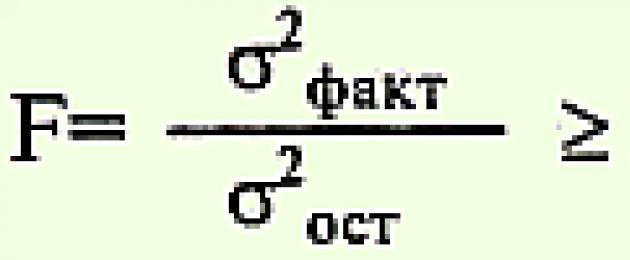
В данной статье рассмотрен дисперсионный анализ. Проанализированы характерные особенности его применения, предоставлены методы дисперсионного анализа,условия применения дисперсионного анализа. Выявлена и обоснована необходимость использования данного метода. На основе проведенного исследования предоставляются этапы классического дисперсионного анализа.
- К вопросу обеспечением контроля качества автомобилей после проведения ремонтных мероприятий в предприятиях автомобильного сервиса с учетом требований системы сертификации
- Проблемы внедрения информационных технологий в логистике на примере российских организаций
- Повышение эффективности волновой генераторной установки
- Учебно-методическое пособие «Система Земля-Луна» в системе дистанционного обучения Moodle
Основной целью дисперсионного анализа является исследование значимости различия между средними. Если вы просто сравниваете средние в двух выборках, дисперсионный анализ даст тот же результат, что и обычный t- критерий для независимых выборок (это если сравниваются две независимые группы объектов или наблюдений) или t-критерий для зависимых выборок (это если сравниваются две переменные на одном и том же множестве объектов или наблюдений).
Дисперсионный анализ имеет такое название в связи с некоторыми факторами. Может показаться странным, что процедура сравнения средних называется дисперсионным анализом. В действительности, это связано с тем, что при исследовании статистической значимости различия между средними двух (или нескольких) групп, мы на самом деле сравниваем (т.е. анализируем) выборочные дисперсии. Фундаментальная концепция дисперсионного анализа предложена Фишером в 1920 году. Возможно, более естественным был бы термин анализ суммы квадратов или анализ вариации, но в силу традиции употребляется термин дисперсионный анализ.
Дисперсионный анализ - метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В отличие от t-критерия позволяет сравнивать средние значения трёх и более групп. Разработан Р. Фишером для анализа результатов экспериментальных исследований. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of Variance ).
При проведении исследования рынка часто встает вопрос о сопоставимости результатов. Например, проводя опросы по поводу потребления какого-либо товара в различных регионах страны, необходимо сделать выводы, на сколько данные опроса отличаются или не отличаются друг от друга. Сопоставлять отдельные показатели не имеет смысла и поэтому процедура сравнения и последующей оценки производится по некоторым усредненным значениям и отклонениям от этой усредненной оценки. Изучается вариация признака. За меру вариации может быть принята дисперсия. Дисперсия σ 2 – мера вариации, определяемая как средняя из отклонений признака, возведенных в квадрат.
На практике часто возникают задачи более общего характера – задачи проверки существенности различий средних выборочных нескольких совокупностей. Например, требуется оценить влияние различного сырья на качество производимой продукции, решить задачу о влиянии количества удобрений на урожайность с.-х. продукции.
Иногда дисперсионный анализ применяется, чтобы установить однородность нескольких совокупностей (дисперсии этих совокупностей одинаковы по предположению; если дисперсионный анализ покажет, что и математические ожидания одинаковы, то в этом смысле совокупности однородны). Однородные же совокупности можно объединить в одну и тем самым получить о ней более полную информацию, следовательно, и более надежные выводы.
Методы дисперсионного анализа
- Метод по Фишеру (Fisher) - критерий F; Метод применяется в однофакторном дисперсионном анализе, когда совокупная дисперсия всех наблюдаемых значений раскладывается на дисперсию внутри отдельных групп и дисперсию между группами.
- Метод "общей линейной модели". В его основе лежит корреляционный или регрессионный анализ, применяемый в многофакторном анализе.
Однофакторная дисперсионная модель имеет вид: x ij = μ + F j + ε ij ,
где х ij – значение исследуемой переменой, полученной на i-м уровне фактора (i=1,2,...,т) c j-м порядковым номером (j=1,2,...,n); F i – эффект, обусловленный влиянием i-го уровня фактора; ε ij – случайная компонента, или возмущение, вызванное влиянием неконтролируемых факторов, т.е. вариацией переменой внутри отдельного уровня.
Простейшим случаем дисперсионного анализа является одномерный однофакторный анализ для двух или нескольких независимых групп, когда все группы объединены по одному признаку. В ходе анализа проверяется нулевая гипотеза о равенстве средних. При анализе двух групп дисперсионный анализ тождественен двухвыборочному t -критерию Стьюдента для независимых выборок, и величина F -статистики равна квадрату соответствующей t -статистики.
Для подтверждения положения о равенстве дисперсий обычно применяется критерий Ливена (Levene"s test ). В случае отвержения гипотезы о равенстве дисперсий основной анализ неприменим. Если дисперсии равны, то для оценки соотношения межгрупповой и внутригрупповой изменчивости применяется F -критерий Фишера.Если F -статистика превышает критическое значение, то нулевая гипотеза отвергается и делается вывод о неравенстве средних. При анализе средних двух групп результаты могут быть интерпретированы непосредственно после применения критерия Фишера.
Множество факторов. Мир по своей природе сложен и многомерен. Ситуации, когда некоторое явление полностью описывается одной переменной, чрезвычайно редки. Например, если мы пытаемся научиться выращивать большие помидоры, следует рассматривать факторы, связанные с генетической структурой растений, типом почвы, освещенностью, температурой и т.д. Таким образом, при проведении типичного эксперимента приходится иметь дело с большим количеством факторов. Основная причина, по которой использование дисперсионного анализа предпочтительнее повторного сравнения двух выборок при разных уровнях факторов с помощью серий t- критерия, заключается в том, что дисперсионный анализ существенно более эффективен и, для малых выборок, более информативен. Вам нужно сделать определенные усилия, чтобы овладеть техникой дисперсионного анализа, реализованной на STATISTICA, и ощутить все ее преимущества в конкретных исследованиях.
Двухфакторная дисперсионная модель имеет вид:
x ijk =μ+F i +G j +I ij +ε ijk ,
где x ijk - значение наблюдения в ячейке ij с номером k; μ - общая средняя; F i - эффект, обусловленный влиянием i-го уровня фактора А; G j - эффект, обусловленный влиянием j-го уровня фактора В; I ij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели; ε ijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки. Предполагается, что ε ijk имеет нормальный закон распределения N(0; с 2), а все математические ожидания F * , G * , I i * , I * j равны нулю.
Существуют условия применения дисперсионного анализа:
- Задачей исследования является определение силы влияния одного (до 3) факторов на результат или определение силы совместного влияния различных факторов (пол и возраст, физическая активность и питание и т.д.).
- Изучаемые факторы должны быть независимые (несвязанные) между собой. Например, нельзя изучать совместное влияние стажа работы и возраста, роста и веса детей и т.д. на заболеваемость населения.
- Подбор групп для исследования проводится рандомизированно (случайный отбор). Организация дисперсионного комплекса с выполнением принципа случайности отбора вариантов называется рандомизацией (перев. с англ. - random), т.е. выбранные наугад.
- Можно применять как количественные, так и качественные (атрибутивные) признаки.
При проведении однофакторного дисперсионного анализа рекомендуется (необходимое условие применения):
- Нормальность распределения анализируемых групп или соответствие выборочных групп генеральным совокупностям с нормальным распределением.
- Независимость (не связанность) распределения наблюдений в группах.
- Наличие частоты (повторность) наблюдений.
Нормальность распределения определяется кривой Гаусса (Де Мавура), которую можно описать функцией у=f(х), так как она относится к числу законов распределения, используемых для приближенного описания явлений, которые носят случайный, вероятностный характер. Предмет медико-биологических исследований - явления вероятностного характера, нормальное распределение в таких исследованиях встречается весьма часто.
Классический дисперсионный анализ проводится по следующим этапам:
- Построение дисперсионного комплекса.
- Вычисление средних квадратов отклонений.
- Вычисление дисперсии.
- Сравнение факторной и остаточной дисперсий.
- Оценка результатов с помощью теоретических значений распределения Фишера-Снедекора
- Современные приложения дисперсионного анализа охватывают широкий круг задач экономики, биологии и техники и трактуются обычно в терминах статистической теории выявления систематических различий между результатами непосредственных измерений, выполненных при тех или иных меняющихся условиях.
- Благодаря автоматизации дисперсионного анализа исследователь может проводить различные статистические исследования с применение ЭВМ, затрачивая при этом меньше времени и усилий на расчеты данных. В настоящее время существует множество пакетов прикладных программ, в которых реализован аппарат дисперсионного анализа. Наиболее распространенными являются такие программные продукты как: MS Excel, Statistica; Stadia; SPSS.
В современных статистических программных продуктах реализованы большинство статистических методов. С развитием алгоритмических языков программирования стало возможным создавать дополнительные блоки по обработке статистических данных.
Дисперсионный анализ является мощным современным статистическим методом обработки и анализа экспериментальных данных в психологии, биологии, медицине и других науках. Он очень тесно связан с конкретной методологией планирования и проведения экспериментальных исследований.
Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную.
Список литературы
- Аблеева, А. М. Формирование фонда оценочных средств в условиях ФГОС [Текст] / А. М. Аблеева, Г. А. Салимова // Актуальные проблемы преподавания социально-гуманитарных, естественно - научных и технических дисциплин в условиях модернизации высшей школы: материалы международной научно-методической конференции, 4-5 апреля 2014 г. / Башкирский ГАУ, Факультет информационных технологий и управления. - Уфа, 2014. - С. 11-14.
- Ганиева, А.М. Статистический анализ занятости и безработицы [Текст] / А.М. Ганиева, Т.Н. Лубова // Актуальные вопросы экономико-статистического исследования и информационных технологий: сб. науч. ст.: посвящается к 40-летию создания кафедры "Статистики и информационных систем в экономике" / Башкирский ГАУ. - Уфа, 2011. - С. 315-316.
- Исмагилов, Р. Р. Творческая группа - эффективная форма организации научных исследований в высшей школе [Текст] / Р. Р. Исмагилов, М. Х. Уразлин, Д. Р. Исламгулов // Научно-технический и научно-образовательный комплексы региона: проблемы и перспективы развития: материалы научно-практической конференции / Академия наук РБ, УГАТУ. - Уфа, 1999. - С. 105-106.
- Исламгулов, Д.Р. Компетентностный подход в обучении: оценка качества образования [Текст] / Д.Р. Исламгулов, Т.Н. Лубова, И.Р. Исламгулова // Современный научный вестник. – 2015. – Т. 7. - № 1. – С. 62-69.
- Исламгулов, Д. Р. Научно-исследовательская работа студентов - важнейший элемент подготовки специалистов в аграрном вузе [Текст] / Д. Р. Исламгулов // Проблемы практической подготовки студентов в вузе на современном этапе и пути их решения: сб. материалов науч.-метод. конф., 24 апреля 2007 года / Башкирский ГАУ. - Уфа, 2007. - С. 20-22.
- Лубова, Т.Н. Основа реализации федерального государственного образовательного стандарта – компетентностный подход [Текст] / Т.Н. Лубова, Д.Р. Исламгулов, И.Р. Исламгулова// БЪДЕЩИТЕ ИЗСЛЕДОВАНИЯ – 2016: Материали за XII Международна научна практична конференция, 15-22 февруари 2016. – София: Бял ГРАД-БГ ООД, 2016. – Том 4 Педагогически науки. – C. 80-85.
- Лубова, Т.Н. Новые образовательные стандарты: особенности реализации [Текст] / Т.Н. Лубова, Д.Р. Исламгулов // Современный научный вестник. – 2015. – Т. 7. - № 1. – С. 79-84.
- Лубова, Т.Н. Организация самостоятельной работы обучающихся [Текст] / Т.Н. Лубова, Д.Р. Исламгулов // Реализация образовательных программ высшего образования в рамках ФГОС ВО: материалы Всероссийской научно-методической конференции в рамках выездного совещания НМС по природообустройству и водопользованию Федерального УМО в системе ВО. / Башкирский ГАУ. - Уфа, 2016. - С. 214-219.
- Лубова, Т.Н. Основа реализации федерального государственного образовательного стандарта – компетентностный подход [Текст] / Т.Н. Лубова, Д.Р. Исламгулов, И.Р. Исламгулова // Современный научный вестник. – 2015. – Т. 7. - № 1. – С. 85-93.
- Саубанова, Л.М. Уровень демографической нагрузки [Текст] / Л.М. Саубанова, Т.Н. Лубова // Актуальные вопросы экономико-статистического исследования и информационных технологий: сб. науч. ст.: посвящается к 40-летию создания кафедры "Статистики и информационных систем в экономике" / Башкирский ГАУ. - Уфа, 2011. - С. 321-322.
- Фахруллина, А.Р. Статистический анализ инфляции в России [Текст] / А.Р. Фахруллина, Т.Н. Лубова // Актуальные вопросы экономико-статистического исследования и информационных технологий: сб. науч. ст.: посвящается к 40-летию создания кафедры "Статистики и информационных систем в экономике" / Башкирский ГАУ. - Уфа, 2011. - С. 323-324.
- Фархутдинова, А.Т. Рынок труда в Республике Башкортостан в 2012 году [Электронный ресурс] / А.Т. Фархутдинова, Т.Н. Лубова // Студенческий научный форум. Материалы V Международной студенческой электронной научной конференции: электронная научная конференция (электронный сборник). Российская академия естествознания. 2013.
Дисперсионный анализ
Курсовая работа по дисциплине: «Системный анализ»
Исполнитель студент гр. 99 ИСЭ-2 Жбанов В.В.
Оренбургский государственный университет
Факультет информационных технологий
Кафедра прикладной информатики
г. Оренбург-2003
Введение
Цель работы: познакомится с таким статистическим методом, как дисперсионный анализ.
Дисперсионный анализ (от латинского Dispersio – рассеивание) – статистический метод, позволяющий анализировать влияние различных факторов на исследуемую переменную. Метод был разработан биологом Р. Фишером в 1925 году и применялся первоначально для оценки экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость дисперсионного анализа для экспериментов в психологии, педагогике, медицине и др.
Целью дисперсионного анализа является проверка значимости различия между средними с помощью сравнения дисперсий. Дисперсию измеряемого признака разлагают на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение таких слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их комбинации /1/.
При истинности нулевой гипотезы (о равенстве средних в нескольких группах наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии.
При проведении исследования рынка часто встает вопрос о сопоставимости результатов. Например, проводя опросы по поводу потребления какого-либо товара в различных регионах страны, необходимо сделать выводы, на сколько данные опроса отличаются или не отличаются друг от друга. Сопоставлять отдельные показатели не имеет смысла и поэтому процедура сравнения и последующей оценки производится по некоторым усредненным значениям и отклонениям от этой усредненной оценки. Изучается вариация признака. За меру вариации может быть принята дисперсия. Дисперсия σ 2 – мера вариации, определяемая как средняя из отклонений признака, возведенных в квадрат.
На практике часто возникают задачи более общего характера – задачи проверки существенности различий средних выборочных нескольких совокупностей. Например, требуется оценить влияние различного сырья на качество производимой продукции, решить задачу о влиянии количества удобрений на урожайность с/х продукции.
Иногда дисперсионный анализ применяется, чтобы установить однородность нескольких совокупностей (дисперсии этих совокупностей одинаковы по предположению; если дисперсионный анализ покажет, что и математические ожидания одинаковы, то в этом смысле совокупности однородны). Однородные же совокупности можно объединить в одну и тем самым получить о ней более полную информацию, следовательно, и более надежные выводы /2/.
1 Дисперсионный анализ
1.1 Основные понятия дисперсионного анализа
В процессе наблюдения за исследуемым объектом качественные факторы произвольно или заданным образом изменяются. Конкретная реализация фактора (например, определенный температурный режим, выбранное оборудование или материал) называется уровнем фактора или способом обработки. Модель дисперсионного анализа с фиксированными уровнями факторов называют моделью I, модель со случайными факторами - моделью II. Благодаря варьированию фактора можно исследовать его влияние на величину отклика. В настоящее время общая теория дисперсионного анализа разработана для моделей I.
В зависимости от количества факторов, определяющих вариацию результативного признака, дисперсионный анализ подразделяют на однофакторный и многофакторный.
Основными схемами организации исходных данных с двумя и более факторами являются:
Перекрестная классификация, характерная для моделей I, в которых каждый уровень одного фактора сочетается при планировании эксперимента с каждой градацией другого фактора;
Иерархическая (гнездовая) классификация, характерная для модели II, в которой каждому случайному, наудачу выбранному значению одного фактора соответствует свое подмножество значений второго фактора.
Если одновременно исследуется зависимость отклика от качественных и количественных факторов, т.е. факторов смешанной природы, то используется ковариационный анализ /3/.
Таким образом, данные модели отличаются между собой способом выбора уровней фактора, что, очевидно, в первую очередь влияет на возможность обобщения полученных экспериментальных результатов. Для дисперсионного анализа однофакторных экспериментов различие этих двух моделей не столь существенно, однако в многофакторном дисперсионном анализе оно может оказаться весьма важным.
При проведении дисперсионного анализа должны выполняться следующие статистические допущения: независимо от уровня фактора величины отклика имеют нормальный (Гауссовский) закон распределения и одинаковую дисперсию. Такое равенство дисперсий называется гомогенностью. Таким образом, изменение способа обработки сказывается лишь на положении случайной величины отклика, которое характеризуется средним значением или медианой. Поэтому все наблюдения отклика принадлежат сдвиговому семейству нормальных распределений.
Говорят, что техника дисперсионного анализа является "робастной". Этот термин, используемый статистиками, означает, что данные допущения могут быть в некоторой степени нарушены, но несмотря на это, технику можно использовать.
При неизвестном законе распределения величин отклика используют непараметрические (чаще всего ранговые) методы анализа.
В основе дисперсионного анализа лежит разделение дисперсии на части или компоненты. Вариацию, обусловленную влиянием фактора, положенного в основу группировки, характеризует межгрупповая дисперсия σ 2 . Она является мерой вариации частных средних по группам
вокруг общей средней и определяется по формуле: ,где k - число групп;
n j - число единиц в j-ой группе;
- частная средняя по j-ой группе; - общая средняя по совокупности единиц.Вариацию, обусловленную влиянием прочих факторов, характеризует в каждой группе внутригрупповая дисперсия σ j 2 .
.Между общей дисперсией σ 0 2 , внутригрупповой дисперсией σ 2 и межгрупповой дисперсией
1.2 Однофакторный дисперсионный анализ
Однофакторная дисперсионная модель имеет вид:
x ij = μ + F j + ε ij , (1)
где х ij – значение исследуемой переменой, полученной на i-м уровне фактора (i=1,2,...,т) c j-м порядковым номером (j=1,2,...,n);
F i – эффект, обусловленный влиянием i-го уровня фактора;
ε ij – случайная компонента, или возмущение, вызванное влиянием неконтролируемых факторов, т.е. вариацией переменой внутри отдельного уровня.
Основные предпосылки дисперсионного анализа:
Математическое ожидание возмущения ε ij равно нулю для любых i, т.е.
M(ε ij) = 0; (2)
Возмущения ε ij взаимно независимы;
Дисперсия переменной x ij (или возмущения ε ij) постоянна для
любых i, j, т.е.
D(ε ij) = σ 2 ; (3)
Переменная x ij (или возмущение ε ij) имеет нормальный закон
распределения N(0;σ 2).
Влияние уровней фактора может быть как фиксированным или систематическим (модель I), так и случайным (модель II).
Пусть, например, необходимо выяснить, имеются ли существенные различия между партиями изделий по некоторому показателю качества, т.е. проверить влияние на качество одного фактора - партии изделий. Если включить в исследование все партии сырья, то влияние уровня такого фактора систематическое (модель I), а полученные выводы применимы только к тем отдельным партиям, которые привлекались при исследовании. Если же включить только отобранную случайно часть партий, то влияние фактора случайное (модель II). В многофакторных комплексах возможна смешанная модель III, в которой одни факторы имеют случайные уровни, а другие – фиксированные.
В практической деятельности врачей при проведении медико-биологических, социологических и экспериментальных исследований возникает необходимость установить влияние факторов на результаты изучения состояния здоровья населения, при оценке профессиональной деятельности, эффективности нововведений.
Существует ряд статистических методов, позволяющих определить силу, направление, закономерности влияния факторов на результат в генеральной или выборочной совокупностях (расчет критерия I, корреляционный анализ, регрессия, Χ 2 - (критерий согласия Пирсона и др.). Дисперсионный анализ был разработан и предложен английским ученым, математиком и генетиком Рональдом Фишером в 20-х годах XX века.
Дисперсионный анализ чаще используют в научно-практических исследованиях общественного здоровья и здравоохранения для изучения влияния одного или нескольких факторов на результативный признак. Он основан на принципе "отражения разнообразий значений факторного(ых) на разнообразии значений результативного признака" и устанавливает силу влияния фактора(ов) в выборочных совокупностях.
Сущность метода дисперсионного анализа заключается в измерении отдельных дисперсий (общая, факториальная, остаточная), и дальнейшем определении силы (доли) влияния изучаемых факторов (оценки роли каждого из факторов, либо их совместного влияния) на результативный(е) признак(и).
Дисперсионный анализ - это статистический метод оценки связи между факторными и результативным признаками в различных группах, отобранный случайным образом, основанный на определении различий (разнообразия) значений признаков. В основе дисперсионного анализа лежит анализ отклонений всех единиц исследуемой совокупности от среднего арифметического. В качестве меры отклонений берется дисперсия (В)- средний квадрат отклонений. Отклонения, вызываемые воздействием факторного признака (фактора) сравниваются с величиной отклонений, вызываемых случайными обстоятельствами. Если отклонения, вызываемые факторным признаком, более существенны, чем случайные отклонения, то считается, что фактор оказывает существенное влияние на результативный признак.
Для того, чтобы вычислить дисперсию значения отклонений каждой варианты (каждого зарегистрированного числового значения признака) от среднего арифметического возводят в квадрат. Тем самым избавляются от отрицательных знаков. Затем эти отклонения (разности) суммируют и делят на число наблюдений, т.е. усредняют отклонения. Таким образом, получают значения дисперсий.
Важным методическим значением для применения дисперсионного анализа является правильное формирование выборки. В зависимости от поставленной цели и задач выборочные группы могут формироваться случайным образом независимо друг от друга (контрольная и экспериментальная группы для изучения некоторого показателя, например, влияние высокого артериального давления на развитие инсульта). Такие выборки называются независимыми.
Нередко результаты воздействия факторов исследуются у одной и той же выборочной группы (например, у одних и тех же пациентов) до и после воздействия (лечение, профилактика, реабилитационные мероприятия), такие выборки называются зависимыми.
Дисперсионный анализ, в котором проверяется влияние одного фактора, называется однофакторным (одномерный анализ). При изучении влияния более чем одного фактора используют многофакторный дисперсионный анализ (многомерный анализ).
Факторные признаки - это те признаки, которые влияют на изучаемое явление.
Результативные признаки - это те признаки, которые изменяются под влиянием факторных признаков.
Для проведения дисперсионного анализа могут использоваться как качественные (пол, профессия), так и количественные признаки (число инъекций, больных в палате, число койко-дней).
Методы дисперсионного анализа:
- Метод по Фишеру (Fisher) - критерий F (значения F см. в приложении N 1);
Метод применяется в однофакторном дисперсионном анализе, когда совокупная дисперсия всех наблюдаемых значений раскладывается на дисперсию внутри отдельных групп и дисперсию между группами. - Метод "общей линейной модели".
В его основе лежит корреляционный или регрессионный анализ, применяемый в многофакторном анализе.
Обычно в медико-биологических исследованиях используются только однофакторные, максимум двухфакторные дисперсионные комплексы. Многофакторные комплексы можно исследовать, последовательно анализируя одно- или двухфакторные комплексы, выделяемые из всей наблюдаемой совокупности.
Условия применения дисперсионного анализа:
- Задачей исследования является определение силы влияния одного (до 3) факторов на результат или определение силы совместного влияния различных факторов (пол и возраст, физическая активность и питание и т.д.).
- Изучаемые факторы должны быть независимые (несвязанные) между собой. Например, нельзя изучать совместное влияние стажа работы и возраста, роста и веса детей и т.д. на заболеваемость населения.
- Подбор групп для исследования проводится рандомизированно (случайный отбор). Организация дисперсионного комплекса с выполнением принципа случайности отбора вариантов называется рандомизацией (перев. с англ. - random), т.е. выбранные наугад.
- Можно применять как количественные, так и качественные (атрибутивные) признаки.
При проведении однофакторного дисперсионного анализа рекомендуется (необходимое условие применения):
- Нормальность распределения анализируемых групп или соответствие выборочных групп генеральным совокупностям с нормальным распределением.
- Независимость (не связанность) распределения наблюдений в группах.
- Наличие частоты (повторность) наблюдений.
Нормальность распределения определяется кривой Гаусса (Де Мавура), которую можно описать функцией у = f(х), так как она относится к числу законов распределения, используемых для приближенного описания явлений, которые носят случайный, вероятностный характер. Предмет медико-биологических исследований - явления вероятностного характера, нормальное распределение в таких исследованиях встречается весьма часто.
Принцип применения метода дисперсионного анализа
Сначала формулируется нулевая гипотеза, то есть предполагается, что исследуемые факторы не оказывают никакого влияния на значения результативного признака и полученные различия случайны.
Затем определяем, какова вероятность получить наблюдаемые (или более сильные) различия при условии справедливости нулевой гипотезы.
Если эта вероятность мала*, то мы отвергаем нулевую гипотезу и заключаем, что результаты исследования статистически значимы. Это
еще не означает, что доказано действие именно изучаемых факторов (это вопрос, прежде всего, планирования исследования), но все же
маловероятно, что результат обусловлен случайностью.
__________________________________
* Максимальную приемлемую вероятность отвергнуть верную нулевую гипотезу называют уровнем значимости и обозначают α = 0,05.
При выполнении всех условий применения дисперсионного анализа, разложение общей дисперсии математически выглядит следующим образом:
D oбщ. = D факт + D ост. ,
D oбщ. - общая дисперсия наблюдаемых значений (вариант), характеризуется разбросом вариант от общего среднего. Измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловивших эту вариацию. Общее разнообразие складывается из межгруппового и внутригруппового;
D факт - факторная (межгрупповая) дисперсия, характеризуется различием средних в каждой группе и зависит от влияния исследуемого фактора, по которому дифференцируется каждая группа. Например, в группах различных по этиологическому фактору клинического течения пневмонии средний уровень проведенного койко-дня неодинаков - наблюдается межгрупповое разнообразие.
D ост. - остаточная (внутригрупповая) дисперсия, которая характеризует рассеяние вариант внутри групп. Отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неуточненных факторов и не зависящую от признака - фактора, положенного в основание группировки. Вариация изучаемого признака зависит от силы влияния каких-то неучтенных случайных факторов, как от организованных (заданных исследователем), так и от случайных (неизвестных) факторов.
Поэтому общая вариация (дисперсия) слагается из вариации, вызванной организованными (заданными) факторами, называемыми факториальной вариацией и неорганизованными факторами, т.е. остаточной вариацией (случайной, неизвестной).
Классический дисперсионный анализ проводится по следующим этапам:
- Построение дисперсионного комплекса.
- Вычисление средних квадратов отклонений.
- Вычисление дисперсии.
- Сравнение факторной и остаточной дисперсий.
- Оценка результатов с помощью теоретических значений распределения Фишера-Снедекора (приложение N 1).
АЛГОРИТМ ПРОВЕДЕНИЯ ДИСПЕРСИОННОГО АНАЛИЗА ПО УПРОЩЕННОМУ ВАРИАНТУ
Алгоритм проведения дисперсионного анализа по упрощенному способу позволяет получить те же результаты, но расчеты выполняются значительно проще:
I этап. Построение дисперсионного комплекса
Построение дисперсионного комплекса означает построение таблицы, в которой были бы четко разграничены факторы, результативный признак и подбор наблюдений (больных) в каждую группу.
Однофакторный комплекс состоит из нескольких градаций одного фактора (А). Градации - это выборки из разных генеральных совокупностей (А1, А2, АЗ).
Двухфакторный комплекс - состоит из нескольких градаций двух факторов в комбинации между собой. Этиологические факторы заболеваемостью пневмонией те же (А1, А2, АЗ) в сочетании с разными формами клинического течения пневмонии (Н1 - острое, Н2 - хроническое).
| Результативный признак (количество койко-дней в среднем) | Этиологические факторы развития пневмоний | |||||
| А1 | А2 | А3 | ||||
| Н1 | Н2 | Н1 | Н2 | Н1 | Н2 | |
| М = 14 дней | ||||||
II этап. Вычисление общей средней (М обш)
Вычисление суммы вариант по каждой градации факторов: Σ Vj = V 1 + V 2 + V 3
Вычисление общей суммы вариант (Σ V общ) по всем градациям факторного признака: Σ V общ = Σ Vj 1 + Σ Vj 2 + Σ Vj 3
Вычисление средней групповой (М гр.) факторного признака: М гр. = Σ Vj / N,
где N - сумма числа наблюдений по всем градациям факторного I признака (Σn по группам).
III этап. Расчет дисперсий:
При соблюдении всех условий применения дисперсионного анализа математическая формула выглядит следующим образом:
D oбщ. = D факт + D ост.
D oбщ. - общая дисперсия, характеризуется разбросом вариант (наблюдаемых значений) от общего среднего;
D факт. - факторная (межгрупповая) дисперсия, характеризует разброс групповых средних от общего среднего;
D ост. - остаточная (внутригрупповая) дисперсия, характеризует рассеяние вариант внутри групп.
- Вычисление факториальной дисперсии (D факт.): D факт. = Σ h - H
- Вычисление h проводится по формуле: h = (Σ Vj) / N
- Вычисление Н проводится по формуле: H = (Σ V) 2 / N
- Вычисление остаточной дисперсии: D ост. = (Σ V) 2 - Σ h
- Вычисление общей дисперсии: D oбщ. = (Σ V) 2 - Σ H
IV этап. Расчет основного показателя силы влияния изучаемого фактора Показатель силы влияния (η 2) факторного признака на результат определяется долей факториальной дисперсии (D факт.) в общей дисперсии (D oбщ.), η 2 (эта) - показывает какую долю занимает влияние изучаемого фактора среди всех других факторов и определяется по формуле:
V этап. Определение достоверности результатов исследования методом Фишера проводят по формуле:

F - критерий Фишера;
F st. - табличное значение (см.приложение 1).
σ 2 факт, σ 2 ост. - факториальная и остаточная девиаты (от лат. de - от, via - дорога) - отклонение от средней линии, определяются по формулам:

r - число градаций факторного признака.
Сравнение критерия Фишера (F) со стандартным (табличным) F проводят по графам таблицы с учетом степеней свободы:
v 1 = n - 1
v 2 = N - 1
По горизонтали определяют v 1 по вертикали - v 2 , на их пересечении определяют табличное значение F, где верхнее табличное значение р ≥ 0,05, а нижнее соответствует р > 0,01, и сравнивают с вычисленным критерием F. Если значение вычисленного критерия F равно или больше табличного, то результаты достоверны и Н 0 не отвергается.
Условие задачи:
На предприятии Н. повысился уровень травматизма в связи с чем врач провел исследование отдельных факторов, среди которых изучался стаж работы работающих в цехах. Выборки сделаны на предприятии Н. из 4 цехов с близкими условиями и характером труда. Уровни травматизма рассчитаны на 100 работающих за прошлый год.
При исследовании фактора рабочего стажа получены следующие данные:
На основании данных проведённого исследования была выдвинута нулевая гипотеза (Н 0) о влиянии стажа работы на уровень травматизма работников предприятия А.
Задание
Подтвердите или опровергните нулевую гипотезу методом одно-факторного дисперсионного анализа:
- определите силу влияния;
- оцените достоверность влияния фактор.
Этапы применения дисперсионного анализа
для определения влияния фактора (стажа работы) на результат (уровень
травматизма)

Вывод. В выборочном комплексе выявлено, что сила влияния стажа работы на уровень травматизма составляет 80% в общем числе других факторов. Для всех цехов завода можно с вероятностью 99,7% (13,3 > 8,7) утверждать, что стаж работы влияет на уровень травматизма.
Таким образом, нулевая гипотеза (Н 0) не отвергается и влияние стажа работы на уровень травматизма в цехах завода А считается доказанным.
Значение F (критерий Фишера) стандартного при р ≥ 0,05 (верхнее значение) при р ≥ 0,01 (нижнее значение)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
| 6 | 6,0 13,4 | 5,1 10,9 | 4,8 9,8 | 4,5 9,2 | 4,4 8,8 | 4,3 8,5 | 4,2 8,3 | 4,1 8,1 | 4,1 8,0 | 4,1 7,9 | 4,0 7,8 |
| 7 | 5,6 12,3 | 4,7 9,6 | 4,4 8,5 | 4,1 7,9 | 4,0 7,5 | 3,9 7,2 | 3,8 7,0 | 3,7 6,8 | 3,7 6,7 | 3,6 6,6 | 3,6 6,5 |
| 8 | 5,3 11,3 | 4,6 8,7 | 4,1 7,6 | 3,8 7,0 | 3,7 6,6 | 3,6 6,4 | 3,5 6,2 | 3,4 6,0 | 3,4 5,9 | 3,3 5,8 | 3,1 5,7 |
| 9 | 5,1 10,6 | 4,3 8,0 | 3,6 7,0 | 3,6 6,4 | 3,5 6,1 | 3,4 5,8 | 3,3 5,6 | 3,2 5,5 | 3,2 5,4 | 3,1 5,3 | 3,1 5,2 |
| 10 | 5,0 10,0 | 4,1 7,9 | 3,7 6,6 | 3,5 6,0 | 3,3 5,6 | 3,2 5,4 | 3,1 5,2 | 3,1 5,1 | 3,0 5,0 | 2,9 4,5 | 2,9 4,8 |
| 11 | 4,8 9,7 | 4,0 7,2 | 3,6 6,2 | 3,6 5,7 | 3,2 5,3 | 3,1 5,1 | 3,0 4,9 | 3,0 4,7 | 2,9 4,6 | 2,9 4,5 | 2,8 4,5 |
| 12 | 4,8 9,3 | 3,9 6,9 | 3,5 6,0 | 3,3 5,4 | 3,1 5,1 | 3,0 4,7 | 2,9 4,7 | 2,9 4,5 | 2,8 4,4 | 2,8 4,3 | 2,7 4,2 |
| 13 | 4,7 9,1 | 3,8 6,7 | 3,4 5,7 | 3,2 5,2 | 3,0 4,9 | 2,9 4,6 | 2,8 4,4 | 2,8 4,3 | 2,7 4,2 | 2,7 4,1 | 2,6 4,0 |
| 14 | 4,6 8,9 | 3,7 6,5 | 3,3 5,6 | 3,1 5,0 | 3,0 4,7 | 2,9 4,5 | 2,8 4,3 | 2,7 4,1 | 2,7 4,0 | 2,6 3,9 | 2,6 3,9 |
| 15 | 4,5 8,7 | 3,7 6,4 | 3,3 5,4 | 3,1 4,9 | 2,9 4,6 | 2,8 4,3 | 2,7 4,1 | 2,6 4,0 | 2,6 3,9 | 2,5 3,8 | 2,5 3,7 |
| 16 | 4,5 8,5 | 3,6 6,2 | 3,2 5,3 | 3,0 4,8 | 2,9 4,4 | 2,7 4,2 | 2,7 4,0 | 2,6 3,9 | 2,5 3,8 | 2,5 3,7 | 2,5 3,6 |
| 17 | 4,5 8,4 | 3,6 6,1 | 3,2 5,2 | 3,0 4,7 | 2,8 4,3 | 2,7 4,1 | 2,6 3,9 | 2,6 3,8 | 2,5 3,8 | 2,5 3,6 | 2,4 3,5 |
| 18 | 4,4 8,3 | 3,5 6,0 | 3,2 5,1 | 2,9 4,6 | 2,8 4,2 | 2,7 4,0 | 2,6 3,8 | 2,5 3,7 | 2,7 3,6 | 2,4 3,6 | 3,4 3,5 |
| 19 | 4,4 8,2 | 3,5 5,9 | 3,1 5,0 | 2,9 4,5 | 2,7 4,2 | 2,6 3,9 | 2,5 3,8 | 2,5 3,6 | 2,4 3,5 | 2,4 3,4 | 2,3 3,4 |
| 20 | 4,3 8,1 | 3,5 5,8 | 3,1 4,9 | 2,9 4,4 | 2,7 4,1 | 2,6 3,9 | 2,5 3,7 | 2,4 3,6 | 2,4 3,4 | 2,3 3,4 | 2,3 3,3 |
- Власов В.В. Эпидемиология. - М.: ГЭОТАР-МЕД, 2004. 464 с.
- Архипова ГЛ., Лаврова И.Г., Трошина И.М. Некоторые современные методы статистического анализа в медицине. - М.: Метроснаб, 1971. - 75 с.
- Зайцев В.М., Лифляндский В.Г., Маринкин В.И. Прикладная медицинская статистика. - СПб.: ООО "Издательство ФОЛИАНТ", 2003. - 432 с.
- Платонов А.Е. Статистический анализ в медицине и биологии: задачи, терминология, логика, компьютерные методы. - М.: Издательство РАМН, 2000. - 52 с.
- Плохинский Н.А. Биометрия. - Издательство Сибирского отделения АН СССР Новосибирск. - 1961. - 364 с.
Дисперсионный анализ
Курсовая работа по дисциплине: «Системный анализ»
Исполнитель студент гр. 99 ИСЭ-2 Жбанов В.В.
Оренбургский государственный университет
Факультет информационных технологий
Кафедра прикладной информатики
г. Оренбург-2003
Введение
Цель работы: познакомится с таким статистическим методом, как дисперсионный анализ.
Дисперсионный анализ (от латинского Dispersio – рассеивание) – статистический метод, позволяющий анализировать влияние различных факторов на исследуемую переменную. Метод был разработан биологом Р. Фишером в 1925 году и применялся первоначально для оценки экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость дисперсионного анализа для экспериментов в психологии, педагогике, медицине и др.
Целью дисперсионного анализа является проверка значимости различия между средними с помощью сравнения дисперсий. Дисперсию измеряемого признака разлагают на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение таких слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их комбинации /1/.
При истинности нулевой гипотезы (о равенстве средних в нескольких группах наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии.
При проведении исследования рынка часто встает вопрос о сопоставимости результатов. Например, проводя опросы по поводу потребления какого-либо товара в различных регионах страны, необходимо сделать выводы, на сколько данные опроса отличаются или не отличаются друг от друга. Сопоставлять отдельные показатели не имеет смысла и поэтому процедура сравнения и последующей оценки производится по некоторым усредненным значениям и отклонениям от этой усредненной оценки. Изучается вариация признака. За меру вариации может быть принята дисперсия. Дисперсия σ 2 – мера вариации, определяемая как средняя из отклонений признака, возведенных в квадрат.
На практике часто возникают задачи более общего характера – задачи проверки существенности различий средних выборочных нескольких совокупностей. Например, требуется оценить влияние различного сырья на качество производимой продукции, решить задачу о влиянии количества удобрений на урожайность с/х продукции.
Иногда дисперсионный анализ применяется, чтобы установить однородность нескольких совокупностей (дисперсии этих совокупностей одинаковы по предположению; если дисперсионный анализ покажет, что и математические ожидания одинаковы, то в этом смысле совокупности однородны). Однородные же совокупности можно объединить в одну и тем самым получить о ней более полную информацию, следовательно, и более надежные выводы /2/.
1 Дисперсионный анализ
1.1 Основные понятия дисперсионного анализа
В процессе наблюдения за исследуемым объектом качественные факторы произвольно или заданным образом изменяются. Конкретная реализация фактора (например, определенный температурный режим, выбранное оборудование или материал) называется уровнем фактора или способом обработки. Модель дисперсионного анализа с фиксированными уровнями факторов называют моделью I, модель со случайными факторами - моделью II. Благодаря варьированию фактора можно исследовать его влияние на величину отклика. В настоящее время общая теория дисперсионного анализа разработана для моделей I.
В зависимости от количества факторов, определяющих вариацию результативного признака, дисперсионный анализ подразделяют на однофакторный и многофакторный.
Основными схемами организации исходных данных с двумя и более факторами являются:
Перекрестная классификация, характерная для моделей I, в которых каждый уровень одного фактора сочетается при планировании эксперимента с каждой градацией другого фактора;
Иерархическая (гнездовая) классификация, характерная для модели II, в которой каждому случайному, наудачу выбранному значению одного фактора соответствует свое подмножество значений второго фактора.
Если одновременно исследуется зависимость отклика от качественных и количественных факторов, т.е. факторов смешанной природы, то используется ковариационный анализ /3/.
Таким образом, данные модели отличаются между собой способом выбора уровней фактора, что, очевидно, в первую очередь влияет на возможность обобщения полученных экспериментальных результатов. Для дисперсионного анализа однофакторных экспериментов различие этих двух моделей не столь существенно, однако в многофакторном дисперсионном анализе оно может оказаться весьма важным.
При проведении дисперсионного анализа должны выполняться следующие статистические допущения: независимо от уровня фактора величины отклика имеют нормальный (Гауссовский) закон распределения и одинаковую дисперсию. Такое равенство дисперсий называется гомогенностью. Таким образом, изменение способа обработки сказывается лишь на положении случайной величины отклика, которое характеризуется средним значением или медианой. Поэтому все наблюдения отклика принадлежат сдвиговому семейству нормальных распределений.
Говорят, что техника дисперсионного анализа является "робастной". Этот термин, используемый статистиками, означает, что данные допущения могут быть в некоторой степени нарушены, но несмотря на это, технику можно использовать.
При неизвестном законе распределения величин отклика используют непараметрические (чаще всего ранговые) методы анализа.
В основе дисперсионного анализа лежит разделение дисперсии на части или компоненты. Вариацию, обусловленную влиянием фактора, положенного в основу группировки, характеризует межгрупповая дисперсия σ 2 . Она является мерой вариации частных средних по группам вокруг общей средней и определяется по формуле:
 ,
,
где k - число групп;
n j - число единиц в j-ой группе;
Частная средняя по j-ой группе;
Общая средняя по совокупности единиц.
Вариацию, обусловленную влиянием прочих факторов, характеризует в каждой группе внутригрупповая дисперсия σ j 2 .
 .
.
Между общей дисперсией σ 0 2 , внутригрупповой дисперсией σ 2 и межгрупповой дисперсией существует соотношение:
σ 0 2 = + σ 2 .
Внутригрупповая дисперсия объясняет влияние неучтенных при группировке факторов, а межгрупповая дисперсия объясняет влияние факторов группировки на среднее значение по группе /2/.
1.2 Однофакторный дисперсионный анализ
Однофакторная дисперсионная модель имеет вид:
x ij = μ + F j + ε ij , (1)
где х ij – значение исследуемой переменой, полученной на i-м уровне фактора (i=1,2,...,т) c j-м порядковым номером (j=1,2,...,n);
F i – эффект, обусловленный влиянием i-го уровня фактора;
ε ij – случайная компонента, или возмущение, вызванное влиянием неконтролируемых факторов, т.е. вариацией переменой внутри отдельного уровня.
Основные предпосылки дисперсионного анализа:
Математическое ожидание возмущения ε ij равно нулю для любых i, т.е.
M(ε ij) = 0; (2)
Возмущения ε ij взаимно независимы;
Дисперсия переменной x ij (или возмущения ε ij) постоянна для
любых i, j, т.е.
D(ε ij) = σ 2 ; (3)
Переменная x ij (или возмущение ε ij) имеет нормальный закон
распределения N(0;σ 2).
Влияние уровней фактора может быть как фиксированным или систематическим (модель I), так и случайным (модель II).
Пусть, например, необходимо выяснить, имеются ли существенные различия между партиями изделий по некоторому показателю качества, т.е. проверить влияние на качество одного фактора - партии изделий. Если включить в исследование все партии сырья, то влияние уровня такого фактора систематическое (модель I), а полученные выводы применимы только к тем отдельным партиям, которые привлекались при исследовании. Если же включить только отобранную случайно часть партий, то влияние фактора случайное (модель II). В многофакторных комплексах возможна смешанная модель III, в которой одни факторы имеют случайные уровни, а другие – фиксированные.
Пусть имеется m партий изделий. Из каждой партии отобрано соответственно n 1 , n 2 , …, n m изделий (для простоты полагается, что n 1 =n 2 =...=n m =n). Значения показателя качества этих изделий представлены в матрице наблюдений:
x 11 x 12 … x 1n
x 21 x 22 … x 2n
………………… = (x ij), (i = 1,2, …, m; j = 1,2, …, n).
x m 1 x m 2 … x mn
Необходимо проверить существенность влияния партий изделий на их качество.
Если полагать, что элементы строк матрицы наблюдений – это численные значения случайных величин Х 1 ,Х 2 ,...,Х m , выражающих качество изделий и имеющих нормальный закон распределения с математическими ожиданиями соответственно a 1 ,а 2 ,...,а m и одинаковыми дисперсиями σ 2 , то данная задача сводится к проверке нулевой гипотезы Н 0: a 1 =a 2 =...= а m , осуществляемой в дисперсионном анализе.
Усреднение по какому-либо индексу обозначено звездочкой (или точкой) вместо индекса, тогда средний показатель качества изделий i-й партии, или групповая средняя для i-го уровня фактора, примет вид:
где i * – среднее значение по столбцам;
Ij – элемент матрицы наблюдений;
n – объем выборки.
А общая средняя:
 . (5)
. (5)
Сумма квадратов отклонений наблюдений х ij от общей средней ** выглядит так:
 2
=
2
= 2
+
2
+ 2
+
2
+
2 2
. (6)
2
. (6)
Q = Q 1 + Q 2 + Q 3 .
Последнее слагаемое равно нулю
так как сумма отклонений значений переменной от ее средней равна нулю, т.е.
 2
=0.
2
=0.
Первое слагаемое можно записать в виде:

В результате получается тождество:
Q = Q 1 + Q 2 , (8)
где  - общая, или полная, сумма квадратов отклонений;
- общая, или полная, сумма квадратов отклонений;
 - сумма квадратов отклонений групповых средних от общей средней, или межгрупповая (факторная) сумма квадратов отклонений;
- сумма квадратов отклонений групповых средних от общей средней, или межгрупповая (факторная) сумма квадратов отклонений;
 - сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая (остаточная) сумма квадратов отклонений.
- сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая (остаточная) сумма квадратов отклонений.
В разложении (8) заключена основная идея дисперсионного анализа. Применительно к рассматриваемой задаче равенство (8) показывает, что общая вариация показателя качества, измеренная суммой Q, складывается из двух компонент – Q 1 и Q 2 , характеризующих изменчивость этого показателя между партиями (Q 1) и изменчивость внутри партий (Q 2), характеризующих одинаковую для всех партий вариацию под воздействием неучтенных факторов.
В дисперсионном анализе анализируются не сами суммы квадратов отклонений, а так называемые средние квадраты, являющиеся несмещенными оценками соответствующих дисперсий, которые получаются делением сумм квадратов отклонений на соответствующее число степеней свободы.
Число степеней свободы определяется как общее число наблюдений минус число связывающих их уравнений. Поэтому для среднего квадрата s 1 2 , являющегося несмещенной оценкой межгрупповой дисперсии, число степеней свободы k 1 =m-1, так как при его расчете используются m групповых средних, связанных между собой одним уравнением (5). А для среднего квадрата s22, являющегося несмещенной оценкой внутригрупповой дисперсии, число степеней свободы k2=mn-m, т.к. при ее расчете используются все mn наблюдений, связанных между собой m уравнениями (4).
Таким образом:
Если найти математические ожидания средних квадратов и , подставить в их формулы выражение xij (1) через параметры модели, то получится:
 (9)
(9)
т.к. с учетом свойств математического ожидания
 а
а

 (10)
(10)
Для модели I с фиксированными уровнями фактора F i (i=1,2,...,m) – величины неслучайные, поэтому
M(S) = 2 /(m-1) +σ 2 .
Гипотеза H 0 примет вид F i = F * (i = 1,2,...,m), т.е. влияние всех уровней фактора одно и то же. В случае справедливости этой гипотезы
M(S)= M(S)= σ 2 .
Для случайной модели II слагаемое F i в выражении (1) – величина случайная. Обозначая ее дисперсией

получим из (9)
![]() (11)
(11)
и, как и в модели I
В таблице 1.1 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.1 – Базовая таблица дисперсионного анализа
| Компоненты дисперсии |
Сумма квадратов |
Число степеней свободы |
Средний квадрат |
Математическое ожидание среднего квадрата |
| Межгрупповая |
|
|
||
| Внутригрупповая |
|
|||
|
|



Гипотеза H 0 примет вид σ F 2 =0. В случае справедливости этой гипотезы
M(S)= M(S)= σ 2 .
В случае однофакторного комплекса как для модели I, так и модели II средние квадраты S 2 и S 2 , являются несмещенными и независимыми оценками одной и той же дисперсии σ 2 .
Следовательно, проверка нулевой гипотезы H 0 свелась к проверке существенности различия несмещенных выборочных оценок S и S дисперсии σ 2 .
Гипотеза H 0 отвергается, если фактически вычисленное значение статистики F = S/S больше критического F α: K 1: K 2 , определенного на уровне значимости α при числе степеней свободы k 1 =m-1 и k 2 =mn-m, и принимается, если F < F α: K 1: K 2 .
F- распределение Фишера (для x > 0) имеет следующую функцию плотности (для = 1, 2, ...; = 1, 2, ...):
где - степени свободы;
Г - гамма-функция.
Применительно к данной задаче опровержение гипотезы H 0 означает наличие существенных различий в качестве изделий различных партий на рассматриваемом уровне значимости.
Для вычисления сумм квадратов Q 1 , Q 2 , Q часто бывает удобно использовать следующие формулы:
 (12)
(12)
 (13)
(13)
 (14)
(14)
т.е. сами средние, вообще говоря, находить не обязательно.
Таким образом, процедура однофакторного дисперсионного анализа состоит в проверке гипотезы H 0 о том, что имеется одна группа однородных экспериментальных данных против альтернативы о том, что таких групп больше, чем одна. Под однородностью понимается одинаковость средних значений и дисперсий в любом подмножестве данных. При этом дисперсии могут быть как известны, так и неизвестны заранее. Если имеются основания полагать, что известная или неизвестная дисперсия измерений одинакова по всей совокупности данных, то задача однофакторного дисперсионного анализа сводится к исследованию значимости различия средних в группах данных /1/.
1.3 Многофакторный дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным дисперсионным анализом нет. Многофакторный анализ не меняет общую логику дисперсионного анализа, а лишь несколько усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из факторов по отдельности, следует оценивать и их совместное действие. Таким образом, то новое, что вносит в анализ данных многофакторный дисперсионный анализ, касается в основном возможности оценить межфакторное взаимодействие. Тем не менее, по-прежнему остается возможность оценивать влияние каждого фактора в отдельности. В этом смысле процедура многофакторного дисперсионного анализа (в варианте ее компьютерного использования) несомненно более экономична, поскольку всего за один запуск решает сразу две задачи: оценивается влияние каждого из факторов и их взаимодействие /3/.
Общая схема двухфакторного эксперимента, данные которого обрабатываются дисперсионным анализом имеет вид:
 |
Рисунок 1.1 – Схема двухфакторного эксперимента
Данные, подвергаемые многофакторному дисперсионному анализу, часто обозначают в соответствии с количеством факторов и их уровней.
Предположив, что в рассматриваемой задаче о качестве различных m партий изделия изготавливались на разных t станках и требуется выяснить, имеются ли существенные различия в качестве изделий по каждому фактору:
А - партия изделий;
B - станок.
В результате получается переход к задаче двухфакторного дисперсионного анализа.
Все данные представлены в таблице 1.2, в которой по строкам - уровни A i фактора А, по столбцам - уровни B j фактора В, а в соответствующих ячейках, таблицы находятся значения показателя качества изделий x ijk (i=1,2,...,m; j=1,2,...,l; k=1,2,...,n).
Таблица 1.2 – Показатели качества изделий
| x 11l ,…,x 11k |
x 12l ,…,x 12k |
x 1jl ,…,x 1jk |
x 1ll ,…,x 1lk |
|||
| x 2 1l ,…,x 2 1k |
x 22l ,…,x 22k |
x 2jl ,…,x 2jk |
x 2ll ,…,x 2lk |
|||
| x i1l ,…,x i1k |
x i2l ,…,x i2k |
x ijl ,…,x ijk |
x jll ,…,x jlk |
|||
| x m1l ,…,x m1k |
x m2l ,…,x m2k |
x mjl ,…,x mjk |
x mll ,…,x mlk |
Двухфакторная дисперсионная модель имеет вид:
x ijk =μ+F i +G j +I ij +ε ijk , (15)
где x ijk - значение наблюдения в ячейке ij с номером k;
μ - общая средняя;
F i - эффект, обусловленный влиянием i-го уровня фактора А;
G j - эффект, обусловленный влиянием j-го уровня фактора В;
I ij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели (15);
ε ijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки.
Предполагается, что ε ijk имеет нормальный закон распределения N(0; с 2), а все математические ожидания F * , G * , I i * , I * j равны нулю.
Групповые средние находятся по формулам:
В ячейке:
по строке:

по столбцу:

общая средняя:

В таблице 1.3 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.3 – Базовая таблица дисперсионного анализа
| Компоненты дисперсии |
Сумма квадратов |
Число степеней свободы |
Средние квадраты |
| Межгрупповая (фактор А) |
|
||
| Межгрупповая (фактор B) |
|
||
| Взаимодействие |
|
|
|
| Остаточная |
|
|
|
|
|






Проверка нулевых гипотез HA, HB, HAB об отсутствии влияния на рассматриваемую переменную факторов А, B и их взаимодействия AB осуществляется сравнением отношений , , (для модели I с фиксированными уровнями факторов) или отношений , , (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера – Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
Если n=1, т.е. при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть проверены так как выпадает компонента Q3 из общей суммы квадратов отклонений, а с ней и средний квадрат , так как в этом случае не может быть речи о взаимодействии факторов.
С точки зрения техники вычислений для нахождения сумм квадратов Q 1 , Q 2 , Q 3 , Q 4 , Q целесообразнее использовать формулы:




Q 3 = Q – Q 1 – Q 2 – Q 4 .
Отклонение от основных предпосылок дисперсионного анализа - нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) - не сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы /1/.
2 Применение дисперсионного анализа в различных процессах и исследованиях
2.1 Использование дисперсионного анализа при изучении миграционных процессов
Миграция - сложное социальное явление, во многом определяющее экономическую и политическую стороны жизни общества. Исследование миграционных процессов связано с выявлением факторов заинтересованности, удовлетворенности условиями труда, и оценкой влияния полученных факторов на межгрупповое движение населения.
λ ij =c i q ij a j ,
где λ ij – интенсивность переходов из исходной группы i (выхода) в новую j (входа);
c i – возможность и способности покинуть группу i (c i ≥0);
q ij – привлекательность новой группы по сравнению с исходной (0≤q ij ≤1);
a j – доступность группы j (a j ≥0).
ν ij ≈ n i λ ij =n i c i q ij a j . (16)
На практике для отдельного человека вероятность p перехода в другую группу мала, а численность рассматриваемой группы n велика. В этом случае действует закон редких событий, то есть пределом ν ij является распределение Пуассона с параметром μ=np:
![]() .
.
С ростом μ распределение приближается к нормальному. Преобразованную же величину √ν ij можно считать нормально распределенной.
Если прологарифмировать выражение (16) и сделать необходимые замены переменных, то можно получить модель дисперсионного анализа:
ln√ν ij =½lnν ij =½(lnn i +lnc i +lnq ij +lna j)+ε ij ,
X i,j =2ln√ν ij -lnn i -lnq ij ,
X i,j =C i +A j +ε.
Значения C i и A j позволяют получить модель двухфакторного дисперсионного анализа с одним наблюдением в клетке. Обратным преобразованием из C i и A j вычисляются коэффициенты c i и a j .
При проведении дисперсионного анализа в качестве значений результативного признака Y следует взять величины:
Х=(Х 1,1 +Х 1,2 +:+Х mi,mj)/mimj,
где mimj- оценка математического ожидания Х i,j ;
Х mi и Х mj - соответственно количество групп выхода и входа.
Уровнями фактора I будут mi групп выхода, уровнями фактора J - mj групп входа. Предполагается mi=mj=m. Встает задача проверки гипотез H I
и H J
о равенствах математических ожиданий величины Y при уровнях I i
и при уровнях J j
, i,j=1,…,m. Проверка гипотезы H I
основывается на сравнении величин несмещенных оценок дисперсии s I
2
и s o
2
. Если гипотеза H I
верна, то величина F (I)
= s I
2
/s o
2
имеет распределение Фишера с числами степеней свободы k 1
=m-1 и k 2
=(m-1)(m-1). Для заданного уровня значимости α находится правосторонняя критическая точка x пр,α
кр. Если числовое значение F (I)
чис
величины попадает в интервал (x пр,α
кр, +∞), то гипотеза H I
отвергается и считается, что фактор I влияет на результативный признак. Степень этого влияния по результатам наблюдений измеряется выборочным коэффициентом детерминации, который показывает, какая доля дисперсии результативного признака в выборке обусловлена влиянием на него фактора I. Если же F (I)
чис
2.2 Принципы математико-статистического анализа данных медико-биологических исследований
В зависимости от поставленной задачи, объема и характера материала, вида данных и их связей находится выбор методов математической обработки на этапах как предварительного (для оценки характера распределения в исследуемой выборке), так и окончательного анализа в соответствии с целями исследования. Крайне важным аспектом является проверка однородности выбранных групп наблюдения, в том числе контрольных, что может быть проведено или экспертным путем, или методами многомерной статистики (например, с помощью кластерного анализа). Но первым этапом является составление вопросника, в котором предусматривается стандартизованное описание признаков. В особенности при проведении эпидемиологических исследований, где необходимо единство в понимании и описании одних и тех же симптомов разными врачами, включая учет диапазонов их изменений (степени выраженности). В случае существенности различий в регистрации исходных данных (субъективная оценка характера патологических проявлений различными специалистами) и невозможности их приведения к единому виду на этапе сбора информации, может быть затем осуществлена так называемая коррекция ковариант, которая предполагает нормализацию переменных, т.е. устранение ненормальностей показателей в матрице данных. "Согласование мнений" осуществляется с учетом специальности и опыта врачей, что позволяет затем сравнивать полученные ими результаты обследования между собой. Для этого могут использоваться многомерный дисперсионный и регрессионный анализы. Признаки могут быть как однотипными, что бывает редко, так и разнотипными. Под этим термином понимается их различная метрологическая оценка. Количественные или числовые признаки - это замеренные в определенной шкале и в шкалах интервалов и отношений (I группа признаков). Качественные, ранговые или балльные используются для выражения медицинских терминов и понятий не имеющих цифровых значений (например, тяжесть состояния) и замеряются в шкале порядка (II группа признаков). Классификационные или номинальные (например, профессия, группа крови) - это замеренные в шкале наименований (III группа признаков). Во многих случаях делается попытка анализа крайне большого числа признаков, что должно способствовать повышению информативности представленной выборки. Однако выбор полезной информации, то есть осуществление отбора признаков является операцией совершенно необходимой, поскольку для решения любой классификационной задачи должны быть отобраны сведения, несущие полезную для данной задачи информацию. В случае, если это не осуществлено по каким-то причинам исследователем самостоятельно или отсутствуют достаточно обоснованные критерии для снижения размерности пространства признаков по содержательным соображениям, борьба с избыточностью информации осуществляется уже формальными методами путем оценки информативности. Дисперсионный анализ позволяет определить влияние разных факторов (условий) на исследуемый признак (явление), что достигается путем разложения совокупной изменчивости (дисперсии, выраженной в сумме квадратов отклонений от общего среднего) на отдельные компоненты, вызванные влиянием различных источников изменчивости. С помощью дисперсионного анализа исследуются угрозы заболевания при наличии факторов риска. Концепция относительного риска рассматривает отношение между пациентами с определенной болезнью и не имеющими ее. Величина относительного риска дает возможность определить, во сколько раз увеличивается вероятность заболеть при его наличии, что может быть оценено с помощью следующей упрощенной формулы: где a - наличие признака в исследуемой группе; b - отсутствие признака в исследуемой группе; c - наличие признака в группе сравнения (контрольной); d - отсутствие признака в группе сравнения (контрольной). Показатель атрибутивного риска (rA) служит для оценки доли заболеваемости, связанной с данным фактором риска: где Q - частота признака, маркирующего риск, в популяции; r" - относительный риск. Выявление факторов, способствующих возникновению (проявлению) заболевания, т.е. факторов риска может осуществляться различными способами, например, путем оценки информативности с последующим ранжированием признаков, что однако не указывает на совокупное действие отобранных параметров, в отличие от применения регрессионного, факторного анализов, методов теории распознавания образов, которые дают возможность получать "симптомокомплексы" риск-факторов. Кроме того, более сложные методы позволяют анализировать и непрямые связи между факторами риска и заболеваниями /5/. 2.3 Биотестирование почвы
Многообразные загрязняющие вещества, попадая в агроценоз, могут претерпевать в нем различные превращения, усиливая при этом свое токсическое действие. По этой причине оказались необходимыми методы интегральной оценки качества компонентов агроценоза. Исследования проводили на базе многофакторного дисперсионного анализа в 11-ти польном зернотравянопропашном севообороте. В опыте изучалось влияние следующих факторов: плодородие почвы (А), система удобрений (В), система защиты растений (С). Плодородие почвы, система удобрений и система защиты растений изучались в дозах 0, 1, 2 и 3. Базовые варианты были представлены следующими комбинациями: 000 - исходный уровень плодородия, без применения удобрений и средств защиты растений от вредителей, болезней и сорняков; 111 - средний уровень плодородия почвы, минимальная доза удобрения, биологическая защита растений от вредителей и болезней; 222 - исходный уровень плодородия почвы, средняя доза удобрений, химическая защита растений от сорняков; 333 - высокий уровень плодородия почвы, высокая доза удобрений, химическая защита растений от вредителей и болезней. Изучались варианты, где представлен только один фактор: 200 – плодородие: 020 – удобрения; 002 - средства защиты растений. А также варианты с различным сочетанием факторов - 111, 131, 133, 022, 220, 202, 331, 313, 311. Целью исследования являлось изучение торможения хлоропластов и коэффициента мгновенного роста, как показателей загрязнения почвы, в различных вариантах многофакторного опыта. Торможение фототаксиса хлоропластов ряски малой исследовали в различных горизонтах почвы: 0-20, 20-40 см. Анализ изменчивости фототаксиса в разных вариантах опыта показал достоверное влияние каждого из факторов (плодородия почвы, системы удобрений и системы защиты растений). Доля в общей дисперсии плодородия почвы составила 39,7%, системы удобрений - 30,7%, системы защиты растений - 30,7 %. Для исследования совокупного влияния факторов на торможение фототаксиса хлоропластов использовались различные сочетания вариантов опыта: в первом случае - 000, 002, 022, 222, 220, 200, 202, 020, во втором случае - 111, 333, 331, 313, 133, 311, 131. Результаты двухфакторного дисперсионного анализа свидетельствуют о достоверном влиянии взаимодействующих системы удобрений и системы защиты растений на различия в фототаксисе для первого случая (доля в общей дисперсии составила 10,3%). Для второго случая обнаружено достоверное влияние взаимодействующих плодородия почвы и системы удобрений (53,2%). Трехфакторный дисперсионный анализ показал в первом случае достоверное влияние взаимодействия всех трех факторов. Доля в общей дисперсии составила 47,9%. Коэффициент мгновенного роста исследовали в различных вариантах опыта 000, 111, 222, 333, 002, 200, 220. Первый этап тестирования - до внесения гербицидов на посевах озимой пшеницы (апрель), второй этап - после внесения гербицидов (май) и последний - на момент уборки (июль). Предшетвенники - подсолнечник и кукуруза на зерно. Появление новых листецов наблюдали после короткой лаг-фазы с периодом суммарного удвоения сырой массы 2 - 4 суток. В контроле и в каждом варианте на основании полученных результатов рассчитывали коэффициент мгновенного роста популяции r и далее рассчитывали время удвоения численности листецов (t удв). t удв
=ln2/r. Расчет этих показателей был проведен в динамике с анализом почвенных образцов. Анализ данных показал, что время удвоения популяции рясок до обработки почвы было наименьшем по сравнению с данными после обработки и на момент уборки. В динамике наблюдений больший интерес вызывает отклик почвы после внесения гербицида и на момент уборки. Прежде всего взаимодействие с удобрениями и уровнем плодородия. Подчас получить прямой отклик на внесение химических препараратов может быть осложнено взаимодействием препарата с удобрениями, как органическими, так и минеральными. Полученные данные позволили проследить динамику отклика вносимых препаратов, во всех вариантах с химическими средствами защиты, где отмечается приостановка роста индикатора. Данные однофакторного дисперсионного анализа показали достоверное влияние каждого показателя на темпы роста ряски малой на первом этапе. На втором этапе эффект различий по плодородию почвы составил 65,0 %, по системе удобрений и системе защиты растений - по 65,0%. Факторы показали достоверные различия среднего по коэффициенту мгновенного роста варианта 222 и вариантов 000, 111, 333. На третьем этапе доля в общей дисперсии плодородия почвы составила 42,9%, системы удобрений и системы защиты растений - по 42,9%. Отмечено достоверное различие по средним значениям вариантов 000 и 111, вариантов 333 и 222. Исследуемые образцы почвы с вариантов полевого мониторинга отличаются друг от друга по показателю торможение фототаксиса. Отмечено влияние факторов плодородия, система удобрений и средства защиты растений с долями 30,7 и 39,7% при однофакторном анализе, при двух факторном и трехфакторном - зарегистрировали совместное влияние факторов. Анализ результатов опыта показал незначительные различия между горизонтами почвы по показателю - торможение фототаксиса. Отличия отмечены по средним значениям. На всех вариантах, где имеются средства защиты растений наблюдается изменения положения хлоропластов и приостановка роста ряски малой /6/. 2.4 Грипп вызывает повышенную выработку гистамина
Исследователи из детской больницы в Питсбурге (США) получили первые доказательства того, что при острых респираторных вирусных инфекциях повышается уровень гистамина. Несмотря на то, что и раньше предполагалось, что гистамин играет определенную роль в возникновении симптомов острых респираторных инфекциях верхних дыхательных путей. Ученых интересовало, почему многие люди применяют для самолечения «простудных» заболеваний и насморка антигистаминные препараты, которые во многих странах входят в категорию OTC, т.е. доступны без рецепта врача. Целью проведенного исследования было определить, повышается ли продукция гистамина при экспериментальной инфекции, вызванной вирусом гриппа А. 15 здоровым добровольцам интраназально ввели вирус гриппа А, а затем наблюдали за развитием инфекции. Ежедневно в течение заболевания у добровольцев собиралась утренняя порция мочи, а затем проводилось определение гистамина и его метаболитов и рассчитывалось общее количество гистамина и его метаболитов, выделенных за сутки. Заболевание развилось у всех 15 добровольцев. Дисперсионный анализ подтвердил достоверно более высокий уровень гистамина в моче на 2-5 сутки вирусной инфекции (p<0,02) - период, когда симптомы «простуды» наиболее выражены. Парный анализ показал, что наиболее значительно уровень гистамина повышается на 2 день заболевания. Кроме этого, оказалось, что суточное количество гистамина и его метаболитов в моче при гриппе примерно такое же, как и при обострении аллергического заболевания. Результаты данного исследования служат первыми прямыми доказательствами того, что уровень гистамина повышается при острых респираторных инфекциях /7/. Дисперсионный анализ в химии
Дисперсионный анализ – совокупность методов определения дисперсности, т. е. характеристики размеров частиц в дисперсных системах. Дисперсионный анализ включает различные способы определения размеров свободных частиц в жидких и газовых средах, размеров каналов-пор в тонкопористых телах (в этом случае вместо понятия дисперсности используют равнозначное понятие пористости), а также удельной поверхности. Одни из методов дисперсионного анализа позволяют получать полную картину распределения частиц по размерам (объёмам), а другие дают лишь усреднённую характеристику дисперсности (пористости). К первой группе относятся, например, методы определения размеров отдельных частиц непосредственным измерением (ситовой анализ, оптическая и электронная микроскопия) или по косвенным данным: скорости оседания частиц в вязкой среде (седиментационный анализ в гравитационном поле и в центрифугах), величине импульсов электрического тока, возникающих при прохождении частиц через отверстие в непроводящей перегородке (кондуктометрический метод). Вторая группа методов объединяет оценку средних размеров свободных частиц и определение удельной поверхности порошков и пористых тел. Средний размер частиц находят по интенсивности рассеянного света (нефелометрия), с помощью ультрамикроскопа, методами диффузии и т.д., удельную поверхность - по адсорбции газов (паров) или растворённых веществ, по газопроницаемости, скорости растворения и др. способами. Ниже приведены границы применимости различных методов дисперсионного анализа (размеры частиц в метрах): Ситовой анализ – 10 -2
-10 -4 Седиментационный анализ в гравитационном поле – 10 -4
-10 -6 Кондуктометрический метод – 10 -4
-10 -6 Микроскопия – 10 -4
-10 -7 Метод фильтрации – 10 -5
-10 -7 Центрифугирование – 10 -6
-10 -8 Ультрацентрифугирование – 10 -7
-10 -9 Ультрамикроскопия – 10 -7
-10 -9 Нефелометрия – 10 -7
-10 -9 Электронная микроскопия – 10 -7
-10 -9 Метод диффузии – 10 -7
-10 -10 Дисперсионный анализ широко используют в различных областях науки и промышленного производства для оценки дисперсности систем (суспензий, эмульсий, золей, порошков, адсорбентов и т.д.) с величиной частиц от нескольких миллиметров (10 -3
м) до нескольких нанометров (10 -9
м) /8/. 2.6 Использование прямого преднамеренного внушения в бодрствующем состоянии в методике воспитания физических качеств
Физическая подготовка – основополагающая сторона спортивной тренировки, так как в большей мере, чем другие стороны подготовки, характеризуется физическими нагрузками, воздействующими на морфофункциональные свойства организма. От уровня физической подготовленности зависят успешность технической подготовки, содержание тактики спортсмена, реализация личностных свойств в процессе тренировок и состязаний. Одной из основных задач физической подготовки является воспитание физических качеств. В связи с этим возникает необходимость в разработке педагогических средств и методов, позволяющих учитывать возрастные особенности юных спортсменов, сохраняющих их здоровье, не требующих дополнительных затрат времени и в то же время стимулирующих рост физических качеств и, как следствие, - спортивного мастерства. Использование вербального гетеровоздействия в тренировочном процессе в группах начальной подготовки - одно из перспективных направлений исследований по данной проблеме. Анализ теории и практики реализации внушающего вербального гетеровоздействия выявил основные противоречия: Доказанность эффективного использования специфических методов вербального гетеровоздействия в тренировочном процессе и практическую невозможность их использования тренером; Признание прямого преднамеренного внушения (далее ППВ) в бодрствующем состоянии как одного из основных методов вербального гетеровоздействия в педагогической деятельности тренера и отсутствие теоретического обоснования методических особенностей его применения в спортивной подготовке, и в частности в процессе воспитания физических качеств. В связи с выявленными противоречиями и недостаточной разработанностью проблема использования системы методов вербального гетеровоздействия в процессе воспитания физических качеств спортсменов предопределила цель исследования - разработать рациональные целенаправленные методики ППВ в бодрствующем состоянии, способствующие совершенствованию процесса воспитания физических качеств на основе оценки психического состояния, проявления и динамики физических качеств дзюдоистов групп начальной подготовки. С целью апробации и определения эффективности экспериментальных методик ППВ при воспитании физических качеств дзюдоистов был проведен сравнительный педагогический эксперимент, в котором приняли участие четыре группы – три экспериментальных и одна контрольная. В первой экспериментальной группе (ЭГ) использовалась методика ППВ М1, во второй - методика ППВ М2, в третьей - методика ППВ М3. В контрольной группе (КГ) методики ППВ не применялись. Для определения эффективности педагогического воздействия методик ППВ в процессе воспитания у дзюдоистов физических качеств был проведен однофакторный дисперсионный анализ. Степень влияния методики ППВ M1 в процессе воспитания: Выносливости: а) после третьего месяца составила 11,1%; Скоростных способностей: а) после первого месяца - 16,4%; б) после второго - 26,5%; в) после третьего - 34,8%; а) после второго месяца - 26, 7%; б) после третьего - 35,3%; Гибкости: а) после третьего месяца - 20,8%; а) после второго месяца основного педагогического эксперимента степень влияния методики составила 6,4%; б) после третьего - 10,2%. Следовательно, существенные изменения в показателях уровня развития физических качеств с использованием методики ППВ М1 обнаружены в скоростных способностях и силе, степень влияния методики в данном случае наибольшая. Наименьшая степень влияния методики обнаружена в процессе воспитания выносливости, гибкости, координационных способностей, что дает основание говорить о недостаточной эффективности использования методики ППВ М1 при воспитании указанных качеств. Степень влияния методики ППВ M2 в процессе воспитания: Выносливости а) после первого месяца эксперимента - 12,6%; б) после второго - 17,8%; в) после третьего - 20,3%. Скоростных способностей: а) после третьего месяца тренировочных занятий - 28%. а) после второго месяца - 27,9%; б) после третьего - 35,9%. Гибкости: а) после третьего месяца тренировочных занятий - 14,9%; Координационных способностей - 13,1%. Полученный результат однофакторного дисперсионного анализа данной ЭГ позволяет сделать вывод о том, что методика ППВ М2 наиболее результативна при воспитании выносливости и силы. Менее эффективна она в процессе воспитания гибкости, скоростных и координационных способностей. Степень влияния методики ППВ М3 в процессе воспитания: Выносливости: а) после первого месяца эксперимента 16,8%; б) после второго - 29,5%; в) после третьего - 37,6%. Скоростных способностей: а) после первого месяца - 26,3%; б) после второго - 31,3%; в) после третьего - 40,9%. а) после первого месяца - 18,7%; б) после второго - 26,7%; в) после третьего - 32,3%. Гибкости: а) после первого - изменений нет; б) после второго - 16,9%; в) после третьего - 23,5%. Координационных способностей: а) после первого месяца изменений нет; б) после второго - 23,8%; в) после третьего - 91% . Таким образом, однофакторный дисперсионный анализ показал, что использование методики ППВ М3 в подготовительном периоде наиболее эффективно в процессе воспитания физических качеств, так как наблюдается увеличение степени ее влияния после каждого месяца педагогического эксперимента /9/. 2.7 Купирование острой психотической симптоматики у больных шизофренией атипичным нейролептиком
Цель исследования сводилась к изучению возможности применения рисполепта для купирования острых психозов у больных с диагнозом шизофрении (параноидный тип по МКБ-10) и шизоаффективного расстройства. При этом в качестве основного изучаемого критерия использовался показатель длительности сохранения психотической симптоматики в условиях фармакотерапии рисполептом (основная группа) и классическими нейролептиками. Основные задачи исследования сводились к определению показателя длительности психоза (так называемый нетто-психоз), под которым понималось сохранение продуктивной психотической симптоматики с момента начала применения нейролептиков, выраженное в днях. Данный показатель был рассчитан отдельно для группы, принимавшей рисперидон, и отдельно для группы, принимавшей классические нейролептики. Наряду с этим была поставлена задача по определению доли редукции продуктивной симптоматики под влиянием рисперидона в сравнении с классическими нейролептиками в разные сроки терапии. В общей сложности изучены 89 больных (42 мужчины и 47 женщин) с острой психотической симптоматикой в рамках параноидной формы шизофрении (49 больных) и шизоаффективного расстройства (40 больных). Первый эпизод и длительность заболевания до 1 года были зарегистрированы у 43 больных, тогда как в остальных случаях на момент исследования отмечались последующие эпизоды шизофрении при длительности заболевания свыше 1 года. Терапию рисполептом получали 29 человек, среди которых с так называемым первым эпизодом было 15 больных. Терапию классическими нейролептиками получали 60 человек, среди которых с первым эпизодом было 28 человек. Доза рисполепта варьировала в диапазоне от 1 до 6 мг в сутки и в среднем составляла 4±0,4 мг/сут. Рисперидон принимали исключительно внутрь после еды один раз в сутки в вечернее время. Терапия классическими нейролептиками включала применение трифлуоперазина (трифтазина) в суточной дозе до 30 мг внутримышечно, галоперидола в суточной дозе до 20 мг внутримышечно, триперидола в суточной дозе до 10 мг внутрь. Подавляющее большинство больных принимало классические нейролептики в виде монотерапии в течение первых двух недель, после чего переходили в случае необходимости (при сохранении бредовой, галлюцинаторной или другой продуктивной симптоматики) к сочетанию нескольких классических нейролептиков. При этом в качестве основного препарата оставался нейролептик с выраженным элективным антибредовым и антигаллюцинаторным аффектом (например, галоперидол или трифтазин), к нему присоединяли в вечернее время препарат с отчетливым гипноседативным эффектом (аминазин, тизерцин, хлорпротиксен в дозах до 50-100 мг/сут). В группе, принимавшей классические нейролептики, был предусмотрен прием корректоров холинолитического ряда (паркопан, циклодол) в дозах до 10-12 мг/сут. Корректоры назначались в случае появления отчетливых побочных экстрапирамидных эффектов в виде острых дистоний, лекарственного паркинсонизма и акатизии. В таблице 2.1 представлены данные по длительности психоза при лечении рисполептом и классическими нейролептиками. Таблица 2.1 – Длительность психоза ("нетто-психоз") при лечении рисполептом и классическими нейролептиками Как следует из данных таблицы, при сравнении длительности психоза при терапии классическими нейролептиками и рисперидоном наблюдается практически двукратное сокращение продолжительности психотической симптоматики под влиянием рисполепта. Существенно, что на данную величину продолжительности психоза не влияли ни факторы порядкового номера приступов, ни характер картины ведущего синдрома. Иначе говоря, длительность психоза определялась исключительно фактором терапии, т.е. зависела от типа применяемого препарата безотносительно порядкового номера приступа, продолжительности заболевания и характера ведущего психопатологического синдрома. С целью подтверждения полученных закономерностей был проведен двухфакторный дисперсионный анализ. При этом поочередно учитывалось взаимодействие фактора терапии и порядкового номера приступа (1-й этап) и взаимодействие фактора терапии и характера ведущего синдрома (2-й этап). Результаты дисперсионного анализа подтвердили влияние фактора терапии на величину длительности психоза (F=18,8) при отсутствии влияния фактора номера приступа (F=2,5) и фактора типа психопатологического синдрома (F=1,7). Немаловажно, что совместное влияние фактора терапии и номера приступа на величину длительности психоза также отсутствовало, равно как и совместное влияние фактора терапии и фактора психопатологического синдрома. Таким образом, результаты дисперсионного анализа подтвердили влияние только фактора применяемого нейролептика. Рисполепт однозначно приводил к сокращению длительности психотической симптоматики по сравнению с традиционными нейролептиками примерно в 2 раза. Принципиально, что этот эффект был достигнут, несмотря на пероральный прием рисполепта, тогда как классические нейролептики применялись у большей части больных парентерально /10/. 2.8 Снование фасонной пряжи с ровничным эффектом
В Костромском Государственном технологическом университете разработана новая структура фасонной нити с переменными геометрическими параметрами. В связи с этим возникает проблема переработки фасонной пряжи в приготовительном производстве. Данное исследование посвящалось процессу снования по вопросам: выбор типа натяжного устройства, дающего минимальный разброс натяжения и выравнивание натяжения, нитей различной линейной плотности по ширине сновального вала. Объект исследования – льняная фасонная нить четырех вариантов линейной плотности от 140 до 205 текса. Исследовалась работа натяжных приборов трех типов: фарфорового шайбового, двухзонного НС-1П и однозонного НС-1П. Экспериментальное исследование натяжения снующихся нитей производилось на сновальной машине СП-140-3Л. Скорость снования, масса тормозных шайб соответствовали технологическим параметрам снования пряжи. Для исследования зависимости натяжения фасонной нити от геометрических параметров при сновании проведен анализ для двух факторов: X 1
- диаметр эффекта, X 2
- длина эффекта. Выходными параметрами являются натяжение Y 1
и колебание натяжения Y 2
. Полученные уравнения регрессии адекватны экспериментальным данным при уровне значимости 0,95, так как расчетный критерий Фишера для всех уравнений меньше табличного. Для определения степени влияния факторов Х 1
и Х 2
на параметры Y 1
и Y 2
проведен дисперсионный анализ, который показал, что большее влияние на уровень и колебание натяжения оказывает диаметр эффекта. Сравнительный анализ полученных тензограмм показал, что минимальный разброс натяжения при сновании данной пряжи обеспечивает двухзонный натяжной прибор НС-1П. Установлено, что с ростом линейной плотности от 105 до 205 текс прибор НС-1П дает приращение уровня натяжения лишь на 23%, в то время как фарфоровый шайбовый - на 37 %, однозонный НС-1П на 53 %. При формировании сновальных валов, включающих в себя фасонные и "гладкие" нити, необходима индивидуальная настройка натяжного прибора традиционным методом /11/. 2.9 Сопутствующая патология при полной утрате зубов у лиц пожилого и старческого возраста
Изучены эпидемиологически полная утрата зубов и сопутствующая патология пожилого населения, проживающего в домах престарелых на территории Чувашии. Обследование проводилось путем стоматологического осмотра и заполнения статистических карт 784 человек. Результаты анализа показали высокий процент полной утраты зубов, усугубляющейся общей патологией организма. Это характеризует осмотренную категорию населения как группу повышенного стоматологического риска и требует пересмотра всей системы стоматологического обслуживания их. У пожилых людей уровень заболеваемости в два раза, а в старческом возрасте в шесть раз выше в сравнении с уровнем заболеваемости лиц более молодых возрастов. Основными заболеваниями лиц пожилого и старческого возраста являются болезни органов кровообращения, нервной системы и органов чувств, органов дыхания, органов пищеварения, костей и органов движения, новообразования и травмы. Цель исследования – разработка и получение информации о сопутствующих заболеваниях, эффективности зубопротезирования и нуждаемости в ортопедическом лечении лиц пожилого и старческого возраста с полной потерей зубов. Всего было обследовано 784 человека в возрасте от 45 до 90 лет. Соотношение женщин и мужчин 2,8:1. Оценка статистической связи с помощью коэффициента корреляции рангов Пирсона позволила установить взаимное влияние отсутствия зубов на сопутствующую заболеваемость с уровнем надежности р=0,0005. Пожилые пациенты с полной потерей зубов страдают болезнями, свойственными старости, а именно, атеросклерозом сосудов головного мозга и гипертонической болезнью. Дисперсионный анализ показал, что в изучаемых условиях определяющую роль играет специфика болезни. Роль нозологических форм в различных возрастных периодах колеблется в пределах 52-60 %. Наибольшее статистически достоверное влияние на отсутствие зубов оказывают болезни органов пищеварения и сахарный диабет. В целом группа больных в возрасте 75-89 лет характеризовалась большим числом патологических заболеваний. В этом исследовании было проведено сравнительное изучение частоты распространения сопутствующей патологии среди пациентов с полной утратой зубов пожилого и старческого возраста, проживающих в домах престарелых. Выявлен высокий процент отсутствия зубов среди лиц этой возрастной категории. У пациентов с полной адентией наблюдается характерная для этого возраста сопутствующая патология. Наиболее часто среди обследованных лиц встречались атеросклероз и гипертония. Статистически достоверно влияние на состояние полости рта таких заболеваний, как болезни желудочно-кишечного тракта и сахарный диабет, доля остальных нозоологических форм оказалась в пределах 52-60 %. Применение дисперсионного анализа не подтвердили значимой роли пола и местожительства на показатели состояния полости рта. Таким образом, в заключении следует отметить, что анализ распределения сопутствующих заболеваний у лиц с полным отсутствием зубов в пожилом и старческом возрасте показал, что эта категория граждан относится к особой группе населения, которая должна получать адекватную стоматологическую помощь в рамках существующих стоматологических систем /12/. 3 Дисперсионный анализ в контексте статистических методов
Статистические методы анализа – это методология измерения результатов деятельности человека, то есть перевода качественных характеристик в количественные. Основные этапы при проведении статистического анализа: Составление плана сбора исходных данных - значений входных переменных (X 1
,...,X p), числа наблюдений n. Этот этап выполняется при активном планировании эксперимента. Получение исходных данных и ввод их в компьютер. На этом этапе формируются массивы чисел (x 1i
,..., x pi
; y 1i
,..., y qi), i=1,..., n, где n - объем выборки. Первичная статистическая обработка данных. На данном этапе формируется статистическое описание рассматриваемых параметров: а)
построение и анализ статистических зависимостей; б) корреляционный анализ предназначен для оценивания значимости влияния факторов (X 1
,...,X p) на отклик Y; в) дисперсионный анализ используется для оценивания влияния на отклик Y неколичественных факторов (X 1
,...,X p) с целью выбора среди них наиболее важных; г) регрессионный анализ предназначен для определения аналитической зависимости отклика Y от количественных факторов X; Интерпретация результатов в терминах поставленной задачи /13/. В таблице 3.1 приведены статистические методы, с помощью которых решаются аналитические задачи. В соответствующих ячейках таблицы находятся частоты применения статистических методов: Метка «-» - метод не применяется; Метка «+» - метод применяется; Метка «++» - метод широко применяется; Метка «+++» - применение метода представляет особый интерес /14/. Дисперсионный анализ подобно t-критерию Стьюдента, позволяет оценить различия между выборочными средними; однако, в отличие от t-критерия, в нем нет ограничений на количество сравниваемых средних. Таким образом, вместо того, чтобы поставить вопрос о различии двух выборочных средних, можно оценить, различаются ли два, три четыре, пять или k средних. Дисперсионный анализ позволяет иметь дело с двумя или более независимыми переменными (признаками, факторами) одновременно, оценивая не только эффект каждой из них по отдельности, но и эффекты взаимодействия между ними /15/. Таблица 3.1 – Применение статистических методов при решении аналитических задач Аналитические задачи, возникающие в сфере бизнеса, финансов и управления Методы описательной статистики Методы поверки статисти-ческих гипотез Методы регресси-онного анализа Методы дисперси-онного анализа Методы много-мерного анализа Методы дискриминантного анализа кластер-ного Методы анализа выжива-емости Методы анализа и прогноза временных рядов Задачи горизонталь-ного (временного) анализа Задачи вертикального (структурного) анализа Задачи трендового анализа и прогноза Задачи анализа относительных показателей Задачи сравнительного (пространствен-ного) анализа Задачи факторного анализа К большинству сложных систем применим принцип Парето, согласно которому 20 % факторов определяют свойства системы на 80 %. Поэтому первоочередной задачей исследователя имитационной модели является отсеивание несущественных факторов, позволяющее уменьшить размерность задачи оптимизации модели. Анализ дисперсии оценивает отклонение наблюдений от общего среднего. Затем вариация разбивается на части, каждая из которых имеет свою причину. Остаточная часть вариации, которую не удается связать с условиями эксперимента, считается его случайной ошибкой. Для подтверждения значимости используется специальный тест - F-статистика. Дисперсионный анализ определяет, есть ли эффект. Регрессионный анализ позволяет прогнозировать отклик (значение целевой функции) в некоторой точке пространства параметров. Непосредственной задачей регрессионного анализа является оценка коэффициентов регрессии /16/. Слишком большая размерность выборок затрудняет проведение статистических анализов, поэтому имеет смысл уменьшить размер выборки. Применив дисперсионный анализ можно выявить значимость влияния различных факторов на исследуемую переменную. Если влияние фактора окажется несущественным, то этот фактор можно исключить из дальнейшей обработки. Макроэконометристы должны уметь решать четыре логически отличающиеся задачи: Описание данных; Макроэкономический прогноз; Структурный вывод; Анализ политики. Описание данных означает описание свойств одного или нескольких временных рядов и сообщение этих свойств широкому кругу экономистов. Макроэкономический прогноз означает предсказание курса экономики, обычно на два-три года или меньше (главным образом потому, что прогнозировать на более длинные горизонты слишком трудно). Структурный вывод означает проверку того, соответствуют ли макроэкономические данные конкретной экономической теории. Макроэконометрический анализ политики происходит по нескольким направлениям: с одной стороны, оценивается влияние на экономику гипотетического изменения инструментов политики (например налоговой ставки или краткосрочной процентной ставки), с другой стороны, оценивается влияние изменения правил политики (например переход к новому режиму монетарной политики). Эмпирический макроэкономический исследовательский проект может включать одну или несколько из этих четырех задач. Каждая задача должна быть решена таким образом, чтобы были учтены корреляции между рядами по времени. В 1970-х годах эти задачи решались с использованием разнообразных методов, которые, если оценить их с современных позиций, были неадекватны по нескольким причинам. Чтобы описать динамику отдельного ряда, достаточно было просто использовать одномерные модели временных рядов, а чтобы описать совместную динамику двух рядов – спектральный анализ. Однако отсутствовал общепринятый язык, пригодный для систематического описания совместных динамических свойств нескольких временных рядов. Экономические прогнозы делались либо с использованием упрощенных моделей авторегрессии - скользящего среднего (ARMA), либо с использованием популярных в то время больших структурных эконометрических моделей. Структурный вывод основывался либо на малых моделях с одним уравнением, либо на больших моделях, идентификация в которых достигалась за счет плохо обоснованных исключающих ограничений, и которые обычно не включали ожидания. Анализ политики на основе структурных моделей зависел от этих идентифицирующих предположений. Наконец, рост цен в 1970-е годы рассматривался многими как серьезная неудача больших моделей, которые в то время использовались для выработки политических рекомендаций. То есть это было подходящее время для появления новой макроэконометрической конструкции, которая могла бы решить эти многочисленные проблемы. В 1980 году была создана такая конструкция – векторные авторегрессии (VAR). На первый взгляд, VAR – не более, чем обобщение одномерной авторегрессии на многомерный случай, и каждое уравнение в VAR – не более, чем обычная регрессия по методу наименьших квадратов одной переменной на запаздывающие значения себя и других переменных в VAR. Но этот вроде бы простой инструмент дал возможность систематически и внутренне согласованно уловить богатую динамику многомерных временных рядов, а статистический инструментарий, который сопутствует VAR, оказался удобным и, что очень важно, его было легко интерпретировать. Выделяют три различных VAR-модели: Приведенная форма VAR; Рекурсивная VAR; Структурная VAR. Все три являются динамическими линейными моделями, которые связывают текущие и прошлые значения вектора Y t
n-мерного временного ряда. Приведенная форма и рекурсивные VAR – это статистические модели, которые не используют никакие экономические соображения за исключением выбора переменных. Эти VAR используются для описания данных и прогноза. Структурная VAR включает ограничения, полученные из макроэкономической теории, и эта VAR используется для структурного вывода и анализа политики. Приведенная форма VAR выражает Y t
в виде распределенного лага прошлых значений плюс серийно некоррелированный член ошибки, то есть обобщает одномерную авторегрессию на случай векторов. Математически приведенная форма модели VAR – это система n уравнений, которые можно записать в матричной форме следующим образом: где - это n l вектор констант; A 1
, A 2
, ..., A p
– это n n матрицы коэффициентов; t
, - это nl вектор серийно некоррелированных ошибок, о которых предполагается, что они имеют среднее ноль и матрицу ковариаций . Ошибки t
, в (17) – это неожиданная динамика в Y t
, остающаяся после учета линейного распределенного лага прошлых значений. Оценить параметры приведенной формы VAR легко. Каждое из уравнений содержит одни и те же регрессоры (Y t–1
,...,Y t–p), и нет взаимных ограничений между уравнениями. Таким образом, эффективная оценка (метод максимального правдоподобия с полной информацией) упрощается до обычного МНК, примененного к каждому из уравнений. Матрицу ковариаций ошибок можно состоятельно оценить выборочной ковариационной матрицей полученных из МНК остатков. Единственная тонкость – определить длину лага p, но это можно сделать, используя информационный критерий, такой как AIC или BIC. На уровне матричных уравнений рекурсивная и структурная VAR выглядят одинаково. Эти две модели VAR учитывают в явном виде одновременные взаимодействия между элементами Y t
, что сводится к добавлению одновременного члена к правой части уравнения (17). Соответственно, рекурсивная и структурная VAR обе представляются в следующем общем виде: где - вектор констант; B 0
,..., B p
- матрицы; t
- ошибки. Наличие в уравнении матрицы B 0
означает возможность одновременного взаимодействия между n переменными; то есть B 0
позволяет сделать так, чтобы эти переменные, относящиеся к одному моменту времени, определялись совместно. Рекурсивную VAR можно оценить двумя способами. Рекурсивная структура дает набор рекурсивных уравнений, которые можно оценить с помощью МНК. Эквивалентный способ оценивания заключается в том, что уравнения приведенной формы (17), рассматриваемые как система, умножаются слева на нижнюю треугольную матрицу. Метод оценивания структурной VAR зависит от того, как именно идентифицирована B 0
. Подход с частичной информацией влечет использование методов оценивания для отдельного уравнения, таких как двухшаговый метод наименьших квадратов. Подход с полной информацией влечет использование методов оценивания для нескольких уравнений, таких как трехшаговый метод наименьших квадратов. Необходимо помнить о множественности различных типов VAR. Приведенная форма VAR единственна. Данному порядку переменных в Y t
соответствует единственная рекурсивная VAR, но всего имеется n! таких порядков, т.е. n! различных рекурсивных VAR. Количество структурных VAR – то есть наборов предположений, которые идентифицируют одновременные взаимосвязи между переменными, - ограничено только изобретательностью исследователя. Поскольку матрицы оцененных коэффициентов VAR затруднительно интерпретировать непосредственно, результаты оценивания VAR обычно представляют некоторыми функциями этих матриц. К таким статистикам разложения ошибки прогноза. Разложения дисперсии ошибки прогноза вычисляются в основном для рекурсивных или структурных систем. Такое разложение дисперсии показывает, насколько ошибка в j-м уравнении важна для объяснения неожиданных изменений i-й переменной. Когда ошибки VAR некоррелированы по уравнениям, дисперсию ошибки прогноза на h периодов вперед можно записать как сумму компонентов, являющихся результатом каждой из этих ошибок /17/. 3.2 Факторный анализ
В современной статистике под факторным анализом понимают совокупность методов, которые на основе реально существующих связей признаков (или объектов) позволяют выявлять латентные обобщающие характеристики организационной структуры и механизма развития изучаемых явлений и процессов. Понятие латентности в определении ключевое. Оно означает неявность характеристик, раскрываемых при помощи методов факторного анализа. Вначале имеется дело с набором элементарных признаков X j
, их взаимодействие предполагает наличие определенных причин, особенных условий, т.е. существование некоторых скрытых факторов. Последние устанавливаются в результате обобщения элементарных признаков и выступают как интегрированные характеристики, или признаки, но более высокого уровня. Естественно, что коррелировать могут не только тривиальные признаки X j
, но и сами наблюдаемые объекты N i
поэтому поиск латентных факторов теоретически возможен как по признаковым, так и по объектным данным. Если объекты характеризуются достаточно большим числом элементарных признаков (m > 3), то логично и другое предположение - о существовании плотных скоплений точек (признаков) в пространстве n объектов. При этом новые оси обобщают уже не признаки X j
, а объекты n i
, соответственно и латентные факторы F r
будут распознаны по составу наблюдаемых объектов: F r
= c 1
n 1
+ c 2
n 2 + ... +
c N
n N
, где c i
- вес объекта n i
в факторе F r
. В зависимости от того, какой из рассмотренных выше тип корреляционной связи - элементарных признаков или наблюдаемых объектов - исследуется в факторном анализе, различают R и Q - технические приемы обработки данных. Название R-техники носит объемный анализ данных по m признакам, в результате него получают r линейных комбинаций (групп) признаков: F r
=f(X j), (r=1..m). Анализ по данным о близости (связи) n наблюдаемых объектов называется Q-техникой и позволяет определять r линейных комбинаций (групп) объектов: F=f(n i), (i = l .. N). В настоящее время на практике более 90% задач решается при помощи R-техники. Набор методов факторного анализа в настоящее время достаточно велик, насчитывает десятки различных подходов и приемов обработки данных. Чтобы в исследованиях ориентироваться на правильный выбор методов, необходимо представлять их особенности. Разделим все методы факторного анализа на несколько классификационных групп: Метод главных компонент. Строго говоря, его не относят к факторному анализу, хотя он имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу элементарных признаков. Во-вторых, постулируется возможность полного разложения дисперсии элементарных признаков, другими словами, ее полное объяснение через латентные факторы (обобщенные признаки). Методы факторного анализа. Дисперсия элементарных признаков здесь объясняется не в полном объеме, признается, что часть дисперсии остается нераспознанной как характерность. Факторы обычно выделяются последовательно: первый, объясняющий наибольшую долю вариации элементарных признаков, затем второй, объясняющий меньшую, вторую после первого латентного фактора часть дисперсии, третий и т.д. Процесс выделения факторов может быть прерван на любом шаге, если принято решение о достаточности доли объясненной дисперсии элементарных признаков или с учетом интерпретируемости латентных факторов. Методы факторного анализа целесообразно разделить дополнительно на два класса: упрощенные и современные аппроксимирующие методы. Простые методы факторного анализа в основном связаны с начальными теоретическими разработками. Они имеют ограниченные возможности в выделении латентных факторов и аппроксимации факторных решений. К ним относятся: Однофакторная модель. Она позволяет выделить только один генеральный латентный и один характерный факторы. Для возможно существующих других латентных факторов делается предположение об их незначимости; Бифакторная модель. Допускает влияние на вариацию элементарных признаков не одного, а нескольких латентных факторов (обычно двух) и одного характерного фактора; Центроидный метод. В нем корреляции между переменными рассматриваются как пучок векторов, а латентный фактор геометрически представляется как уравновешивающий вектор, проходящий через центр этого пучка. : Метод позволяет выделять несколько латентных и характерные факторы, впервые появляется возможность соотносить факторное решение с исходными данными, т.е. в простейшем виде решать задачу аппроксимации. Современные аппроксимирующие методы часто предполагают, что первое, приближенное решение уже найдено каким либо из способов, последующими шагами это решение оптимизируется. Методы отличаются сложностью вычислений. К этим методам относятся: Групповой метод. Решение базируется на предварительно отобранных каким-либо образом группах элементарных признаков; Метод главных факторов. Наиболее близок методу главных компонент, отличие заключается в предположении о существовании характерностей; Метод максимального правдоподобия, минимальных остатков, а-факторного анализа канонического факторного анализа, все оптимизирующие. Эти методы позволяют последовательно улучшить предварительно найденные решения на основе использования статистических приемов оценивания случайной величины или статистических критериев, предполагают большой объем трудоемких вычислений. Наиболее перспективным и удобным для работы в этой группе признается метод максимального правдоподобия. Основной задачей, которую решают разнообразными методами факторного анализа, включая и метод главных компонент, является сжатие информации, переход от множества значений по m элементарным признакам с объемом информации n х m к ограниченному множеству элементов матрицы факторного отображения (m х r) или матрицы значений латентных факторов для каждого наблюдаемого объекта размерностью n х r, причем обычно r < m. Методы факторного анализа позволяют также визуализировать структуру изучаемых явлений и процессов, а это значит определять их состояние и прогнозировать развитие. Наконец, данные факторного анализа дают основания для идентификации объекта, т.е. решения задачи распознавания образа. Методы факторного анализа обладают свойствами, весьма привлекательными для их использования в составе других статистических методов, наиболее часто в корреляционно-регрессионном анализе, кластерном анализе, многомерном шкалировании и др. /18/. 3.3 Парная регрессия. Вероятностная природа регрессионных моделей.
Если рассмотреть задачу анализа расходов на питание в группах с одинаковыми доходами, например в $10.000(x), то это детерминированная величина. А вот Y - доля этих денег, затрачиваемая на питание - случайна и может меняться от года к году. Поэтому для каждого i-го индивида: где ε i
- случайная ошибка; α и β - константы (теоретически), хотя могут меняться от модели к модели. Предпосылки для парной регрессии: X и Y связаны линейно; Х - неслучайная переменная с фиксированными значениями; - ε - ошибки нормально распределены N(0,σ 2); - На рисунке 3.1 представлена модель парной регрессии. Рисунок 3.1 – Модель парной регрессии Эти предпосылки описывают классическую линейную регрессионную модель. Если ошибка имеет ненулевое среднее, исходная модель будет эквивалентна новой модели и другим свободным членом, но с нулевым средним для ошибки. Если выполняются предпосылки, то МНК оценки и являются эффективными линейными несмещенными оценками Если обозначить: то что математическое ожидание и дисперсии коэффициентов и будут следующие: Ковариация коэффициентов: Если Отсюда следует, что: Вариация β полностью определяется вариацией ε; Чем выше дисперсия X - тем лучше оценка β. Полная дисперсия определяется по формуле: Дисперсия отклонений в таком виде - несмещенная оценка и называется стандартной ошибкой регрессии. N-2 - может быть интерпретировано как число степеней свободы. Анализ отклонений от линии регрессии может представить полезную меру того, насколько оцененная регрессия отражает реальные данные. Хорошая регрессия та, которая объясняет значительную долю дисперсии Y и наоборот плохая регрессия не отслеживает большую часть колебаний исходных данных. Интуитивно ясно, что всякая дополнительная информация позволит улучшить модель, то есть уменьшить необъясненную долю вариации Y. Для анализа регрессионной модели проводят разложение дисперсии на составляющие, определяют коэффициент детерминации R 2
. Отношение двух дисперсий распределено по F-распределению, т. е. если проверить на статистическую значимость отличия дисперсии модели от дисперсии остатков, можно сделать вывод о значимости R 2
. Проверка гипотезы о равенстве дисперсий этих двух выборок: Если гипотеза Н 0
(о равенстве дисперсий нескольких выборок) верна, t имеет F-распределение с (m 1
,m 2)=(n 1
-1,n 2
-1) степенями свободы. Посчитав F – отношение как отношение двух дисперсий и сравнив его с табличным значением, можно сделать вывод о статистической значимости R 2
/2/, /19/. Заключение
Современные приложения дисперсионного анализа охватывают широкий круг задач экономики, биологии и техники и трактуются обычно в терминах статистической теории выявления систематических различий между результатами непосредственных измерений, выполненных при тех или иных меняющихся условиях. Благодаря автоматизации дисперсионного анализа исследователь может проводить различные статистические исследования с применение ЭВМ, затрачивая при этом меньше времени и усилий на расчеты данных. В настоящее время существует множество пакетов прикладных программ, в которых реализован аппарат дисперсионного анализа. Наиболее распространенными являются такие программные продукты как: В современных статистических программных продуктах реализованы большинство статистических методов. С развитием алгоритмических языков программирования стало возможным создавать дополнительные блоки по обработке статистических данных. Дисперсионный анализ является мощным современным статистическим методом обработки и анализа экспериментальных данных в психологии, биологии, медицине и других науках. Он очень тесно связан с конкретной методологией планирования и проведения экспериментальных исследований. Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную. Список литературы
1 Кремер Н.Ш. Теория вероятности и математическая статистика. М.: Юнити – Дана, 2002.-343с. 2 Гмурман В.Е. Теория вероятностей и математическая статистика. – М.: Высшая школа, 2003.-523с. 4 www.conf.mitme.ru 5 www.pedklin.ru 6 www.webcenter.ru 7 www.infections.ru 8 www.encycl.yandex.ru 9 www.infosport.ru 10 www.medtrust.ru 11 www.flax.net.ru 12 www.jdc.org.il 13 www.big.spb.ru 14 www.bizcom.ru 15 Гусев А.Н. Дисперсионный анализ в экспериментальной психологии. – М.: Учебно-методический коллектор «Психология», 2000.-136с. 17 www.econometrics.exponenta.ru 18 www.optimizer.by.ru Для чего применяется дисперсионный анализ?
Цель дисперсионного анализа -
исследование наличия или отсутствия существенного влияния какого-либо качественного или количественного фактора на изменения
исследуемого результативного признака. Для этого фактор, предположительно имеющий или не имеющий
существенного влияния, разделяют на классы градации (говоря иначе, группы) и выясняют, одинаково ли влияние фактора путём исследования значимости между средними
в наборах данных, соответствующих градациям фактора. Примеры: исследуется зависимость прибыли предприятия
от типа используемого сырья (тогда классы градации - типы сырья), зависимость себестоимости выпуска единицы продукции от величины подразделения
предприятия (тогда классы градации - характеристики величины подразделения: большой, средний, малый). Минимальное число классов градации (групп) - два. Классы градации могут быть качественными либо количественными. Почему дисперсионный анализ называется дисперсионным?
При дисперсионном анализе исследуется отношение двух дисперсий. Дисперсия, как мы знаем - характеристика
рассеивания данных вокруг среднего значения. Первая - дисперсия, объяснённая влиянием фактора, которая
характеризует рассеивание значений между градациями фактора (группами) вокруг средней всех данных. Вторая -
необъяснённая дисперсия, которая характеризует рассеивание данных внутри градаций (групп) вокруг средних
значений самих групп. Первую дисперсию можно назвать межгрупповой, а вторую - внутригрупповой. Отношение
этих дисперсий называется фактическим отношением Фишера и сравнивается с
критическим значением отношения Фишера. Если фактическое отношение Фишера больше критического, то
средние классов градации отличаются друг от друга и исследуемый фактор существенно влияет на изменение
данных. Если меньше, то средние классов градации не отличаются друг от друга и фактор не имеет
существенного влияния. Как формулируются, принимаются и отвергаются гипотезы при дисперсионном
анализе?
При дисперсионном анализе определяют удельный вес суммарного воздействия одного или
нескольких факторов. Существенность влияния фактора определяется путём проверки гипотез: Если влияние фактора не существенно, то несущественна и разница между классами
градации этого фактора и в ходе дисперсионного анализа нулевая гипотеза H
0
не отвергается. Если влияние фактора существенно, то нулевая гипотеза
H
0
отвергается: не все классы градации
имеют одно и то же среднее значение, то есть среди возможных разниц между классами градации одна или
несколько являются существенными. Ещё некоторые понятия дисперсионного анализа.
Статистическим комплексом в дисперсионном анализе называется таблица эмпирических
данных. Если во всех классах градаций одинаковое число вариантов, то статистический комплекс
называется однородным (гомогенным), если число вариантов разное - разнородным (гетерогенным). В зависимости от числа оцениваемых факторов различают однофакторный, двухфакторый
и многофакторный дисперсионный анализ.
основан на том, что
сумму квадратов отклонений статистического комплекса возможно разделить на компоненты: SS
= SS
a
+ SS
e
, SS
SS
a
a
сумма квадратов отклонений, SS
e
- необъяснённая сумма
квадратов отклонений или сумма квадратов отклонений ошибки. Если через n
i
обозначить число вариантов в каждом классе градации (группе) и a
-
общее число градаций фактора (групп), то -
общее число наблюдений и можно получить следующие формулы: общее число квадратов отклонений: объяснённая влиянием фактора a
сумма квадратов отклонений: необъяснённая сумма квадратов отклонений или сумма квадратов отклонений ошибки:
(группе). Кроме того, где -
дисперсия градации фактора (группы). Чтобы провести однофакторный дисперсионный анализ данных статистического комплекса,
нужно найти фактическое отношение Фишера - отношение дисперсии, объяснённой влиянием фактора (межрупповой), и
необъяснённой дисперсии (внутригрупповой): и сравнить его с критическим значением Фишера . Дисперсии рассчитываются следующим образом: Объяснённая дисперсия, Необъяснённая дисперсия, v
a
= a
− 1
-
число степеней свободы объяснённой дисперсии, v
e
= n
− a
-
число степеней свободы необъяснённой дисперсии, v
= n
Критическое значение отношения Фишера с определёнными значениями уровня значимости и
степеней свободы можно найти в статистических таблицах или рассчитать с помощью функции MS Excel F.ОБР
(рисунок ниже, для его увеличения щёлкнуть по нему левой кнопкой мыши). Функция требует ввести следующие данные: Вероятность - уровень значимости α
, Степени_свободы1 - число степеней свободы объяснённой дисперсии v
a
, Степени_свободы2 - число степеней свободы необъяснённой дисперсии v
e
. Если фактическое значение отношения Фишера больше критического
(), то нулевая
гипотеза отклоняется с уровнем значимости α
. Это означает, что
фактор существенно влияет на изменение данных и данные зависимы от фактора с вероятностью
P
= 1 − α
. Если фактическое значение отношения Фишера меньше критического
(), то нулевая
гипотеза не может быть отклонена с уровнем значимости α
. Это
означает, что фактор не оказывает существенного влияния на данные с вероятностью
P
= 1 − α
. Пример 1.
Требуется выяснить, влияет ли тип используемого сырья на
прибыль предприятия. В шести классах градации (группах) фактора (1-й тип, 2-й тип и т.д.) собраны данные
о прибыли от производства 1000 единиц продукции в миллионах рублей в течении 4 лет. a
= 6
и
в каждом классе (группе) n
i
= 4
наблюдения. Общее число наблюдений n
= 24
. Числа степеней свободы: v
a
= a
− 1 = 6 − 1 = 5
, v
e
= n
− a
= 24 − 6 = 18
, v
= n
− 1 = 24 − 1 = 23
. Вычислим дисперсии: Так как фактическое отношение Фишера больше критического: с уровнем значимости α
= 0,05
делаем
вывод, что прибыль предприятия в зависимости от вида сырья, использованного в производстве, существенно
отличается. Или, что то же самое, отвергаем основную гипотезу о равенстве средних во всех классах
градации фактора (группах). В только что рассмотренном примере в каждом классе градации фактора было одинаковое
число вариантов. Но, как говорилось во вступительной части, число вариантов может быть и разным. И это
ни в коей мере не усложняет процедуру дисперсионного анализа. Таков следующий пример. Пример 2.
Требуется выяснить, существует ли зависимость себестоимости
выпуска единицы продукции от величины подразделения предприятия. Фактор (величина подразделения)
делится на три класса градации (группы): малые, средние, большие. Обобщены соответствующие этим
группам данные о себестоимости выпуска единицы одного и того же вида продукции за некоторый период. Число классов градации фактора (групп) a
= 3
,
число наблюдений в классах (группах) n
1
= 4
,
n
2
= 7
,
n
3
= 6
. Общее число
наблюдений n
= 17
. Числа степеней свободы: v
a
= a
− 1 = 2
, v
e
= n
− a
= 17 − 3 = 14
, v
= n
− 1 = 16
. Вычислим суммы квадратов отклонений: Вычислим дисперсии: Вычислим фактическое отношение Фишера: Критическое значение отношения Фишера: Так как фактическое значение отношения Фишера меньше критического:
,
делаем вывод, что размер подразделения предприятия не оказывает существенного влияния на себестоимость
выпуска продукции. Или, что то же самое, с вероятностью 95% принимаем основную гипотезу о том, что
средняя себестоимость выпуска единицы одной и той же продукции в малых, средних и крупных подразделениях
предприятия существенно не различается. Однофакторный дисперсионный анализ можно провести с помощью процедуры MS Excel
Однофакторный дисперсионный анализ
. Используем его для анализа данных о связи типа
используемого сырья и прибыли предприятия из примера 1. Сервис/Анализ данных
и выбираем средство анализа
Однофакторный дисперсионный анализ
. В окошке Входной интервал
указываем область данных (в нашем случае это $A$2:$E$7).
Указываем, как сгруппирован фактор - по столбцам или по строкам (в нашем случае по строкам). Если первый
столбец содержит названия классов фактора, помечаем галочкой окно Метки в первом столбце
. В окне
Альфа
указываем уровень значимости α
= 0,05
. Во второй таблице - Дисперсионный анализ - содержатся данные о величинах для фактора
между группами и внутри групп и итоговых. Это сумма квадратов отклонений (SS), число степеней свободы
(df), дисперсия (MS). В последних трёх столбцах - фактическое значение отношения Фишера(F), p-уровень
(P-value) и критическое значение отношения Фишера (F crit). Так как фактическое значение отношения Фишера (6,89) больше критического (2,77),
с вероятностью 95% отклоняем нулевую гипотезу о равенстве средних производительности при использовании
всех типов сырья, то есть делаем вывод о том, что тип используемого сырья влияет на прибыль предприятия. Двухфакторный дисперсионный анализ применяется для того, чтобы проверить возможную
зависимость результативного признака от двух факторов - A
и B
. Тогда
a
- число градаций фактора A
и b
- число градаций фактора B
. В
статистическом комплексе сумма квадратов остатков разделяется на три компоненты: SS
= SS
a
+ SS
b
+ SS
e
, Среднее наблюдений в каждой градации фактора A
, B
. A
, Дисперсия, объяснённая влиянием фактора B
, v
a
= a
− 1
A
, v
b
= b
− 1
-
число степеней свободы дисперсии, объяснённой влиянием фактора B
, v
e
= (a
− 1)(b
− 1)
v
= ab
− 1
-
общее число степеней свободы. Если факторы не зависят друг от друга, то для определения существенности факторов
выдвигаются две нулевые гипотезы и соответствующие альтернативные гипотезы: для фактора A
: H
0
: μ
1A
= μ
2A
= ... = μ
aA
, H
1
: не все μ
iA
равны; для фактора B
: H
0
: μ
1B
= μ
2B
= ... = μ
aB
, H
1
: не все μ
iB
равны. A
Чтобы определить влияние фактора B
, нужно
фактическое отношение Фишера
сравнить с критическим отношением Фишера . α
P
= 1 − α
. α
P
= 1 − α
. Пример 3.
Дана информация о среднем потреблении топлива на 100 километров
в литрах в зависимости от объёма двигателя и вида топлива. Требуется проверить, зависит ли потребление топлива от объёма двигателя и вида топлива. Решение. Для фактора A
число классов градации
a
= 3
, для фактора B
число классов градации b
= 3
. Вычисляем суммы квадратов отклонений: Соответствующие дисперсии: A
Фактическое отношение Фишера для фактора B
Двухфакторный дисперсионный анализ без повторений можно провести с помощью процедуры MS Excel
. Используем его для анализа данных о связи типа
вида топлива и его потребления из примера 3. В меню MS Excel выполняем команду Сервис/Анализ данных
и выбираем средство анализа
Двухфакторный дисперсионный анализ без повторений
. Заполняем данные также, как и в случае с однофакторным дисперсионным анализом. В результате действия процедуры выводятся две таблицы. Первая таблица - Итоги.
В ней содержатся данные обо всех классах градации фактора: число наблюдений, суммарное значение, среднее
значение и дисперсия. Во второй таблице - Дисперсионный анализ - содержатся данные об источниках вариации:
рассеивании между строками, рассеивании между столбцами, рассеивании ошибки, общем рассеивании,
сумма квадратов отклонений (SS), число степеней свободы (df), дисперсия (MS). В последних трёх столбцах - фактическое значение отношения Фишера(F), p-уровень
(P-value) и критическое значение отношения Фишера (F crit). Фактор A
(объём двигателя) сгурппирован в строках. Так как фактическое
отношение Фишера 5,28 меньше критического 6,94, с вероятностью 95% принимаем, что потребление топлива
не зависит от объёма двигателя. Фактор B
(вид топлива) сгруппирован в столбцах.
Фактическое отношение Фишера 13,56 больше критического 6,94, поэтому с вероятностью 95% принимаем, что
потребление топлива зависит от его вида. Двухфакторный дисперсионный анализ с повторениями применяется для того, чтобы проверить
не только возможную
зависимость результативного признака от двух факторов - A
и B
, но и возможное
взаимодействие факторов A
и B
. Тогда
a
- число градаций фактора A
и b
- число градаций фактора B
, r
-
число повторений. В
статистическом комплексе сумма квадратов остатков разделяется на четыре компоненты: SS
= SS
a
+ SS
b
+ SS
ab
+ SS
e
, Среднее число наблюдений в каждой комбинации градаций факторов A
и B
, n
= abr
- общее число наблюдений. Дисперсии вычисляются следующим образом: Дисперсия, объяснённая влиянием фактора A
, Дисперсия, объяснённая влиянием фактора B
, v
a
= a
− 1
-
число степеней свободы дисперсии, объяснённой влиянием фактора A
, v
b
= b
− 1
-
число степеней свободы дисперсии, объяснённой влиянием фактора B
, v
ab
= (a
− 1)(b
− 1)
-
число степеней свободы дисперсии, объяснённой взаимодействием факторов A
и B
, v
e
= ab
(r
− 1)
-
число степеней свободы необъяснённой дисперсии или дисперсии ошибки, v
= abr
− 1
-
общее число степеней свободы. Если факторы не зависят друг от друга, то для определения существенности факторов
выдвигаются три нулевые гипотезы и соответствующие альтернативные гипотезы: для фактора A
: H
0
: μ
1A
= μ
2A
= ... = μ
aA
, H
1
: не все μ
iA
равны; для фактора B
:
Чтобы определить влияние взаимодействия факторов A
и
B
, нужно
фактическое отношение Фишера
сравнить с критическим отношением Фишера . Если фактическое отношение Фишера больше критического отношения Фишера, то следует
отклонить нулевую гипотезу с уровнем значимости α
. Это означает,
что фактор существенно влияет на данные: данные зависят от фактора с вероятностью
P
= 1 − α
. Если фактическое отношение Фишера меньше критического отношения Фишера, то следует
принять нулевую гипотезу с уровнем значимости α
. Это означает,
что фактор не оказывает существенного влияния на данные с вероятностью
P
= 1 − α
. о взаимодействии факторов A
и B
:
фактическое отношение Фишера меньше критического, следовательно, взаимодействие рекламной кампании и конкретного
магазина не существенно. Двухфакторный дисперсионный анализ с повторениями можно провести с помощью процедуры MS Excel
. Используем его для анализа данных о связи
доходов магазина с выбором конкретного магазина и рекламной кампанией из примера 4. В меню MS Excel выполняем команду Сервис/Анализ данных
и выбираем средство анализа
Двухфакторный дисперсионный анализ с повторениями
. Заполняем данные также, как и в случае с двухфакторным дисперсионным анализом без
повторений, с тем дополнением, что в окне число строк для выборки нужно ввести число повторений. В результате действия процедуры выводятся две таблицы. Первая таблица
состоит из трёх частей: две первые соответствуют каждой из двух рекламных кампаний, третья содержит
данные об обеих рекламных кампаниях. В столбцах таблицы содержится информация обо всех классах градации
второго фактора - магазина: число наблюдений, суммарное значение, среднее
значение и дисперсия. Во второй таблице - данные о
сумме квадратов отклонений (SS), числе степеней свободы (df), дисперсии (MS), фактическом значение отношения
Фишера(F), p-уровне (P-value) и критическом значении отношения Фишера (F crit) для различных источниках
вариации: двух факторах, которые даны в строках (выборка) и столбцах, взаимодействии факторов, ошибки (внутри) и
суммарных показателях (итого). Для фактора B
фактическое отношение Фишера
больше критического, следовательно, с вероятностью 95% доходы существенно различаются между магазинами. Для взаимодействия факторов A
и B
фактическое отношение Фишера меньше критического, следовательно, с вероятностью 95% взаимодействие рекламной кампании и конкретного
магазина не существенно. Всё по теме "Математическая статистика"![]() ,
,
![]()
![]() .
.
![]()



![]() то и распределены тоже нормально:
то и распределены тоже нормально:



![]()
Однофакторный дисперсионный анализ: суть метода, формулы, примеры
Суть метода, формулы
![]() ,
,![]() ,
,![]() ,
,![]() -
общее среднее наблюдений,
-
общее среднее наблюдений,

Однофакторный дисперсионный анализ: примеры
Тип сырья
2014
2015
2016
2017
1-й
7,21
7,55
7,29
7,6
2-й
7,89
8,27
7,39
8,18
3-й
7,25
7,01
7,37
7,53
4-й
7,75
7,41
7,27
7,42
5-й
7,7
8,28
8,55
8,6
6-й
7,56
8,05
8,07
7,84
Среднее Дисперсия
7,413
0,0367
7,933
0,1571
7,290
0,0480
7,463
0,0414
8,283
0,1706
7,880
0,0563




![]()
![]() .
.![]() .
.
малый
средний
большой
48
47
46
50
61
57
63
63
57
72
47
55
43
32
59
59
58
Среднее
58,6
54,0
51,0
Дисперсия
128,25
65,00
107,60




![]() ,
,![]() .
.![]() .
.Однофакторный дисперсионный анализа в MS Excel



MS
F
P-value
F crit
0,58585
6,891119
0,000936
2,77285
0,085017
Двухфакторный дисперсионный анализ без повторений: суть метода, формулы, пример
![]() - общая сумма квадратов отклонений,
- общая сумма квадратов отклонений,![]() - объяснённая
влиянием фактора A
сумма квадратов отклонений,
- объяснённая
влиянием фактора A
сумма квадратов отклонений,![]() - объяснённая
влиянием фактора B
сумма квадратов отклонений,
- объяснённая
влиянием фактора B
сумма квадратов отклонений,![]()
![]() -
общее среднее наблюдений,
-
общее среднее наблюдений,![]()
Двухфакторный дисперсионный анализ без повторений: пример
![]() ,
,![]() ,
,![]() ,
,![]() .
.![]() ,
,![]() ,
,![]() .
.![]()
![]() .
Так как фактическое отношение Фишера меньше критического, с вероятностью 95% принимаем гипотезу о том, что
объём двигателя не влияет на потребление топлива. Однако, если мы выбираем уровень значимости
α
= 0,1
, то фактическое значение отношения Фишера
и тогда с вероятностью
95% можем принять, что объём двигателя влияет на потребление топлива.
.
Так как фактическое отношение Фишера меньше критического, с вероятностью 95% принимаем гипотезу о том, что
объём двигателя не влияет на потребление топлива. Однако, если мы выбираем уровень значимости
α
= 0,1
, то фактическое значение отношения Фишера
и тогда с вероятностью
95% можем принять, что объём двигателя влияет на потребление топлива.![]() , критическое значение
отношения Фишера:
, критическое значение
отношения Фишера: ![]() .
Так как фактическое отношение Фишера больше критического значения отношения Фишера, с вероятностью 95%
принимаем, что вид топлива влияет на его потребление.
.
Так как фактическое отношение Фишера больше критического значения отношения Фишера, с вероятностью 95%
принимаем, что вид топлива влияет на его потребление.
Двухфакторный дисперсионный анализ без повторений в MS Excel


MS
F
P-value
F crit
3,13
5,275281
0,075572
6,94476
8,043333
13,55618
0,016529
6,944276
0,593333
Двухфакторный дисперсионный анализ с повторениями: суть метода, формулы, пример
![]() - общая сумма квадратов отклонений,
- общая сумма квадратов отклонений,![]() - объяснённая
влиянием фактора A
сумма квадратов отклонений,
- объяснённая
влиянием фактора A
сумма квадратов отклонений,![]() - объяснённая
влиянием фактора B
сумма квадратов отклонений,
- объяснённая
влиянием фактора B
сумма квадратов отклонений,![]() - объяснённая
влиянием взаимодействия факторов A
и B
сумма квадратов отклонений,
- объяснённая
влиянием взаимодействия факторов A
и B
сумма квадратов отклонений,![]() - необъяснённая сумма
квадратов отклонений или сумма квадратов отклонений ошибки,
- необъяснённая сумма
квадратов отклонений или сумма квадратов отклонений ошибки,![]() -
общее среднее наблюдений,
-
общее среднее наблюдений,![]() -
среднее наблюдений в каждой градации фактора A
,
-
среднее наблюдений в каждой градации фактора A
,![]() -
среднее число наблюдений в каждой градации фактора B
,
-
среднее число наблюдений в каждой градации фактора B
,![]() -
дисперсия, объяснённая взаимодействием факторов A
и B
,
-
дисперсия, объяснённая взаимодействием факторов A
и B
,![]() -
необъяснённая дисперсия или дисперсия ошибки,
-
необъяснённая дисперсия или дисперсия ошибки,Двухфакторный дисперсионный анализ с повторениями: пример
Двухфакторный дисперсионный анализ с повторениями в MS Excel


MS
F
P-value
F crit
8,013339
0,500252
0,492897
4,747221
189,1904
11,81066
0,001462
3,88529
6,925272
0,432327
0,658717
3,88529
16,01861