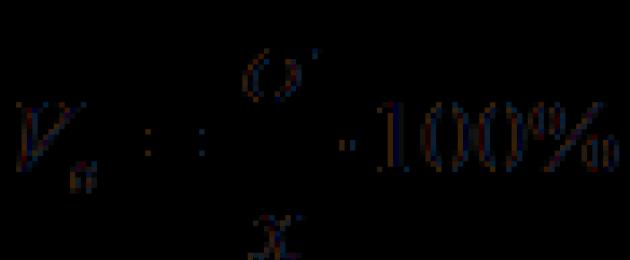
Ich elementy należą do różnych typów zjawisk.
Słownik terminów biznesowych. Akademik.ru. 2001.
Zobacz, co „zestaw heterogeniczny” znajduje się w innych słownikach:
niejednorodna populacja- (na przykład elektrownie jądrowe) [A.S. Goldberg. Angielsko-rosyjski słownik energii. 2006] Tematyka energii w ogóle EN populacja heterogeniczna... Przewodnik tłumacza technicznego
PAKIET, KTÓRY JEST JAKOŚCIOWO HETEROGENIZNY- zbiór statystyczny, którego jednostki (elementy) należą do różnych typów zjawisk. Jakościowo jednorodne i niejednorodne populacje charakteryzują się odpowiednio niskim lub bardzo dużym zróżnicowaniem wartości badanych cech, dla... ... Duży słownik ekonomiczny
Teoria eliminacji niewiadomych z układu algebraicznego. równania. Dokładniej, niech istnieje układ równań, w którym fi są wielomianami o współczynnikach z danego ciała P. Problem eliminacji niewiadomych x 1,..., x k z układu (1) (zadanie niejednorodne... ... Encyklopedia matematyczna
GOST 16887-71: Rozdzielanie ciekłych układów heterogenicznych metodami filtracji i wirowania. Warunki i definicje- Terminologia GOST 16887 71: Rozdzielanie ciekłych układów heterogenicznych metodami filtracji i wirowania. Terminy i definicje w dokumencie oryginalnym: 70. Strefa aktywna filtra Sekcja filtra ciągłego, w której... ...
GOST 18238-72: Mikrofalowe linie przesyłowe. Warunki i definicje- Terminologia GOST 18238 72: Mikrofalowe linie przesyłowe. Terminy i definicje w dokumencie oryginalnym: 19. Fala biegnąca Fala elektromagnetyczna określonego typu, która rozchodzi się w linii przesyłowej tylko w jednym kierunku Definicje... ... Słownik-podręcznik terminów dokumentacji normatywnej i technicznej
Ekonomia swiata- (Gospodarka światowa) Gospodarka światowa to zespół gospodarek narodowych połączonych różnego rodzaju powiązaniami. Powstanie i etapy rozwoju gospodarki światowej, jej struktura i formy, światowy kryzys gospodarczy oraz kierunki dalszego rozwoju... . .. Encyklopedia inwestorów
Zjawisko zachodzące, gdy fala dźwiękowa pada na powierzchnię styku dwóch ośrodków sprężystych i polega na powstaniu fal rozchodzących się z tej powierzchni do tego samego ośrodka... Encyklopedia fizyczna
Głaz- (Skała) Skała to zbiór minerałów, który w wyniku zjawisk naturalnych tworzy niezależne ciało w skorupie ziemskiej. Grupy skał, skały magmowe i metamorficzne, skały osadowe i metasomatyczne, struktura... ... Encyklopedia inwestorów
Ziemia (od wspólnego słowiańskiego dna ziemi, na dole), trzecia planeta w kolejności od Słońca w Układzie Słonecznym, znak astronomiczny Å lub, ♀. I. Wprowadzenie Ziemia zajmuje piąte miejsce pod względem wielkości i masy wśród dużych planet, ale należy do tzw. planet. grupa naziemna, w... ...
I Ziemia (ze wspólnego słowiańskiego dna ziemi, na dole) to trzecia planeta w kolejności od Słońca w Układzie Słonecznym, znak astronomiczny ⊕ lub, ♀. I. Wprowadzenie Z. zajmuje piąte miejsce pod względem wielkości i masy wśród dużych planet, ale wśród planet ... Wielka encyklopedia radziecka
Ocena jednorodności populacji
analiza aprioryczna statystyczny rozkład populacji
Do oceny jednorodności populacji stosuje się różne metody, takie jak: grupowanie, obliczanie wskaźników zmienności (rozproszenie, współczynnik zmienności), analiza obserwacji anomalnych w oparciu o statystyki - i q.
Na podstawie grupowania i jego graficznej reprezentacji (Rys. 1.1 - Rys. 1.9) można założyć, że szeregi rozkładów dla trzech cech nie są jednorodne. Ale jednocześnie należy pamiętać, że przy małej liczebności próby (n< 50) слишком углубленный анализ гистограммы может привести к неверным выводам, поскольку слабо выраженные «горбики и ямы» частот могут быть обусловлены не основными факторами, определяющими распределение единиц по группам, а просто случайными отклонениями вариантов от.
Po przeanalizowaniu obserwacji anomalnych w oparciu o statystyki ujawniane są wartości anomalne odpowiadające przedsiębiorstwu 13, a także anormalne wskaźniki przychodów i wydatków przedsiębiorstwa 9.
W tej pracy dalsza analiza zostanie przeprowadzona z uwzględnieniem anomalii spowodowanej obiektywnie istniejącymi przyczynami.
Przyczynami pojawienia się anomalnych obserwacji w agregacie mogą być:
1) zewnętrzne, powstałe w wyniku błędów technicznych;
2) wewnętrzne, obiektywnie istniejące.
Do dalszej analizy kształtu rozkładu wykorzystuje się wskaźniki zmienności. Wskaźniki zmienności dzielą się na bezwzględne i względne. Wartości bezwzględne obejmują zakres wahań, średnie odchylenie liniowe, rozproszenie, odchylenie standardowe i odchylenie kwartylowe. Współczynnik oscylacji, względne odchylenie liniowe, współczynnik zmienności i względna zmienność kwartylowa są wskaźnikami względnymi.
W ramach zajęć, aby scharakteryzować jednorodność populacji, obliczono takie wskaźniki jak rozproszenie, odchylenie standardowe i współczynnik zmienności.
Dyspersja to średni kwadrat odchyleń poszczególnych wartości cechy od wartości średniej. Dyspersja jest nie tylko główną miarą zmienności cechy, ale służy także do konstruowania wskaźników bliskości korelacji, przy ocenie wyników obserwacji próbnych itp.
Dla danych zgrupowanych oblicza się to ze wzoru (1.3):
gdzie x i jest i-tym wariantem uśrednianej cechy;
Średnia próbna lub średnia zbiorcza;
n i - częstotliwość, czyli liczba pokazująca, ile razy występują opcje z danego przedziału, lub waga i-tej opcji;
n to liczba obiektów w kolekcji.
Aby ocenić wpływ różnych czynników powodujących zmianę cechy, oblicza się wariancję dla każdego wskaźnika. W tym celu budowane są tabele obliczeniowe:
Tabela 1.5
Tabela obliczeniowa do obliczenia rozproszenia według kwoty przychodów ze sprzedaży towarów, produktów, robót, usług
|
Grupy przedsiębiorstw według przychodów ze sprzedaży, tysiące rubli. |
Liczba przedsiębiorstw n i |
Środek przedziału x i |
|||
Średnią próbkę oblicza się ze wzoru (1.4):
Stąd = 177166,1.
Tabela 1.5 pokazuje, że wartości atrybutów odbiegają od średniej próbki głównie w kierunku ujemnym.
Korzystając ze wzoru (1.3), znajduje się dyspersję, y 2 = 3422825485.
Tabela 1.6
Tabela obliczeniowa do obliczania rozproszenia według kosztu sprzedanych towarów, produktów, robót, usług
|
Grupy przedsiębiorstw według kosztu towarów, produktów, robót, sprzedanych usług, w tysiącach rubli. |
Liczba przedsiębiorstw n i |
Środek przedziału x i |
|||
y2 = 2096102493
Wartości kosztów na ogół nie przekraczają średniej próbki.
Tabela 1.7
Tabela kalkulacyjna do obliczania rozproszenia wydatków handlowych i administracyjnych
|
Grupy przedsiębiorstw według wysokości kosztów handlowych i administracyjnych, w tysiącach rubli. |
Liczba przedsiębiorstw n i |
Środek przedziału x i |
|||
y2 = 183131024,9
Z tabeli wynika, że wartości atrybutów odbiegają od średniej z próby również głównie w kierunku ujemnym.
Najczęściej stosowanym wskaźnikiem zmienności względnej jest współczynnik zmienności (wzór (1.5)):

Odchylenie standardowe y = 58504,92, czyli kwota przychodów różni się średnio o 58504,92 tys. Rubli.
Na tej podstawie współczynnik zmienności wynosi:
V w = (58504,92 / 177166,1) * 100% = 33%
Wartość Vw ocenia intensywność wahań opcji w stosunku do ich średniej wartości. Przyjęto następującą skalę oceny zmienności cechy:
0% < V в?40% - колеблемость незначительная;
40% < V в? 60% - колеблемость средняя (умеренная);
V w > 60% - znaczne wahania.
Dla rozkładów normalnych i zbliżonych do normalnych wskaźnik V in służy jako wskaźnik jednorodności populacji: ogólnie przyjmuje się, że jeśli nierówność jest spełniona
populacja jest ilościowo jednorodna pod względem tej cechy. Ponieważ współczynnik zmienności nie przekracza 33%, zbiór przedsiębiorstw można uznać za dość jednorodny pod względem przychodów.
Współczynnik zmienności dla pozostałych cech jest równy:
1) Dla grupy przedsiębiorstw według kosztu sprzedanych towarów, wyrobów, robót, usług V w = 33,4%. Zmienność jest niewielka.
2) Dla grupy przedsiębiorstw w zakresie kosztów handlowych i administracyjnych V = 32,7%. Zmienność jest niewielka. Populację można uznać za jednorodną.
Ponieważ współczynnik zmienności grupowania przedsiębiorstw według kosztów nieznacznie przekracza 33%, można powiedzieć, że populacja jest dość jednorodna, a nadmiar można wytłumaczyć małą liczebnością próby, anomalią niektórych wartości oraz wpływem czynniki zewnętrzne i wewnętrzne.
Sprawdź populację statystyczną pod kątem jednorodności, korzystając ze współczynnika zmienności opartego na wielkości produktów handlowych.
Zmienność - fluktuacja, zmiana wartości cechy w populacji statystycznej, tj. akceptacja przez jednostki populacji lub ich grupy różnych wartości cechy.
Współczynnik zmienności jest względną miarą zmienności i jest stosunkiem odchylenia standardowego do średniej wartości zmiennej charakterystyki, obliczanym według wzoru:
Odchylenie standardowe;
Średnia wartość cechy.
Odchylenie standardowe w ramach tego zadania oblicza się ze wzoru:

Im mniejszy jest współczynnik zmienności, tym bardziej jednorodna jest populacja statystyczna. Populację uważa się za jednorodną, jeśli współczynnik zmienności nie przekracza 33%.
Obliczmy współczynnik zmienności dla całego zbioru przedsiębiorstw na podstawie wielkości produkcji handlowej.
Obliczenia przedstawiono w tabeli 6.
Tabela 6.
| Numer firmowy | Q - x śr. | (Q - x średnia) 2 | |||
| 163,3 | -757,156 | 573285,208 | |||
| 236,5 | -683,956 | 467795,810 | |||
| 843,3 | -77,156 | 5953,048 | |||
| 1005,9 | 85,444 | 7300,677 | |||
| 696,3 | -224,156 | 50245,912 | |||
| 1031,3 | 110,844 | 12286,392 | |||
| 1361,2 | 440,744 | 194255,274 | |||
| 1712,9 | 792,444 | 627967,493 | |||
| 538,9 | -381,556 | 145584,981 | |||
| 350,4 | -570,056 | 324963,843 | |||
| 2149,9 | 1229,444 | 1511532,549 | |||
| 352,8 | -567,656 | 322233,334 | |||
| 1187,1 | 266,644 | 71099,023 | |||
| 262,4 | -658,056 | 433037,699 | |||
| 438,8 | -481,656 | 231992,502 | |||
| 1150,5 | 230,044 | 52920,242 | |||
| 249,4 | -671,056 | 450316,155 | |||
| 655,3 | -265,156 | 70307,704 | |||
| 2549,5 | 1629,044 | 2653784,354 | |||
| 536,8 | -383,656 | 147191,926 | |||
| 311,2 | -609,256 | 371192,874 | |||
| 809,7 | -110,756 | 12266,892 | |||
| 166,7 | -753,756 | 568148,108 | |||
| 2185,1 | 1264,644 | 1599324,447 | |||
| 2066,2 | 1145,744 | 1312729,314 | |||
| Całkowity: | 12217715,762 | ||||
| 920,456 | |||||
| 488708,630 | |||||
| 699,077 | |||||
| Współczynnik zmienności | 0,759 | ||||
Z tabeli widzimy, że współczynnik zmienności wynosi 48,7%. Oznacza to, że populacja jest niejednorodna, ponieważ populację uważa się za jednorodną, jeśli współczynnik zmienności nie przekracza 33%.
Obliczmy współczynnik zmienności dla wielkości atrybutu produktów rynkowych, otrzymany w wyniku prostego grupowania (pkt 3.1.).
Wyniki obliczeń przedstawiono w tabelach 7,8,9 i 10.
Tabela 7.1 grupa.
| Numer firmowy | Wolumen produktów komercyjnych (Q), miliony rubli | Q - x śr. | (Q - x średnia) 2 | ||
| 163,3 | -218,146 | 47587,744 | |||
| 236,5 | -144,946 | 21009,388 | |||
| 696,3 | 314,854 | 99132,944 | |||
| 538,9 | 157,454 | 24791,714 | |||
| 350,4 | -31,046 | 963,864 | |||
| 352,8 | -28,646 | 820,602 | |||
| 262,4 | -119,046 | 14171,987 | |||
| 438,8 | 57,354 | 3289,464 | |||
| 249,4 | -132,046 | 17436,187 | |||
| 655,3 | 273,854 | 74995,929 | |||
| 536,8 | 155,354 | 24134,818 | |||
| 311,2 | -70,246 | 4934,522 | |||
| 166,7 | -214,746 | 46115,911 | |||
| Całkowity: | 0,000 | 379385,072 | |||
| 381,446 | |||||
| 34489,552 | |||||
| 185,714 | |||||
| Współczynnik zmienności | 0,487 | ||||
Tabela 8.2 grupa.
| Numer firmowy | Wolumen produktów komercyjnych (Q), miliony rubli | Q - x śr. | (Q - x średnia) 2 | ||
| 843,3 | -161,333 | 26028,44 | |||
| 1005,9 | 1,266667 | 1,604444 | |||
| 1031,3 | 26,66667 | 711,1111 | |||
| 1187,1 | 182,4667 | 33294,08 | |||
| 1150,5 | 145,8667 | 21277,08 | |||
| 809,7 | -194,933 | ||||
| Całkowity: | 119311,3 | ||||
| 1004,633 | |||||
| 19885,222 | |||||
| 141,015 | |||||
| Współczynnik zmienności | 0,140 | ||||
Grupa Tabela 9.3,
| Numer firmowy | Wolumen produktów komercyjnych (Q), miliony rubli | Q - x śr. | (Q - x średnia) 2 | ||
| 1361,2 | -175,850 | 30923,223 | |||
| 1712,9 | 175,850 | 30923,223 | |||
| Całkowity: | 61846,445 | ||||
| 1537,050 | |||||
| 20615,482 | |||||
| 143,581 | |||||
| Współczynnik zmienności | 0,093 | ||||
Tabela 10. Grupa 4.
| Numer firmowy | Wolumen produktów komercyjnych (Q), miliony rubli | Q - x śr. | (Q - x średnia) 2 | ||
| 2149,9 | -87,775 | 7704,451 | |||
| 2549,5 | 311,825 | 97234,83 | |||
| 2185,1 | -52,575 | 2764,131 | |||
| 2066,2 | -171,475 | 29403,68 | |||
| Całkowity: | 137107,1 | ||||
| 2237,675 | |||||
| 68553,544 | |||||
| 261,827 | |||||
| Współczynnik zmienności | 0,117 | ||||
Wnioski z danych:
W grupie 1 współczynnik zmienności wynosi 48,7%. Oznacza to, że populacja nie jest jednorodna.
W grupie 2 współczynnik zmienności wynosi 14%. Oznacza to, że populacja jest jednorodna.
W grupie 3 współczynnik zmienności wynosi 9,3%. Oznacza to, że populacja jest jednorodna.
W grupie 4 współczynnik zmienności wynosi 11,7%. Oznacza to, że populacja jest jednorodna.
Wykład 1.3
ANALIZA DANYCH BADAWCZYCH
Kluczowe punkty analizy eksploracyjnej
Slajd 2
Celem analizy eksploracyjnej jest przedstawienie zaobserwowanych danych w zwartej i prostej formie, umożliwiającej identyfikację występujących w nich prawidłowości i powiązań. Analiza eksploracyjna obejmuje transformację danych i metody ich wizualizacji, identyfikację wartości anomalnych, przybliżoną ocenę rodzaju rozkładu i wygładzanie.
Termin analiza eksploracyjna jest również używany w szerszym znaczeniu niż wstępne przetwarzanie danych. Przykładowo w procedurach wielowymiarowych takich jak analiza czynnikowa, wielowymiarowe skalowanie danych celem analizy eksploracyjnej, oprócz analizy danych pierwotnych, jest określenie minimalnej liczby czynników, które w zadowalający sposób odtwarzają macierz kowariancji (korelacji) lub macierz bliskości obserwowanych zmiennych
Slajd 3
Zgodnie z poprzednim wykładem wierzymy, że badacz ma obserwacje w postaci macierzy „cecha obiektu” lub wektora cech i częściowego lub całkowitego braku informacji apriorycznej o mechanizmie przyczynowo-skutkowym tych danych. Podczas analizy zwykle pojawiają się następujące pytania:
1. Jakiemu przetwarzaniu należy poddać obserwacje?
2. Który model wybrać?
3. Jakie wnioski można wyciągnąć?
Aby wybrać metodę przetwarzania, wymagany jest model obserwowanych danych. Przed dokonaniem obserwacji należy wskazać charakter i właściwości mierzonej wielkości, tj. skorzystaj z informacji apriorycznych. Im pełniejsze informacje aprioryczne, tym dokładniejsze i mniejszym kosztem można uzyskać niezbędne wyniki. Dlatego ogromne znaczenie ma sformalizowanie metod gromadzenia, przetwarzania i wykorzystywania informacji apriorycznych. Na podstawie analizy tych informacji budowany jest model badanego zjawiska, dobierany jest sprzęt i opracowywana jest metodyka przeprowadzenia eksperymentu.
Slajd 4
Aby uzyskać pełniejszą informację o badanym zjawisku, przeprowadza się analizę danych pierwotnych, tzw Analiza danych rozpoznawczych. Analiza eksploracyjna jest konieczna we wszystkich przypadkach, z wyjątkiem bardzo prostych problemów. Przykładowo, dobór rodziny modeli badanego zjawiska w większości przypadków powinien być poprzedzony wstępną i graficzną analizą danych. Aby to zilustrować, rozważmy prosty jednoczynnikowy model regresji liniowej. Zgodnie z tym modelem zakłada się, że obserwacje N para ( X 1 ,Y 1), …, (x n, Y n) można opisać równaniem
Jako minimalną analizę wstępną można rozważyć wykres punktowy ( x j,Yj). W wyniku analizy wykresów można stwierdzić, że dyspersja jest stała Y ja, o celowości przekształcania zmiennych, w celu zidentyfikowania obecności obserwacji anomalnych, których wykluczenie wymaga specjalnych badań. Po takim przetworzeniu danych, zakładając, że model (1) jest poprawny, należy oszacować parametry b 0, b 1 i przeprowadzić graficzną analizę reszt pomiędzy wartościami zaobserwowanymi i oszacowanymi Y ja. Na podstawie tej analizy można potwierdzić lub zaproponować inny model.
Slajd 5
Rozważmy najprostsze procedury analizy eksploracyjnej związane z wstępne przetwarzanie danych. Uzupełniają one metody zarysowane w pierwszym wykładzie przy rozważaniu konkretnych form prezentacji danych. Wyjaśnijmy potrzebę analizy eksploracyjnej w odniesieniu do konkretnych zagadnień oceniania.
Oszacowanie średniej. Rozważmy najprostszy przykład oszacowania prawdziwej średniej M niezależna zmienna losowa X według próbki objętościowej N. Jeśli obliczona zostanie estymacja średniej, pojawia się pytanie: „Jak bardzo szacunkowa różnica różni się od niezaobserwowanej wartości prawdziwej?” Od prawdziwego znaczenia M nie jest dostępna, wówczas wyznacza się przedział ufności, który z zadanym prawdopodobieństwem obejmuje wartość prawdziwą.
Związek ma T- Dystrybucja studencka. Bardzo często konstruuje się 95% przedziały ufności, zakładając, że jest to wartość T normalnie dystrybuowane. W przypadku rozkładu normalnego wartość T będzie wynosić 1,96, natomiast dla T- rozkłady według liczby stopni swobody w (w = N– 1), równy 1; 3 i 12, wielkość T odpowiednio wynosi 12,7; 4.3 i 2.18. Dlatego dla małych próbek zamiast tego użyj rozkładu normalnego T- rozkład prowadzi do dużych błędów w oszacowaniu przedziału. Duża różnica w szacunkach przedziałowych wynika z różnicy T- rozkład od normalnego w ogonach dystrybucji.
Slajd 6
Ogony rozkładów rzeczywistych mają z reguły większy rozrzut niż ogony rozkładu normalnego. Charakter różnicy między rozkładem rzeczywistym a rozkładem normalnym może być inny:
1. Większość pomiarów dokonywana jest w określonych jednostkach, takich jak miligramy, mikrony, a ich wartości są ograniczone. W przypadku prawa dystrybucji normalnej wartości wahają się od – ¥ do + ¥.
2. Ostra asymetria niektórych rozkładów (na przykład c 2, F) w przypadku małych próbek krawędzie równomiernego rozkładu są ostre.
3. Zachowanie na „ogonach” dystrybucji. Jedna lub więcej wartości odstających z większości obserwacji może znacząco zmienić średnią i katastrofalnie zmienić wariancję. Nieprawdopodobne wartości są prawie nieuniknione w danych eksperymentalnych. Liczba takich wartości w danych medycznych sięga nawet 30%, a w specjalnie zaprojektowanych eksperymentach stanowi około 1% wszystkich danych.
Oszacowanie średniej metodą średniej arytmetycznej ma ogromne zalety: bezstronność dla populacji ogólnych, które mają matematyczne oczekiwanie, wystarczalność, kompletność i odpowiednio pełną wydajność dla rozkładów normalnych, Poissona, gamma oraz, w wystarczająco szerokich warunkach, wygodnego asymptotycznie normalnego rozkładu, co w wielu przypadkach zostało już w przybliżeniu osiągnięte przy średniej wielkości próbek N. Takie oszacowanie ma również wady: jego skuteczność wynosi zero dla równomiernego rozkładu, a w przypadku niektórych próbek tylko jedna nieprawdopodobnie duża obserwacja może sprawić, że oszacowanie średniej arytmetycznej stanie się bezużyteczne.
Slajd 7
Jeśli normalność rozkładu zostanie naruszona przez dane odstające, zaleca się użycie solidny(solidny – mocny, zdrowy, tęgi) oceny. Przykładem solidnego oszacowania średniej tolerującego odchylenia ogonów rozkładu od normy jest: mediana dystrybucje. To, podobnie jak mediana wartości obserwacji, nie zależy od jednego lub kilku nieprawdopodobnie dużych wymiarów.
Mediana, jako solidna, nie jest efektywnym oszacowaniem w stosunku do średniej arytmetycznej oszacowania dla rozkładu normalnego.
Slajd 8
Miara rozproszenia. W praktyce do charakteryzowania wielkości rozproszenia danych stosuje się następujące miary: odchylenie standardowe s lub jego kwadrat - dyspersja s 2 oraz rozstęp R. Oszacowania tych wielkości są odpowiednio oznaczane S, S 2 , R. Oszacowanie rozproszenia według S szeroko stosowane i przydatne do transformacji liniowych, takich jak Y= b + a X. Dla niektórych rozkładów s 2 = ∞ i zakres ma zastosowanie; nieprawdopodobnie duże odchylenia w obserwacjach mogą również spowodować, że oszacowanie wariancji będzie bardzo duże, co spowoduje, że typ rozkładu będzie inny niż prawdziwy.
Oszacowanie rozrzutu według zakresu próbki jest szybką procedurą. W związku z pojawieniem się szybkich komputerów, zalety obliczeń R w porównaniu z S stają się coraz mniej istotne, ale zalety związane z łatwością obliczeń pozostają R oraz możliwość stosowania tych statystyk przez osoby niebędące specjalistami. Zatem zakres został prawie całkowicie wyparty S z systemów kontroli jakości, w których pobierane są małe próbki w krótkich odstępach czasu, a karty kontrolne konstruowane są w oparciu o wartości średnie i zakresy.
Należy zauważyć, że zakres ten można wykorzystać do rozpoznania dużych, nieprawdopodobnych błędów w obliczeniach S dla próbek z dowolnej populacji. Wynika to z ograniczonej relacji S/R.
Slajd 9
Podsumowując omówione oceny, należy stwierdzić, że istnieją powody, aby nie traktować wszystkich danych jednakowo. Przed przystąpieniem do przetwarzania obserwacji należy sprawdzić jednorodność próbki, a jeśli jest ona niejednorodna, podzielić ją na warstwy. Obecność obserwacji odstających również narusza jednorodność próbki. W tym przypadku jedno podejście opiera się na wykrywaniu i usuwaniu tych wartości odstających.
Usunięcie wartości odstających zapewnia bezpieczeństwo oszacowania, ale jest skuteczne tylko wtedy, gdy istnieje wyraźna granica między danymi usuniętymi i nieusuniętymi. Obok danych oczywistych wyraźnie wyróżnia się strefa danych „wątpliwych” (ryc. 1), których nie zawsze można rozpoznać. Tutaj łatwo jest pozwolić na nieprawidłowe usunięcia i nieuzasadnione zapisy; pełnej efektywności nie można oczekiwać nawet w idealnym przypadku po usunięciu. Trudności te można przezwyciężyć, stosując solidne metody estymacji. Solidne algorytmy zapewniają bezpieczne i wydajne szacowanie w obecności wartości odstających i wątpliwych danych.

Ryż. 1. Gęstość dystrybucji. Podział danych na trzy grupy.
Slajd 10
O jakości wyników Celem badania jest odpowiedź na pytanie: czy wyniki można zastosować w praktyce. Przydatność uzyskanych wyników można ocenić za pomocą metod kontroli krzyżowej. Najczęściej stosowane metody to proste i podwójne sprawdzanie krzyżowe.
Prosta podwójna kontrola. Powstały model testowany jest na danych innych niż te, z których obliczono parametry modelu. W tym przypadku próbkę obserwacji można podzielić na dwie (lub więcej) części. Jedna część służy do przetwarzania, a druga do testowania. Części można wówczas zamieniać miejscami, co może dostarczyć nieco więcej informacji, chociaż istnieją pewne trudności wynikające z powiązania obu ocen jakości modelu.
Takie podwójne sprawdzenie można przeprowadzić także dla wielokrotnych podziałów danych, np. próbkę można podzielić na 10 równych części. Na dowolnych 9 z nich oceń model, a na pozostałej części przeprowadź weryfikację. Następnie powtórz procedurę 9 razy, za każdym razem biorąc nowe 9 części. W niektórych przypadkach procedura jest skomplikowana. Obliczenia przeprowadza się na wszystkich danych bez jednej obserwacji, a weryfikację przeprowadza się na wartości odrzuconej. Obliczenia powtarza się dla każdej z przykładowych obserwacji. Nie dajcie się zwieść wynikom prostego testu, gdyż próbka kontrolna zawsze będzie bardziej podobna do próbki roboczej niż do próbki obiektów, dla których zostaną wykorzystane wyniki badań.
Podwójne sprawdzenie. Test przeprowadzany jest na danych innych niż te, na których zbudowano model, oraz te, które posłużyły do obliczenia parametrów modelu. Lekarze nazywają tę metodę badania „podwójnie ślepą próbą”. „Świeże dane” do kontroli krzyżowej można zebrać po wybraniu modelu i obliczeniu parametrów. Jeżeli uzyskanie takich danych nie jest możliwe, można sięgnąć po dane archiwalne, pod warunkiem, że w trakcie budowy modelu i obliczania parametrów tego modelu nie były one znane. Podczas podwójnej kontroli ważne jest, aby dane użyte do weryfikacji różniły się od tych, na podstawie których dokonano oceny. Możesz wykorzystać dane z różnych lat, jeśli można je przypisać do tego samego czasu, lub dane od innych badaczy.
Slajd 11
Próbki heterogeniczne
Standardowe metody szacowania dowolnych statystyk danych próbnych opierają się na założeniu, że próbka pochodzi z populacji jednorodnej o prostej strukturze prawa dystrybucji. Tymczasem w praktyce próbki często powstają pod wpływem różnych przyczyn i warunków i można je przedstawić jako kombinację pewnego zbioru jednorodnych próbek, z których każda ma prostą budowę. Na przykład dochodów bogatych i innych obywateli państwa nie można uznać za jednorodne, ponieważ mają oni różne podstawy ekonomiczne; przedmioty o różnej wartości, różniące się konsekwencjami gospodarczymi. Przykłady obejmują niejednorodne sekwencje modeli dynamicznych w problemach analizy drgań w inżynierii mechanicznej; sejsmogramy w geofizyce; kardiogramy z zaburzeniami rytmu serca.
Charakter heterogeniczności może być inny. Na przykład możliwe jest łączenie populacji o różnych średnich i wariancjach lub z tymi samymi średnimi, ale różnymi wariancjami. Ważną klasę próbek heterogenicznych stanowią również próbki zawierające jeden lub więcej niewiarygodnie duże lub małe wymiary. Przetwarzanie heterogeniczne
Niech obserwacje składają się z trzech jednorodnych warstw, z których każdą można opisać prostą regresją jednowymiarową. Zależności te pokazane są na rys. 2, gdzie linie proste są liniami regresji każdej populacji. Jeśli przetworzymy połączoną próbkę tych populacji, otrzymamy zależność regresji pokazaną na ryc. 2 linia przerywana. Oczywiście regresja na zbiorczych danych nie ma sensu.
Aby określić jednorodność próby, wymagana jest szczegółowa analiza zawartości badanej populacji. Analiza ta powinna opierać się na istotnej cesze nielosowej, zgodnie z którą populację pierwotną można przedstawić jako sumę kilku populacji jednorodnych. Na przykład zeznania podatkowe można podzielić na grupy ze względu na dochód; instytucje – według liczby pracowników; gospodarstwa rolne – według powierzchni gruntów ogółem i dochodu brutto. Dzieląc próbkę na warstwy, należy odpowiedzieć na pytania, na jakiej podstawie lepiej przeprowadzić stratyfikację, jak wyznaczyć granice między warstwami, ile warstw powinno być.
Slajd 12
Podział populacji heterogenicznej na jednorodną
Niech próba badanej populacji x 1, ..., x n będzie zawierać elementy dwóch niezależnych zmiennych losowych o gęstościach rozkładu f(x,q 1) i f(x,q 2). Oznaczmy przez A zbiór elementów próby należących do pierwszej zmiennej losowej, B zbiór elementów próby z drugiej populacji. Należy znaleźć estymaty 1, 2 nieznanych parametrów q 1, q 2 oraz zbiorów A i B. Do estymacji tych czterech niewiadomych stosujemy metodę największej wiarygodności. Niewiadome q 1, q 2 oraz A i B znajdujemy z warunku maksymalizacji współrzędnych funkcji wiarygodności
W każdym kroku maksymalizowana jest wartość funkcji wiarygodności dla jednej z niewiadomych. 1) < f(x i , 2),. Если f(x i , 1) = f(x i , 2), то оба варианта одинаково правдоподобны, что для непрерывных распределений является маловероятным событием. Далее берем следующий элемент и относим его в то или иное множество. Полученные множества сравниваем с множествами на предыдущем шаге. Если они отличаются, то переходим к шагу 2, в противном случае алгоритм останавливается, и задача считается решенной.
Wadą algorytmu jest to, że zatrzymuje się na pierwszym lokalnym maksimum funkcji wiarygodności. Tej wady można częściowo uniknąć rozwiązując problem dla różnych początkowych podziałów na podzbiory A i B. Jeżeli końcowe wyniki dla kilku warunków początkowych są różne, wówczas przyjmowane jest rozwiązanie, dla którego wartość funkcji wiarygodności jest większa. Wynika z tego, że powyższy algorytm można zastosować także dla próbek zawierających więcej niż dwie warstwy.
Przedmiotem badań statystycznych są agregaty statystyczne składające się z poszczególnych jednostek charakteryzujących się różnymi cechami. W wyniku przeprowadzonych badań identyfikowane są wzorce statystyczne w oparciu o wykorzystanie modeli zjawisk społeczno-gospodarczych oraz metod przetwarzania i analizy informacji ekonomicznych i statystycznych.
Populacja statystyczna to zbiór obiektów, zjawisk, połączonych pewnymi wspólnymi cechami (znakami) i podlegający badaniom statystycznym. Na przykład całość przedsiębiorstw przemysłowych w danym kraju. Poszczególne obiekty zjawiska tworzące agregat statystyczny, zwane jednostkami agregatu, posiadające pewne wspólne cechy, mogą różnić się od siebie innymi cechami. Dlatego populacje mogą być jednorodne (jakościowo jednorodne) i heterogeniczne (jakościowo heterogeniczne).
W populacji jednorodnej obiekty (jednostki populacji) są do siebie podobne pod względem cech istotnych dla danego badania i należą do tego samego rodzaju zjawiska. Populacja jednorodna, będąca jednorodna pod pewnymi względami, może być niejednorodna pod innymi.
Elementy (jednostki) heterogenicznej populacji odnoszą się do różnych typów badanych zjawisk. W przypadku populacji heterogenicznej obliczanie cech uogólniających, zwłaszcza w postaci wartości średniej, jest niezgodne z prawem. Stosując metodę grupowania i metodę taksonomii, w heterogenicznej populacji można tworzyć jednorodne grupy.
Cały zbiór naprawdę istniejących obiektów charakteryzujących dowolne zjawisko nazywa się ogólnym. Do badań statystycznych można wybrać zbiór jednostek z populacji ogólnej według określonych zasad, które tworzą populację próbną.
Każda jednostka kruszywa charakteryzuje się różnymi cechami - cechami charakterystycznymi, właściwościami, jakością.
Cecha zmienna to cecha, która przyjmuje różne wartości w obrębie populacji statystycznej dla jednostek populacji statystycznej. Nie wyklucza to jednak powtórzeń poszczególnych wartości (wariantów) cechy; kilka jednostek populacji może mieć te same wartości cechy. Przykładem zmiennej charakterystyki jest wysokość miesięcznych wynagrodzeń pracowników w przedsiębiorstwie.
Znak jakościowy (atrybutywny) to znak, którego indywidualne znaczenia wyrażają się w postaci pojęć i nazw. Np. zawód pracownika (monter, monter), poziom wykształcenia (podstawowe, średnie, wyższe).
Cecha ilościowa to cecha, której poszczególne wartości mają wyraz ilościowy (na przykład koszt produkcji dla różnych przedsiębiorstw w tej samej branży).
Atrybut efektywny to atrybut zależny, czyli taki, który zmienia swoją wartość pod wpływem innego, skojarzonego z nim atrybutu czynnikowego.
Cecha czynnikowa (czynnik) to cecha, która wpływa na inną powiązaną z nią cechę efektywną i powoduje jej zmianę (odmianę). Rola tych cech w różnych zadaniach może się zmieniać; w jednym zadaniu pełni rolę czynnika, w innym - wypadkową. Przykładowo wydajność pracy pełni rolę czynnika zmiany (obniżenia) kosztu jednostki produkcji, a jednocześnie produktywność pracy w powiązaniu z kwalifikacjami pracownika jest cechą efektywną.
W wyniku badań statystycznych ustala się wzór statystyczny, który jest uważany za ilościowy wzór zmian w przestrzeni i czasie w zjawiskach masowych i procesach życia społecznego, składający się z wielu elementów (jednostek całości). Jest charakterystyczna nie dla poszczególnych jednostek agregatu, ale dla całego agregatu jako całości. Z tego powodu prawidłowość charakterystyczna dla tego zjawiska (procesu) pojawia się dopiero przy odpowiednio dużej liczbie obserwacji i tylko średnio. Jest to zatem przeciętny wzór zjawisk i procesów masowych. W dużej liczbie obserwacji pojedyncze odchylenia od średniej w tym czy innym kierunku, spowodowane przyczynami losowymi, znoszą się wzajemnie i pojawia się wzór. Łączy to wzór statystyczny z prawem wielkich liczb. W miarę zwiększania się czasoprzestrzennych odstępów rozwoju zjawiska, jego wzór staje się coraz bardziej stabilny.
Zatem znając wzór statystyczny konkretnego zjawiska masowego, można z pewnym prawdopodobieństwem przewidzieć jego dalszy rozwój i określić wartość badanej cechy (wskaźnika). Należy jednak wziąć pod uwagę, że istotne zmiany warunków istnienia tego zjawiska mogą prowadzić do znacznych zmian w sile tej zależności.
W statystyce społeczno-ekonomicznej prawo wielkich liczb jest ogólną zasadą, dzięki której wzorce ilościowe właściwe masowym zjawiskom społecznym ujawniają się wyraźnie dopiero w wystarczająco dużej liczbie obserwacji. Prawo wielkich liczb jest generowane przez szczególne właściwości masowych zjawisk społecznych. Ci drudzy ze względu na swoją odrębność z jednej strony różnią się od siebie, a z drugiej mają ze sobą coś wspólnego ze względu na przynależność do określonego gatunku, klasy, czy określonych grup. Pojedyncze zjawiska są bardziej podatne na wpływ czynników przypadkowych i nieistotnych niż masa jako całość. W dużej liczbie obserwacji przypadkowe odchylenia w przeciwnych kierunkach od wzorców są kasowane. W wyniku wzajemnego znoszenia się odchyleń losowych, średnie obliczone dla wartości tego samego typu stają się typowe, odzwierciedlające działanie czynników stałych i znaczących w danych warunkach miejsca i czasu. Trendy i wzorce ujawnione za pomocą prawa wielkich liczb to ogromne trendy statystyczne.
Badania statystyczne zjawisk społeczno-gospodarczych prowadzone są różnymi metodami, wykorzystując modele tych zjawisk.
Model to reprezentacja, analogia zjawiska lub procesu w jego podstawowych cechach, które są istotne dla celów badania. Proces tworzenia modelu nazywa się modelowaniem. Model musi uwzględniać wszystkie istotne zależności, wzorce i warunki rozwoju w taki sposób, aby na jego podstawie można było przeprowadzić eksperymenty, których celem jest określenie „zachowania” modelowanego obiektu w różnych możliwych (często nieobserwowalnych w rzeczywistości) warunków. Zjawiska i procesy gospodarcze symulowane są za pomocą modeli ekonomicznych i matematycznych.
Model ekonomiczno-matematyczny to opis zjawiska lub procesu gospodarczego za pomocą jednego lub większej liczby wyrażeń matematycznych (równania, funkcje, nierówności, tożsamości). Wyrażenia matematyczne charakteryzują najważniejsze zależności między zjawiskami i procesami, warunki i wzorce ich rozwoju, ograniczenia, wymagania itp. Model ekonomiczno-matematyczny stanowi uogólnienie istotnych informacji jakościowych i ilościowych o przedmiocie analizy i służy jako podstawa do przeprowadzania eksperymentów obliczeniowych, które pozwalają uzyskać różne cechy i parametry badanego obiektu dla danych warunków jego rozwoju. Rozwój i zastosowanie modeli ekonomicznych i matematycznych znacznie poszerza możliwości analizy ekonomicznej. Główne zalety stosowania modeli ekonomicznych i matematycznych są następujące:
Jednoczesne uwzględnienie w modelu dużej liczby wymagań, warunków i założeń oraz wystarczająca swoboda rewizji tych warunków podczas pracy z modelem;
Spójność (zgodność) układu wskaźników uzyskanych z modelu;
Możliwość uzyskania opcji zachowania badanego zjawiska dla szerokiego zakresu i kombinacji warunków początkowych i założeń (np. opcji prognozowania rozwoju gospodarczego).
Modele ekonomiczno-matematyczne dzielimy ze względu na ich przeznaczenie na modele teoretyczno-ekonomiczne i stosowane. Wiele stosowanych modeli to modele ekonomiczno-statystyczne lub zawierają te ostatnie jako komponenty.
Modele teoretyczno-ekonomiczne to modele ekonomiczno-matematyczne przeznaczone do jakościowej analizy systemów, procesów i zjawisk gospodarczych. Wartości parametrów, a nawet postać funkcjonalna zależności wchodzących w skład modelu teoretyczno-ekonomicznego zwykle nie są określone. Wnioski, jakie uzyskuje się za pomocą tych modeli, mają zazwyczaj charakter ogólny. Typowym przykładem jest wniosek o stabilności (niestabilności) badanego systemu gospodarczego, jeśli jego parametry spełniają określone wymagania, o istnieniu (braku) rozwiązań zrównoważonych lub optymalnych. Modele teoretyczno-ekonomiczne są szeroko stosowane w teoretycznych badaniach ekonomicznych. Obecnie konstrukcja i badanie modeli teoretyczno-ekonomicznych jest przedmiotem ekonomii matematycznej. Do ich badania wykorzystuje się rozwiniętą aparaturę matematyczną (teorię równań różniczkowych, teorię macierzy, metody optymalizacji i teorii gier itp.).
Model ekonomiczno-statystyczny to układ zależności matematycznych opisujący pewien obiekt, proces lub zjawisko gospodarcze, którego parametry są wyznaczane (szacowane) na podstawie rzeczywistych danych z wykorzystaniem danych statystycznych (w odróżnieniu od modelu teoretyczno-ekonomicznego). . O strukturze i specyficznym typie modelu ekonomiczno-statystycznego decyduje specyfika modelowanego obiektu, koncepcje teoretyczne badacza, cele badań, dostępność informacji oraz stosowane metody przetwarzania danych. Proces budowy modelu dzieli się na dwa powiązane ze sobą etapy: określenie ogólnej postaci zależności pomiędzy modelem a zawartymi w nim zmiennymi oraz statystyczne oszacowanie wartości parametrów na podstawie danych obserwacyjnych. Do najczęściej stosowanych ekonomicznych modeli statystycznych należą trendy, modele szeregów czasowych, izolowane równania regresji i modele ekonometryczne. Modele ekonomiczno-statystyczne znajdują szerokie zastosowanie w planowaniu i analizie systemów gospodarczych, badaniu ich reakcji na zmiany zewnętrznych i wewnętrznych warunków funkcjonowania, a także w prognozowaniu i określaniu różnych opcji przyszłego rozwoju.
Do oszacowania parametrów modelu ekonometrycznego potrzebne są specjalne metody estymacji symultanicznej (wykazano, że zwykła metoda najmniejszych kwadratów, stosowana do każdego równania modelu ekonometrycznego z osobna, prowadzi do niespójnych szacunków). Najczęściej stosowanymi metodami jednoczesnej estymacji modelu ekonometrycznego są dwuetapowa i trójstopniowa metoda najmniejszych kwadratów.
- W kontakcie z 0
- Google+ 0
- OK 0
- Facebook 0