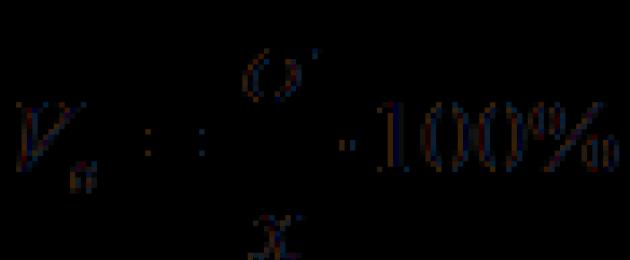
De element som tillhör olika typer av fenomen.
Ordbok över affärstermer. Akademik.ru. 2001.
Se vad "Heterogen Set" är i andra ordböcker:
heterogen befolkning- (till exempel kärnkraftverk) [A.S. Goldberg. Engelsk-rysk energiordbok. 2006] Ämnen om energi i allmänhet EN heterogen befolkning ... Teknisk översättarguide
ETT PAKET SOM ÄR KVALITATIVT HETEROGEN- en statistisk uppsättning vars enheter (element) tillhör olika typer av fenomen. Kvalitativt homogena och heterogena populationer kännetecknas av låg respektive mycket stor variation i värdena på de egenskaper som studeras, för... ... Stor ekonomisk ordbok
Teorin om att eliminera okända från ett algebraiskt system. ekvationer. Mer exakt, låt det finnas ett ekvationssystem där fi är polynom med koefficienter från ett givet fält P. Problemet med att eliminera de okända x 1,..., x k från system (1) (inhomogent problem... ... Matematisk uppslagsverk
GOST 16887-71: Separation av flytande heterogena system genom filtrering och centrifugeringsmetoder. Termer och definitioner- Terminologi GOST 16887 71: Separation av flytande heterogena system genom filtrering och centrifugeringsmetoder. Termer och definitioner originaldokument: 70. Filter aktiv zon Den del av det kontinuerliga filtret där... ...
GOST 18238-72: Mikrovågsöverföringsledningar. Termer och definitioner- Terminologi GOST 18238 72: Mikrovågsöverföringsledningar. Termer och definitioner originaldokument: 19. Vandringsvåg En elektromagnetisk våg av en viss typ som utbreder sig i en transmissionsledning i endast en riktning Definitioner... ... Ordboksuppslagsbok med termer för normativ och teknisk dokumentation
Världsekonomin- (Världsekonomi) Världsekonomin är en uppsättning nationella ekonomier som förenas av olika typer av kopplingar. Världsekonomins bildande och utvecklingsstadier, dess struktur och former, den globala ekonomiska krisen och trender i vidare utveckling... . .. Investor Encyclopedia
Ett fenomen som uppstår när en ljudvåg faller på gränsytan mellan två elastiska medier och består av bildning av vågor som fortplantar sig från gränssnittet till samma medium... Fysisk uppslagsverk
Sten- (Sten) En bergart är en samling mineraler som bildar en oberoende kropp i jordskorpan, som ett resultat av naturfenomen. Grupper av bergarter, magmatiska och metamorfa bergarter, sedimentära och metasomatiska bergarter, struktur... ... Investor Encyclopedia
Jorden (från det vanliga slaviska jordgolvet, botten), den tredje planeten i ordning från solen i solsystemet, astronomiskt tecken Å eller, ♀. I. Inledning Jorden ligger på femte plats i storlek och massa bland de stora planeterna, men bland de så kallade planeterna. markbunden grupp, i... ...
I Earth (från det vanliga slaviska jordgolvet, botten) är den tredje planeten i ordningen från solen i solsystemet, astronomiskt tecken ⊕ eller, ♀. I. Inledning Z. rankas på femte plats i storlek och massa bland de stora planeterna, men bland planeterna t ... Stora sovjetiska encyklopedien
Bedömning av befolkningshomogenitet
a priori analys statistisk befolkningsfördelning
För att bedöma homogeniteten i en population används olika metoder, såsom: gruppering, beräkning av variationsindikatorer (spridning, variationskoefficient), analys av avvikande observationer baserade på - och q-statistik.
Baserat på grupperingen och dess grafiska representation (Fig. 1.1 - Fig. 1.9) kan man anta att fördelningsserierna för de tre egenskaperna inte är homogena. Men samtidigt bör man komma ihåg att med en liten urvalsstorlek (n< 50) слишком углубленный анализ гистограммы может привести к неверным выводам, поскольку слабо выраженные «горбики и ямы» частот могут быть обусловлены не основными факторами, определяющими распределение единиц по группам, а просто случайными отклонениями вариантов от.
Efter att ha analyserat avvikande observationer baserade på statistik avslöjas avvikande värden som motsvarar företag 13, liksom avvikande indikatorer på intäkter och kostnader för företag 9.
I detta arbete kommer efterföljande analys att utföras med hänsyn till den anomali som orsakas av objektivt existerande skäl.
Orsakerna till uppkomsten av onormala observationer i aggregatet kan vara:
1) extern, som uppstår till följd av tekniska fel;
2) internt, objektivt existerande.
Variationsindex används för att ytterligare analysera fördelningens form. Variationsindikatorer är indelade i absoluta och relativa. Absoluta värden inkluderar fluktuationsintervall, genomsnittlig linjär avvikelse, spridning, standardavvikelse och kvartilavvikelse. Svängningskoefficienten, relativ linjär avvikelse, variationskoefficient och relativ kvartilvariation är relativa indikatorer.
I detta kursarbete, för att karakterisera befolkningens homogenitet, beräknades indikatorer som spridning, standardavvikelse och variationskoefficient.
Dispersion är den genomsnittliga kvadraten av avvikelser av individuella värden för en egenskap från medelvärdet. Dispersion är inte bara huvudmåttet på variabiliteten hos en egenskap, utan används också för att konstruera indikatorer på korrelationens närhet, vid bedömning av resultaten av provobservationer etc.
För grupperad data beräknas den med formeln (1.3):
där x i är den i:te varianten av egenskapen som medelvärdesbildas;
Urvalsmedelvärde eller aggregerat medelvärde;
n i - frekvens, det vill säga ett tal som visar hur många gånger alternativ från ett givet intervall förekommer, eller vikten av det i:te alternativet;
n är antalet föremål i samlingen.
För att bedöma inverkan av olika faktorer som orsakar variation i en egenskap, beräknas variansen för varje indikator. För detta ändamål byggs beräkningstabeller:
Tabell 1.5
Beräkningstabell för att beräkna spridningen med mängden intäkter från försäljning av varor, produkter, arbeten, tjänster
|
Grupper av företag efter försäljningsintäkter, tusen rubel. |
Antal företag n i |
Mittpunkten för intervallet x i |
|||
Urvalsgenomsnittet beräknas med formeln (1.4):
Alltså = 177166.1.
Tabell 1.5 visar att attributvärdena avviker från urvalsgenomsnittet främst i negativ riktning.
Med formeln (1.3) hittas dispersionen, y 2 = 3422825485.
Tabell 1.6
Beräkningstabell för att beräkna spridningen av kostnaden för sålda varor, produkter, arbeten, tjänster
|
Grupper av företag efter kostnad för varor, produkter, verk, sålda tjänster, tusen rubel. |
Antal företag n i |
Mittpunkten för intervallet x i |
|||
y 2 = 2096102493
Kostnadsvärden överstiger i allmänhet inte provgenomsnittet.
Tabell 1.7
Beräkningstabell för beräkning av spridningen av kommersiella och administrativa kostnader
|
Grupper av företag efter belopp av kommersiella och administrativa utgifter, tusen rubel. |
Antal företag n i |
Mittpunkten för intervallet x i |
|||
y 2 = 183131024,9
Tabellen visar att attributvärdena avviker från urvalsgenomsnittet också huvudsakligen i negativ riktning.
Den vanligaste indikatorn på relativ variabilitet är variationskoefficienten (formel (1.5)):

Standardavvikelsen y = 58504,92, det vill säga mängden intäkter i genomsnitt avviker med 58504,92 tusen rubel.
Baserat på detta är variationskoefficienten:
V in = (58504,92 / 177166,1) * 100% = 33%
Värdet V in utvärderar intensiteten av fluktuationer av optioner i förhållande till deras genomsnittliga värde. Följande betygsskala för egenskapens variabilitet har antagits:
0% < V в?40% - колеблемость незначительная;
40% < V в? 60% - колеблемость средняя (умеренная);
V i > 60% - signifikant fluktuation.
För normala och nära normala fördelningar fungerar indikatorn V in som en indikator på befolkningens homogenitet: det är allmänt accepterat att om ojämlikheten är uppfylld
populationen är kvantitativt homogen enligt denna egenskap. Eftersom variationskoefficienten inte överstiger 33 % kan uppsättningen företag anses vara ganska homogen när det gäller intäkter.
Variationskoefficienten för andra egenskaper är lika med:
1) För gruppen företag till kostnaden för sålda varor, produkter, arbeten, tjänster V in = 33,4 %. Variabiliteten är obetydlig.
2) För gruppen företag i termer av kommersiella och administrativa kostnader V = 32,7 %. Variabiliteten är obetydlig. Populationen kan anses vara homogen.
Eftersom variationskoefficienten för grupperingen av företag efter kostnad något överstiger 33%, kan vi säga att befolkningen är ganska homogen, och överskottet kan förklaras av den lilla urvalsstorleken, anomalien hos vissa värden och påverkan av yttre och inre faktorer.
Kontrollera den statistiska populationen för homogenitet med hjälp av variationskoefficienten baserad på volymen av kommersiella produkter.
Variation - fluktuation, förändring i värdet av en egenskap i en statistisk population, d.v.s. acceptans av enheter av en befolkning eller deras grupper av olika värden av en egenskap.
Variationskoefficienten är ett relativt mått på variation och är förhållandet mellan standardavvikelsen och medelvärdet för den varierande egenskapen, beräknad med formeln:
Standardavvikelse;
Genomsnittligt värde för egenskapen.
Standardavvikelsen inom ramen för denna uppgift beräknas med formeln:

Ju mindre variationskoefficient, desto mer homogen anses den statistiska populationen. Populationen anses vara homogen om variationskoefficienten inte överstiger 33 %.
Låt oss beräkna variationskoefficienten för hela uppsättningen företag baserat på volymen av kommersiell produktion.
Beräkningar presenteras i tabell 6.
Tabell 6.
| Företagsnummer | Q - x snitt | (Q - x medel) 2 | |||
| 163,3 | -757,156 | 573285,208 | |||
| 236,5 | -683,956 | 467795,810 | |||
| 843,3 | -77,156 | 5953,048 | |||
| 1005,9 | 85,444 | 7300,677 | |||
| 696,3 | -224,156 | 50245,912 | |||
| 1031,3 | 110,844 | 12286,392 | |||
| 1361,2 | 440,744 | 194255,274 | |||
| 1712,9 | 792,444 | 627967,493 | |||
| 538,9 | -381,556 | 145584,981 | |||
| 350,4 | -570,056 | 324963,843 | |||
| 2149,9 | 1229,444 | 1511532,549 | |||
| 352,8 | -567,656 | 322233,334 | |||
| 1187,1 | 266,644 | 71099,023 | |||
| 262,4 | -658,056 | 433037,699 | |||
| 438,8 | -481,656 | 231992,502 | |||
| 1150,5 | 230,044 | 52920,242 | |||
| 249,4 | -671,056 | 450316,155 | |||
| 655,3 | -265,156 | 70307,704 | |||
| 2549,5 | 1629,044 | 2653784,354 | |||
| 536,8 | -383,656 | 147191,926 | |||
| 311,2 | -609,256 | 371192,874 | |||
| 809,7 | -110,756 | 12266,892 | |||
| 166,7 | -753,756 | 568148,108 | |||
| 2185,1 | 1264,644 | 1599324,447 | |||
| 2066,2 | 1145,744 | 1312729,314 | |||
| Total: | 12217715,762 | ||||
| 920,456 | |||||
| 488708,630 | |||||
| 699,077 | |||||
| Variationskoefficient | 0,759 | ||||
Av tabellen ser vi att variationskoefficienten är 48,7 %. Detta innebär att befolkningen är heterogen, eftersom populationen anses vara homogen om variationskoefficienten inte överstiger 33 %.
Låt oss beräkna variationskoefficienten för attributvolymen för säljbara produkter, erhållen som ett resultat av enkel gruppering (klausul 3.1.).
Beräkningsresultaten presenteras i tabellerna 7,8,9 och 10.
Tabell 7.1 grupp.
| Företagsnummer | Volym kommersiella produkter (Q), miljoner rubel | Q - x snitt | (Q - x medel) 2 | ||
| 163,3 | -218,146 | 47587,744 | |||
| 236,5 | -144,946 | 21009,388 | |||
| 696,3 | 314,854 | 99132,944 | |||
| 538,9 | 157,454 | 24791,714 | |||
| 350,4 | -31,046 | 963,864 | |||
| 352,8 | -28,646 | 820,602 | |||
| 262,4 | -119,046 | 14171,987 | |||
| 438,8 | 57,354 | 3289,464 | |||
| 249,4 | -132,046 | 17436,187 | |||
| 655,3 | 273,854 | 74995,929 | |||
| 536,8 | 155,354 | 24134,818 | |||
| 311,2 | -70,246 | 4934,522 | |||
| 166,7 | -214,746 | 46115,911 | |||
| Total: | 0,000 | 379385,072 | |||
| 381,446 | |||||
| 34489,552 | |||||
| 185,714 | |||||
| Variationskoefficient | 0,487 | ||||
Tabell 8.2 grupp.
| Företagsnummer | Volym kommersiella produkter (Q), miljoner rubel | Q - x snitt | (Q - x medel) 2 | ||
| 843,3 | -161,333 | 26028,44 | |||
| 1005,9 | 1,266667 | 1,604444 | |||
| 1031,3 | 26,66667 | 711,1111 | |||
| 1187,1 | 182,4667 | 33294,08 | |||
| 1150,5 | 145,8667 | 21277,08 | |||
| 809,7 | -194,933 | ||||
| Total: | 119311,3 | ||||
| 1004,633 | |||||
| 19885,222 | |||||
| 141,015 | |||||
| Variationskoefficient | 0,140 | ||||
Tabell 9.3 grupp,
| Företagsnummer | Volym kommersiella produkter (Q), miljoner rubel | Q - x snitt | (Q - x medel) 2 | ||
| 1361,2 | -175,850 | 30923,223 | |||
| 1712,9 | 175,850 | 30923,223 | |||
| Total: | 61846,445 | ||||
| 1537,050 | |||||
| 20615,482 | |||||
| 143,581 | |||||
| Variationskoefficient | 0,093 | ||||
Tabell 10. 4:e gruppen.
| Företagsnummer | Volym kommersiella produkter (Q), miljoner rubel | Q - x snitt | (Q - x medel) 2 | ||
| 2149,9 | -87,775 | 7704,451 | |||
| 2549,5 | 311,825 | 97234,83 | |||
| 2185,1 | -52,575 | 2764,131 | |||
| 2066,2 | -171,475 | 29403,68 | |||
| Total: | 137107,1 | ||||
| 2237,675 | |||||
| 68553,544 | |||||
| 261,827 | |||||
| Variationskoefficient | 0,117 | ||||
Slutsatser från data:
I grupp 1 är variationskoefficienten 48,7 %. Det betyder att befolkningen inte är homogen.
I grupp 2 är variationskoefficienten 14 %. Det betyder att befolkningen är homogen.
I grupp 3 är variationskoefficienten 9,3 %. Det betyder att befolkningen är homogen.
I grupp 4 är variationskoefficienten 11,7 %. Det betyder att befolkningen är homogen.
Föreläsning 1.3
ANALYS AV UTFORSKNINGSDATA
Nyckelpunkter i prospekteringsanalys
Bild 2
Syftet med explorativ analys är att presentera de observerade data i en kompakt och enkel form, så att man kan identifiera mönster och samband som finns i dem. Explorativ analys inkluderar datatransformation och metoder för att visualisera den, identifiera avvikande värden, en grov bedömning av typen av distribution och utjämning.
Termen explorativ analys används också i en vidare mening än preliminär databehandling. Till exempel, i flerdimensionella procedurer som faktoranalys, multidimensionell dataskalning, är syftet med explorativ analys, förutom analysen av primärdata, att bestämma det minsta antalet faktorer som på ett tillfredsställande sätt reproducerar kovariansmatrisen (korrelationsmatrisen) eller närhetsmatrisen. av de observerade variablerna
Bild 3
Enligt den tidigare föreläsningen tror vi att forskaren har observationer i form av en "objekt-funktion"-matris eller en egenskapsvektor och en partiell eller fullständig frånvaro av a priori-information om orsak- och verkansmekanismen för dessa data. Följande frågor uppstår vanligtvis under analysen:
1. Vilken bearbetning ska observationerna utsättas för?
2. Vilken modell ska jag välja?
3. Vilka slutsatser kan dras?
För att välja en bearbetningsmetod krävs en modell av de observerade data. Innan man gör en observation är det nödvändigt att ange arten och egenskaperna hos den mängd som mäts, d.v.s. använda a priori information. Ju mer fullständig a priori informationen är, desto mer exakt och till en lägre kostnad kan de nödvändiga resultaten erhållas. Därför är formaliseringen av metoder för insamling, bearbetning och användning av information på förhand av stor vikt. Baserat på analysen av denna information byggs en modell av fenomenet som studeras, utrustning väljs och en metodik för att genomföra experimentet utvecklas.
Bild 4
För att få mer fullständig information om fenomenet som studeras görs en primär dataanalys, kallad utforskande dataanalys. Undersökande analys är nödvändig i alla fall, med undantag för mycket enkla uppgifter. Till exempel bör valet av en familj av modeller för det fenomen som studeras i de flesta fall föregås av en preliminär och grafisk analys av data. För att illustrera detta, överväg en enkel univariat linjär regressionsmodell. Enligt denna modell förutsätts att observationer nånga ( x 1 ,Y 1), …, (xn,Yn) kan beskrivas med ekvationen
Som en minimal preliminär analys kan man betrakta ett punktspridningsdiagram ( x j,Yj). Som ett resultat av att analysera graferna kan vi dra slutsatsen att spridningen är konstant Y i, om tillrådligheten att transformera variabler, för att identifiera förekomsten av anomala observationer, vars uteslutning kräver speciell forskning. Efter sådan databehandling, förutsatt att modell (1) är korrekt, är det nödvändigt att uppskatta parametrarna b 0, b 1 och utföra en grafisk analys av residualerna mellan de observerade och uppskattade värdena Y i. Baserat på denna analys kan en annan modell bekräftas eller föreslås.
Bild 5
Låt oss överväga de enklaste relaterade till dataförbehandling. De kompletterar de metoder som beskrivs i den första föreläsningen när de överväger specifika former av datapresentation. Låt oss förklara behovet av explorativ analys av specifika bedömningsfrågor.
Uppskattning av genomsnittet. Låt oss överväga det enklaste exemplet på att uppskatta det sanna medelvärdet m oberoende slumpvariabel x volymprov n. Om en uppskattning av medelvärdet beräknas, blir frågan, "hur mycket skiljer sig uppskattningen från det oberäknade sanna värdet?" Eftersom den sanna meningen m inte är tillgänglig, då bestäms ett konfidensintervall, som täcker det sanna värdet med en given sannolikhet.
Relationen har t- Elevfördelning. Mycket ofta konstrueras 95% konfidensintervall, förutsatt att värdet t normalt fördelade. För en normalfördelning, värdet t kommer att vara lika med 1,96, medan för t- fördelningar vid antalet frihetsgrader v (v = n– 1), lika med 1; 3 och 12, magnitud t, respektive är lika med 12,7; 4.3 och 2.18. Det är därför för små provstorlekar använder normalfördelning istället t- distribution leder till stora fel i intervalluppskattningen. Den stora skillnaden i intervalluppskattningar beror på skillnaden t- fördelning från det normala i fördelningens svansar.
Bild 6
De reella fördelningarnas svansar har som regel en större spridning än normalfördelningens. Naturen för skillnaden mellan den verkliga fördelningen och den normala kan vara olika:
1. De flesta mätningar görs i specifika enheter, såsom milligram, mikron, och deras värden är begränsade. För normalfördelningslagen varierar värdena från – ¥ till + ¥.
2. Skarp asymmetri hos vissa distributioner (till exempel c 2, F) med små prover är kanterna av en enhetlig fördelning abrupta.
3. Beteende på "svansarna" av distributionen. En eller flera extremvärden från huvuddelen av observationer kan väsentligt ändra medelvärdet och katastrofalt förändra variansen. Otroliga värden är nästan oundvikliga i experimentella data. Antalet sådana värden i medicinska data når upp till 30%, och i specialdesignade experiment är det cirka 1% av all data.
Att uppskatta medelvärdet med det aritmetiska medelvärdet har stora fördelar: opartiskhet för allmänna populationer som har en matematisk förväntan, tillräcklighet, fullständighet och följaktligen full effektivitet för normala, Poisson-, gammafördelningar och, under tillräckligt breda förhållanden, en bekväm asymptotiskt normalfördelning, vilket i många fall redan ungefär uppnås med genomsnittliga urvalsstorlekar n. Det finns också nackdelar med en sådan uppskattning: dess effektivitet är noll för en enhetlig fördelning, och för vissa prover kan bara en osannolikt stor observation göra den aritmetiska medeluppskattningen värdelös.
Bild 7
Om fördelningens normalitet kränks av extremdata, är det tillrådligt att använda robust(robust – stark, frisk, kraftig) bedömningar. Ett exempel på en robust uppskattning av medelvärdet som är tolerant för avvikelser av fördelningens svansar från normalen är median distributioner. Det, liksom medianvärdet för observationer, beror inte på en eller flera osannolikt stora dimensioner.
Medianen, som en robust sådan, är inte en effektiv uppskattning i förhållande till den aritmetiska medeluppskattningen för en normalfördelning.
Bild 8
Mått på spridning. I praktiken används följande mått för att karakterisera mängden dataspridning: standardavvikelse s eller dess kvadrat - dispersion s 2, samt intervall R. Uppskattningar av dessa storheter anges i enlighet därmed S, S 2 , R. Uppskattning av spridning av S allmänt använd och användbar för linjära transformationer som Y= b + a X. För vissa distributioner är s 2 = ∞, och intervallet är tillämpligt; osannolikt stora avvikelser i observationer kan också göra variansskattningen mycket stor, vilket resulterar i en annan distributionstyp än den sanna.
Uppskattning av spridning efter provintervall är en snabb procedur. I samband med tillkomsten av höghastighetsdatorer, datorfördelar R jämfört med S blir mindre och mindre viktiga, men fördelarna med enkel beräkning kvarstår R och möjligheten för icke-specialister att tillämpa denna statistik. Därmed har omfattningen nästan helt ersatts S från kvalitetskontrollsystem där små prover tas med korta tidsintervall och kontrolldiagram konstrueras utifrån medelvärden och intervall.
Det bör noteras att intervallet kan användas för att känna igen stora osannolika fel i beräkningar S för prover från vilken population som helst. Detta följer av det begränsade förhållandet S/R.
Bild 9
För att sammanfatta de diskuterade bedömningarna måste man dra slutsatsen att det finns skäl att inte behandla alla uppgifter lika. Innan du börjar bearbeta observationer är det nödvändigt att kontrollera provets homogenitet och, om det är heterogent, dela upp det i lager. Förekomsten av extrema observationer bryter också mot provets homogenitet. I det här fallet är ett tillvägagångssätt baserat på att upptäcka och ta bort dessa extremvärden.
Att ta bort extremvärden säkerställer säkerheten för uppskattningen, men är bara effektivt om det finns en tydlig gräns mellan borttagna och icke-borttagna data. Intill de uppenbara data som sticker ut skarpt finns en zon av "tveksamma" data (fig. 1), som inte alltid kan kännas igen. Här är det lätt att tillåta felaktiga raderingar och orimliga besparingar, full effektivitet kan inte förväntas ens efter radering. Dessa svårigheter kan övervinnas genom att använda robusta uppskattningsmetoder. Robusta algoritmer säkerställer säker och effektiv uppskattning i närvaro av extremvärden och tvivelaktiga data.

Ris. 1. Fördelningstäthet. Dela in data i tre grupper.
Bild 10
Om kvaliteten på resultaten Syftet med studien är att svara på frågan: kan resultaten tillämpas i praktiken. Lämpligheten av de erhållna resultaten kan bedömas genom korskontrollmetoder. De vanligaste metoderna är enkla och dubbel korskontroll.
En enkel dubbelkoll. Den resulterande modellen testas på data som skiljer sig från dem från vilka modellparametrarna beräknades. I det här fallet kan urvalet av observationer delas upp i två (eller flera) delar. En del används för bearbetning och den andra för testning. Delarna kan sedan bytas ut, vilket kan ge något mer information, även om det finns vissa svårigheter som uppstår från förhållandet mellan de två bedömningarna av modellkvalitet.
Sådan dubbelkontroll kan också utföras för flera uppdelningar av data, till exempel kan provet delas upp i 10 lika delar. Utvärdera modellen på vilken som helst 9 av dem och utför verifiering på den återstående delen. Efter detta, upprepa proceduren 9 gånger, ta nya 9 delar varje gång. I vissa fall är proceduren komplicerad. Beräkningen utförs på alla data utan en observation, och verifieringen utförs på det kasserade värdet. Beräkningarna upprepas för var och en av provobservationerna. Du ska inte låta dig luras av resultatet av ett enkelt test, eftersom kontrollprovet alltid kommer att vara mer likt arbetsprovet än provet av objekt som forskningsresultaten kommer att användas för.
Dubbelkolla. Testet utförs på data som skiljer sig från både de som modellen byggdes på och de som användes för att beräkna modellparametrarna. Läkare kallar denna testmetod "dubbelblind". "Färska data" för korskontroll kan samlas in efter val av modell och beräkning av parametrar. Om det inte är möjligt att erhålla sådana data, kan du vända dig till arkivdata, förutsatt att de förblev okända medan modellen byggdes och parametrarna för denna modell beräknades. Vid dubbelkontroll är det viktigt att de uppgifter som används för verifiering skiljer sig från dem som bedömningarna gjordes på. Du kan använda data från olika år om de kan hänföras till samma tidpunkt, eller data från andra forskare.
Bild 11
Heterogena prover
Standardmetoder för att skatta eventuell statistik av urvalsdata bygger på antagandet att urvalet är taget från en homogen population med en enkel distributionslagstiftning. Samtidigt, i praktiken, bildas prover ofta under påverkan av olika orsaker och förhållanden, och de kan presenteras som en kombination av en viss uppsättning homogena prov, som var och en har en enkel struktur. Till exempel kan inkomsterna för de rika och andra medborgare i staten inte anses vara homogena, eftersom de har olika ekonomiska baser; föremål av olika värde, olika i ekonomiska konsekvenser. Exempel inkluderar inhomogena sekvenser av dynamiska modeller i vibrationsanalysproblem inom maskinteknik; seismogram inom geofysik; kardiogram med hjärtfrekvensavvikelser.
Naturen av heterogenitet kan vara olika. Det är till exempel möjligt att kombinera från populationer med olika medelvärden och varianser eller med samma medel men olika varianser. En viktig klass av heterogena prover består också av prover som innehåller ett eller flera osannolikt stora eller små dimensioner. Bearbetning av heterogena
Låt observationerna bestå av tre homogena lager som vart och ett kan beskrivas med en enkel endimensionell regression. Dessa beroenden visas i fig. 2, där de räta linjerna är regressionslinjerna för varje population. Om vi bearbetar det kombinerade urvalet av dessa populationer får vi regressionsförhållandet som visas i fig. 2 streckade linjer. Uppenbarligen är regression på poolad data meningslös.
För att fastställa provets homogenitet krävs en detaljerad innehållsanalys av populationen som studeras. Denna analys bör baseras på ett väsentligt icke-slumpmässigt särdrag, enligt vilket den ursprungliga populationen kan representeras som en förening av flera homogena populationer. Till exempel kan skattedeklarationer delas in i grupper utifrån inkomst; institutioner - efter antalet anställda; gårdar - efter total markyta och bruttoinkomst. När du delar upp ett prov i lager är det nödvändigt att svara på frågorna på vilken grund det är bättre att utföra stratifiering, hur man bestämmer gränserna mellan lager, hur många lager det ska finnas.
Bild 12
Dela upp en heterogen befolkning i homogena
Låt urvalet av populationen som studeras x 1, ..., x n, innehålla element av två oberoende stokastiska variabler med fördelningsdensiteter f(x,q 1) och f(x,q 2). Låt oss beteckna med A mängden urvalselement som tillhör den första slumpvariabeln, B uppsättningen urvalselement från den andra populationen. Det krävs att man hittar uppskattningar av 1, 2 okända parametrar q 1, q 2 och uppsättningarna A och B. För att uppskatta dessa fyra okända, använder vi metoden maximum likelihood. Vi hittar de okända q 1, q 2 och A och B från villkoret för koordinatvis maximering av sannolikhetsfunktionen
Vid varje steg maximeras värdet av sannolikhetsfunktionen för en av de okända. 1) < f(x i , 2),. Если f(x i , 1) = f(x i , 2), то оба варианта одинаково правдоподобны, что для непрерывных распределений является маловероятным событием. Далее берем следующий элемент и относим его в то или иное множество. Полученные множества сравниваем с множествами на предыдущем шаге. Если они отличаются, то переходим к шагу 2, в противном случае алгоритм останавливается, и задача считается решенной.
Nackdelen med algoritmen är att den stannar vid det första lokala maximum för sannolikhetsfunktionen. Denna nackdel kan delvis undvikas genom att lösa problemet för olika initiala partitioner i delmängder A och B. Om slutresultaten för flera initiala tillstånd är olika, tas den lösning för vilken värdet av sannolikhetsfunktionen är större. Det följer att ovanstående algoritm även är tillämplig för prover som innehåller mer än två lager.
Objekten för den statistiska forskningen är statistiska aggregat som består av enskilda enheter som kännetecknas av olika egenskaper. Som ett resultat av forskningen identifieras statistiska mönster utifrån användning av modeller för socioekonomiska fenomen och metoder för bearbetning och analys av ekonomisk och statistisk information.
En statistisk population är en uppsättning objekt, fenomen, förenade av några gemensamma egenskaper (tecken) och föremål för statistisk forskning. Till exempel helheten av industriföretag i ett land. Enskilda objekt av ett fenomen som utgör ett statistiskt aggregat och kallas enheter av aggregatet, med vissa gemensamma egenskaper, kan skilja sig från varandra i andra egenskaper. Därför kan populationer vara homogena (kvalitativt homogena) och heterogena (kvalitativt heterogena).
I en homogen population liknar objekt (enheter av populationen) varandra när det gäller egenskaper som är väsentliga för en given studie och tillhör samma typ av fenomen. En homogen population, som är homogen i vissa avseenden, kan vara heterogen i andra.
Element (enheter) i en heterogen population relaterar till olika typer av fenomen som studeras. För en heterogen population är beräkningen av generaliserande egenskaper, särskilt i form av ett medelvärde, olaglig. Med hjälp av grupperingsmetoden och taxonomimetoden kan homogena grupper bildas i en heterogen population.
Hela uppsättningen av verkligt existerande objekt som kännetecknar alla fenomen kallas generella. För statistisk forskning kan en uppsättning enheter väljas från den allmänna populationen enligt vissa regler, som bildar en urvalspopulation.
Varje enhet av aggregatet kännetecknas av olika egenskaper - särdrag, egenskaper, kvalitet.
En variabel egenskap är en egenskap som antar olika värden inom den statistiska populationen för enheter av den statistiska populationen. Detta utesluter dock inte upprepningar av individuella värden (varianter) av en egenskap; flera enheter av en population kan ha samma värden för en egenskap. Ett exempel på en varierande egenskap är storleken på månadslönerna för arbetare på ett företag.
Ett kvalitativt tecken (attributivt) är ett tecken, vars individuella betydelser uttrycks i form av begrepp och namn. Till exempel arbetarens yrke (montör, montör), utbildningsnivå (primär, sekundär, högre).
En kvantitativ egenskap är en egenskap vars individuella värden har ett kvantitativt uttryck (till exempel produktionskostnaden för olika företag i samma bransch).
Ett effektivt attribut är ett beroende attribut, det vill säga ett som ändrar sitt värde under påverkan av ett annat faktorattribut som är associerat med det.
En faktoregenskap (faktor) är en egenskap som påverkar en annan associerad effektiv egenskap och orsakar dess förändring (variation). Rollen för dessa funktioner i olika uppgifter kan förändras, i en uppgift fungerar den som en faktor, i en annan - som en följd. Till exempel fungerar arbetsproduktiviteten som en faktor för att förändra (sänka) kostnaden för en produktionsenhet, och samtidigt är arbetsproduktiviteten i samband med arbetarens kvalifikationer ett effektivt inslag.
Som ett resultat av statistisk forskning etableras ett statistiskt mönster, vilket betraktas som ett kvantitativt mönster av förändringar i rum och tid i massfenomen och processer i det sociala livet, bestående av många element (enheter av helheten). Det är inte karakteristiskt för enskilda enheter av aggregatet, utan för hela aggregatet som helhet. På grund av detta uppträder mönstret som är inneboende i detta fenomen (process) endast med ett tillräckligt stort antal observationer och endast i genomsnitt. Detta är alltså ett genomsnittligt mönster av massfenomen och -processer. I ett stort antal observationer tar individuella avvikelser från genomsnittet i en eller annan riktning, orsakade av slumpmässiga orsaker, ut varandra och ett mönster uppstår. Detta förbinder det statistiska mönstret med lagen om stora siffror. När rum-tidsintervallen för utvecklingen av fenomenet ökar, blir dess mönster mer och mer stabilt.
Genom att känna till det statistiska mönstret för ett visst massfenomen är det således möjligt att med en viss sannolikhet förutse dess vidare utveckling och bestämma värdet av den egenskap (indikator) som studeras. Det måste dock beaktas att betydande förändringar i existensvillkoren för detta fenomen kan leda till betydande förändringar i styrkan av detta beroende.
Inom socioekonomisk statistik är lagen om stora siffror en allmän princip, på grund av vilken kvantitativa mönster som är inneboende i sociala massfenomen tydligt manifesteras endast i ett tillräckligt stort antal observationer. Lagen om stora tal genereras av de speciella egenskaperna hos masssociala fenomen. De senare skiljer sig å ena sidan på grund av sin individualitet från varandra och har å andra sidan något gemensamt på grund av att de tillhör en viss art, klass eller vissa grupper. Enskilda fenomen är mer mottagliga för påverkan av slumpmässiga och obetydliga faktorer än massan som helhet. I ett stort antal observationer upphävs slumpmässiga avvikelser i motsatta riktningar från mönstren. Som ett resultat av den ömsesidiga annulleringen av slumpmässiga avvikelser blir medelvärdena som beräknas för värden av samma typ typiska, vilket återspeglar verkan av konstanta och signifikanta faktorer under givna förhållanden för plats och tid. Trender och mönster som avslöjas med hjälp av lagen om stora siffror är massiva statistiska trender.
Statistisk forskning av socioekonomiska fenomen bedrivs med olika metoder med hjälp av modeller av dessa fenomen.
En modell är en representation, en analog av ett fenomen eller en process i dess grunddrag som är väsentliga för studiens syften. Processen att skapa en modell kallas modellering. Modellen måste ta hänsyn till alla viktiga samband, mönster och utvecklingsvillkor på ett sådant sätt att det på grundval av det är möjligt att utföra experiment vars syfte är att bestämma det modellerade objektets "beteende" i olika möjliga (ofta) oobserverbara i verkligheten). Ekonomiska fenomen och processer simuleras med hjälp av ekonomiska och matematiska modeller.
En ekonomisk-matematisk modell är en beskrivning av ett ekonomiskt fenomen eller en ekonomisk process med hjälp av ett eller flera matematiska uttryck (ekvationer, funktioner, ojämlikheter, identiteter). Matematiska uttryck kännetecknar de viktigaste sambanden mellan fenomen och processer, förutsättningar och mönster för deras utveckling, begränsningar, krav etc. En ekonomisk-matematisk modell är en generalisering av väsentlig kvalitativ och kvantitativ information om analysobjektet och tjänar som grund för att genomföra beräkningsexperiment som gör det möjligt att erhålla olika egenskaper och parametrar för objektet som studeras för givna förhållanden för dess utveckling. Utvecklingen och tillämpningen av ekonomiska och matematiska modeller utökar avsevärt möjligheterna för ekonomisk analys. De viktigaste fördelarna med att använda ekonomiska och matematiska modeller är följande:
Samtidigt beaktande av ett stort antal krav, förutsättningar och antaganden i modellen, samt tillräcklig frihet att revidera dessa villkor under arbetet med modellen;
Konsistens (kompatibilitet) för systemet med indikatorer som erhålls från modellen;
Förmågan att erhålla alternativ för beteendet hos fenomenet som studeras för ett brett spektrum och kombination av initiala förutsättningar och antaganden (till exempel alternativ för att prognostisera ekonomisk utveckling).
Ekonomiska-matematiska modeller delas in i teoretisk-ekonomiska och tillämpade modeller efter deras syfte. Många tillämpade modeller är ekonomisk-statistiska modeller eller inkluderar de senare som komponenter.
Teoretisk-ekonomiska modeller är ekonomisk-matematiska modeller utformade för kvalitativ analys av ekonomiska system, processer och fenomen.Värdena på parametrarna och även den funktionella formen av sambanden som ingår i den teoretiskt-ekonomiska modellen är vanligtvis inte specificerade. De slutsatser som erhålls med dessa modeller är vanligtvis av generell karaktär. Ett typiskt exempel är slutsatsen om stabiliteten (instabiliteten) i det undersökta ekonomiska systemet, om dess parametrar uppfyller vissa krav, om existensen (frånvaron) av balanserade eller optimala lösningar. Teoretiska ekonomiska modeller används i stor utsträckning inom teoretisk ekonomisk forskning. För närvarande är konstruktion och studier av teoretiska-ekonomiska modeller ämnet för matematisk ekonomi. För att studera dem används en utvecklad matematisk apparat (teori om differentialekvationer, matristeori, optimering och spelteoretiska metoder etc.).
En ekonomisk-statistisk modell är ett system av matematiska samband som beskriver ett visst ekonomiskt objekt, process eller fenomen, vars parametrar bestäms (uppskattas) på grundval av faktiska data med hjälp av statistiska data (i motsats till en teoretisk-ekonomisk modell) . Strukturen och den specifika typen av ekonomisk-statistisk modell bestäms av detaljerna hos det objekt som modelleras, forskarens teoretiska begrepp, studiens mål, tillgången på information och de databehandlingsmetoder som används. Processen att konstruera en modell delas in i två inbördes relaterade steg: att bestämma den allmänna formen av sambanden mellan modellen och de variabler som ingår i dem och statistiskt uppskatta parametervärden baserat på observationsdata. De mest använda ekonomiska statistiska modellerna inkluderar trender, tidsseriemodeller, isolerade regressionsekvationer och ekonometriska modeller. Ekonomisk-statistiska modeller används i stor utsträckning vid planering och analys av ekonomiska system, studerar deras svar på förändringar i externa och interna driftsförhållanden, såväl som för att prognostisera och bestämma olika alternativ för framtida utveckling.
För att uppskatta parametrarna för en ekonometrisk modell krävs speciella simultanuppskattningsmetoder (det har bevisats att den vanliga minsta kvadratmetoden, tillämpad på varje ekvation av den ekonometriska modellen isolerat, leder till inkonsekventa uppskattningar). De vanligaste metoderna för samtidig uppskattning av en ekonometrisk modell är tvåstegs och trestegs minsta kvadrater.
- I kontakt med 0
- Google+ 0
- OK 0
- Facebook 0






