times greater than the frequency of the fundamental tone. The appearance of overtones is due to the fact that the vocal folds vibrate not only along their length, reproducing the fundamental tone, but also in their individual parts. It is these partial vibrations that create overtones, which are several times higher than the fundamental tone. Any sound can be analyzed on a special device and divided into individual overtone components. It is important to note that each vowel in its overtone composition contains areas of amplified frequencies that characterize only that sound. These areas are called vowel formants. There are several of them in the sound. For ᴇᴦο distinction, the first two formants are sufficient. The first formant - the frequency range 150-850 Hz - during articulation is provided by the degree of elevation of the tongue. The second formant - the range of 500-2,500 Hz - depends on the row of the vowel sound. The sounds of ordinary spoken speech are located in the range of 300-400 Hz. Voice qualities such as sonority and flight depend on the frequency regions in which overtones appear.
Voice timbre is studied both in our country (V. S. Kazansky, 1928; S. N. Rzhevkin, 1956; E. A. Rudakov, 1864; M. P. Morozov, 1967), and abroad (V. Bartholomew, 1934; R. Husson, 1962; G. Fant, 1964). The timbre is formed due to the resonance that occurs in the cavities of the mouth, pharynx, larynx, trachea, and bronchi. Resonance is a sharp increase in the amplitude of forced oscillations that occur when the frequency of oscillations of an external influence coincides with the frequency of natural oscillations of the system. During phonation, resonance enhances the individual overtones of sound formed in the larynx and causes coincidence of air vibrations in the cavities of the chest and the extension tube.
The interconnected system of resonators not only enhances the overtones, but also affects the very nature of vibrations of the vocal folds, activating them, which in turn causes even greater resonance. There are two main resonators - head and chest. The head (or upper) refers to the cavities located in the facial part of the head above the palatine vault - the nasal cavity and its paranasal sinuses. When using upper resonators, the voice acquires a bright flying character, and the speaker or singer has the feeling that the sound is passing through the facial parts of the skull. Research by R. Yussen (1950) has proven that vibration phenomena in the head resonator excite the facial and trigeminal nerves, which are associated with the innervation of the vocal folds and stimulate vocal function.
With thoracic resonance, vibration of the chest occurs, here the trachea and large bronchi serve as resonators. At the same time, the timbre of the voice is “soft”. A good, full-fledged voice simultaneously sounds the head and chest resonators and accumulates sound energy. Vibrating vocal folds and a resonator system increase the efficiency of the vocal apparatus.
Optimal conditions for the functioning of the vocal apparatus appear when a certain resistance is created in the supraglottic cavities (superglottic tube) to portions of subglottic air passing through the vibrating vocal folds at the time of phonation. This resistance is called return impedance.
Concept and types, 2018.
When a sound is formed in the area from the glottis to the oral opening, the return impedance exhibits its protective function, creating preconditions in the reflex adaptation mechanism for the most favorable, rapidly increasing impedance. The return impedance precedes phonation by thousandths of a second, creating the most favorable gentle conditions for it. At the same time, the vocal folds work with low energy consumption and a good acoustic effect.
Concept and types, 2018.
The phenomenon of return impedance is one of the most important protective acoustic mechanisms in the operation of the vocal apparatus.
1) first there is a slight exhalation, then the vocal folds close and begin to vibrate - the voice sounds as if after a slight noise. This method is considered an aspirate attack;
The most common and physiologically justified is a soft attack. Abuse of hard or aspirated voice delivery methods can lead to significant changes in the vocal apparatus and loss of necessary sound qualities. It has been proven that long-term use of an aspiratory attack leads to a decrease in the tone of the internal muscles of the larynx, and a constant hard vocal attack can provoke organic changes in the vocal folds - the occurrence of contact ulcers, granulomas, nodules. However, the use of aspirated and hard sound attacks is still possible based on the tasks and emotional state of a person, and sometimes for the purpose of voice training in one specific period of classes.
The considered acoustic properties are inherent in a normal, healthy voice. As a result of voice-speech practice, all people develop a fairly clear idea of the voice norm of children and adults based on gender and age. In speech therapy, “speech norms” mean generally accepted options for using language in the process of speech activity. This fully applies to determining the norm of voice. A healthy voice should be loud enough, the pitch of the fundamental tone should be appropriate for the age and gender of the person, the ratio of speech and nasal resonance should be adequate to the phonetic patterns of the given language.

Chapter 1. Basic concepts and physical parameters used to evaluate and characterize voice
Voice is a set of sounds produced by the human vocal apparatus, which can be varied. A person can scream, moan, imitate various sounds, and most importantly, speak or sing. This is why any sound of human speech can be objectively analyzed with great accuracy, since it is a physical phenomenon studied by acoustics.
In acoustics, sound refers to the propagation of vibrations, i.e. waves in an elastic medium (L.B. Dmitriev et al., 1968, 1990). Phonation occurs in the air; in other words, the sound of a voice is the vibration of air particles, propagating in the form of vibration of waves of condensation and rarefaction. During speech, sound vibrations travel not only through the airways into the outer space, but also through the internal tissues of the body, causing vibrations in the chest and head.
The source of the voice is the human vocal folds, which, when brought together, are tense and begin to vibrate (Fig. 13). This is the reason for the occurrence of periodic thickenings and rarefaction of the air stream, occurring as a result of increased subglottic pressure. Sound waves, originating in the larynx, travel through the tissues surrounding the larynx and down and up the airways. Thus, they only partially exit into the external space through the mouth opening, and only part of the sound energy generated in the larynx ultimately reaches the listener's ear. Therefore, when talking about the human voice, it is necessary to take into account the propagation of sound not only inside the body, but also in the external space.
Tone sounds arise from periodic vibrations at a certain frequency. This periodicity gives rise to a sensation of height in the auditory organ. The noises are
non-periodic oscillations and therefore do not have a specific height.
The pitch of the sound is determined by the frequency of the oscillatory movements: the more often the periodic vibrations of the air occur, the higher the sound. The place where the high-pitched characteristics of sound originate is the larynx - the human vocal folds. The pitch of the tone depends on how many closings and openings the folds make during their oscillations and, accordingly, how many portions of condensed subglottic air they will let through. The pitch of the voice is determined by the size and tension of the vibrating body (vocal folds). It is easy to imagine that a thin string on a guitar or violin produces a high sound, and a large string produces a low sound. This explains the difference in the pitch of a child's and an adult's voice. The child's vocal folds are short and thin, which explains the high-pitched voice. During puberty, the length of the vocal folds increases, resulting in a decrease in pitch.
The distance between two adjacent waves is called the wavelength (L.B. Dmitriev et al., 1990). Oscillation frequency and wavelength are inversely proportional. Their product is always equal to 342 m/s, therefore, knowing the oscillation frequency, you can easily calculate the wavelength, and vice versa. Thus, wavelength reflects the same quality as frequency, i.e. pitch of sound. Long waves and rare vibrations are characteristic of low sounds, short waves and frequent vibrations are characteristic of high sounds.
Wavelengths are expressed in meters, and oscillation frequencies are expressed in the number of complete oscillations (periods) per second, the so-called hertz (Hz). By period we mean the time of complete oscillation. The lower the oscillation frequency, the longer the period of each oscillation.
Sound intensity, or sound pressure level, is measured in decibels (dB). There are two concepts: “intensity” - a characteristic of the level of sound pressure produced by the speaker, and “loudness” - the subjective perception of oscillatory movements, their summative amplitude by the person listening to the speech. Amplitude is the range of oscillatory motion, which does not depend on its frequency. During exhalation, the vocal folds come together, creating a barrier to the exhaled air, which sets them in motion, as a result of which they begin to vibrate. If you hit a piano string lightly with a hammer and then hit it hard, the pitch of the sound will remain stable, only the strength of the vibration of the string will change, i.e. the pushing force with which the string will press on the air particles surrounding it. The range of vibrations of air particles in this case will be significant, and the sound for us will be subjectively louder. The strength of the sound of the voice, as well as its pitch, increases with increasing subglottic pressure in the larynx. The greater the pressure with which portions of air break through the glottis, the higher the energy they carry, the greater the degree of condensation and subsequent rarefaction, i.e. the amplitude of vibration of air particles and, accordingly, their pressure on the eardrum are stronger. Increased subglottic pressure serves as the energy reservoir that feeds the resulting sound energy. However, only a small part of the subglottic pressure energy is converted into sound. In this case, the vocal folds play the role of a tap that periodically opens at a sound frequency, releasing portions of compressed air into the oropharyngeal canal. In addition, the muscles of the larynx, together with the muscles involved in exhalation, determine the increase in subglottic pressure. Ultimately, the acoustic energy of the sound of the larynx is the result of the work of the respiratory and laryngeal muscles. In the future, this sound energy is only wasted and never increases.
The strength of the sound waves resulting from vibrations of the vocal folds then quickly decreases. The efficiency of the vocal apparatus is very small. According to data provided by Husson, only 1/10-1/50 of the sound energy generated in the larynx exits the mouth and nasal cavity. This means that the main part of the energy is absorbed inside the body, causing vibration of the tissues of the head, neck, and chest.
Since the efficiency of the vocal apparatus is small, all mechanisms that can increase it become of great importance. In this regard, staging a voice presupposes the formation and development of its natural qualities.
The most difficult parameter of a voice is its timbre, or individual coloring. Musical tones, like most of the sounds around us, are complex tones, consisting of many vibrations of different frequencies and strengths. In a complex sound, there is a fundamental tone, which determines the pitch of the complex sound, and partial tones, or overtones, the sum of the sounds of which creates a completely individual timbre. Timbre is determined by the totality of the strength and pitch of the voice, tones and noises that arise during the process of phonation. The final shaping of the voice timbre occurs in resonators.
A resonator, from an acoustics point of view, is a cavity that has certain physical characteristics (L.B. Dmitriev et al., 1968, 1990). The pitch of the sound depends on the volume of air, the shape of the resonator and the size of the outlet; it is called the intrinsic height of the resonator. The smaller the volume of the resonator, the higher its own tone; The smaller the output hole, the lower the natural tone.
The human vocal apparatus has many cavities and tubes that provide resonance: trachea, bronchi; cavities of the larynx, pharynx, mouth, nasopharynx, nose, paranasal sinuses. Some of them are unchanged in shape and size in an adult (paranasal sinuses, nasal cavity), therefore, they always enhance the same overtones; others are mobile and easily change their shape and size (oral cavity, pharynx, supraglottic part of the larynx), due to which the original sound by resonator amplification of certain groups of overtones can vary widely.
Conventionally, resonators are distinguished: the upper one - ensures the purity and flight of the voice, the intelligibility of speech and the chest one - determines the power and strength of the sound.
Physiologists have proven through numerous studies that irritation of respiratory tract receptors by air flow affects the respiratory center, which regulates the breathing process, depth, and frequency of respiratory movements.
A prerequisite for the implementation of the phonation process is the preservation of physiological respiration. Respiratory movements (inhalation and exhalation) occur in strict sequence and are regulated by the respiratory center of the medulla oblongata (O.L. Badalyan, 1998).
A child's breathing changes as it develops. In a newborn, due to the perpendicular position of the ribs in relation to the spine, the chest is raised (the ribs cannot fall) and almost does not expand upon entry - only diaphragmatic breathing is effective. Subsequently, the ribs take on a saber shape, and the chest drops. By the age of 3-7 years, conditions for chest breathing are created. With the development of the shoulder girdle, chest breathing becomes dominant. But since a preschooler’s ribs are less inclined than those of an adult, his breathing is largely shallow.
A rapid respiratory pulse disrupts the rhythm and smoothness of pronunciation of words and phrases, which, in turn, leads to distortion of sounds.
Due to the slight excitability of the respiratory center and underdevelopment of nervous regulation, any physical stress and slight increase in temperature speed up the child’s breathing, disrupt its rhythm, and, consequently, increase the imperfection of speech. Finally, the inability of children to breathe with their mouth also introduces a certain disorganization into pronunciation - omissions of sounds, delays in their pronunciation, pronunciation while inhaling (A.N. Gvozdev, 1961; M.E. Khvattsev, 1997).
The following types of breathing are distinguished:
=> Superficial
=> Breast
=> Lower costal
Superficial clavicular (clavicular, upper thoracic) - respiratory excursions are accomplished by expanding and raising the upper part of the chest, and the diaphragm passively follows these movements, the stomach is drawn in when inhaling, and the upper part of the chest, collarbones, and sometimes shoulders rise noticeably.
Thoracic - inhalation is produced mainly due to the expansion and elevation of the lower part of the chest. It is not an independent type, since in this case the diaphragm is necessarily included in the work, and can only be considered an option.
Lower costal-diaphragmatic breathing, in which the chest and diaphragm are actively involved in the work, is the most physiological.
It has already been mentioned that normal voice formation is impossible without proper breathing technique.
=> soft - breathing and activation of the vocal folds occur simultaneously, which ensures both intonation accuracy and a calm, smooth, without push or aspiration, beginning of the sound, and its best timbre.
- In contact with 0
- Google+ 0
- OK 0
- Facebook 0