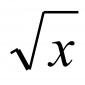
Этот метод состоит в том, что в качестве точечной оценки параметра принимается то значение параметра , при котором функция правдоподобия достигает своего максимума.
Для случайной наработки до отказа с плотностью вероятности f(t, ) функция правдоподобия определяется формулой 12.11: ![]() , т.е. представляет из себя совместную плотность вероятности независимых измерений случайной величины τ с плотностью вероятности f(t, ).
, т.е. представляет из себя совместную плотность вероятности независимых измерений случайной величины τ с плотностью вероятности f(t, ).
Если случайная величина дискретна и принимает значения Z 1 ,Z 2
…, соответственно с вероятностями P 1 (α),P 2 (α)…, , то функция правдоподобия берётся в ином виде, а именно: ![]() , где индексы у вероятностей показывают, что наблюдались значения .
, где индексы у вероятностей показывают, что наблюдались значения .
Оценки максимального правдоподобия параметра определяются из уравнения правдоподобия (12.12).
Значение метода максимального правдоподобия выясняется следующими двумя предположениями:
Если для параметра существует эффективная оценка , то уравнение правдоподобия (12.12) имеет единственное решение .
При некоторых общих условиях аналитического характера, наложенных на функции f(t, ) решение уравнения правдоподобия сходится при к истинному значению параметра .
Рассмотрим пример использования метода максимального правдоподобия для параметров нормального распределения.
Пример:
Имеем:  , , t i (i=1..N)
выборка из совокупности с плотностью распределения .
, , t i (i=1..N)
выборка из совокупности с плотностью распределения .
Требуется найти оценку максимального подобия.
Функция правдоподобия:  ;
;
![]() .
.
Уравнения правдоподобия: ![]() ;
;
![]() ;
;
Решение этих уравнений имеет вид: - статистическое среднее; ![]() - статистическая дисперсия. Оценка является смещённой. Не смещённой оценкой будет оценка:
- статистическая дисперсия. Оценка является смещённой. Не смещённой оценкой будет оценка: ![]() .
.
Основным недостатком метода максимального правдоподобия являются вычислительные трудности, возникающие при решение уравнений правдоподобия, которые, как правило, являются трансцендентными.
Метод моментов.
Этот метод предложен К.Пирсоном и является самым первым общим методом точечной оценки неизвестных параметров. Он до сих пор широко используется в практической статистике, поскольку нередко приводит к сравнительно несложной вычислительной процедуре. Идея этого метода состоит в том, что моменты распределения зависящие от неизвестных параметров, приравниваются к эмпирическим моментам. Взяв число моментов, равное числу неизвестных параметров, и составив соответствующие уравнения, мы получим необходимое число уравнений. Чаще всего вычисляются первые два статистических момента: выборочное среднее ; и выборочная дисперсия ![]() . Оценки, получаемые с помощью метода моментов, не являются наилучшими с точки зрения их эффективности. Однако очень часто они используются в качестве первых приближений.
. Оценки, получаемые с помощью метода моментов, не являются наилучшими с точки зрения их эффективности. Однако очень часто они используются в качестве первых приближений.
Рассмотрим пример использования метода моментов.
Пример: Рассмотрим экспоненциальное распределение:
![]() t>0; λ<0; t i (i=1..N)
– выборка из совокупности с плотностью распределения . Требуется найти оценку для параметра λ.
t>0; λ<0; t i (i=1..N)
– выборка из совокупности с плотностью распределения . Требуется найти оценку для параметра λ.
Составляем уравнение: ![]() . Таким образом, иначе .
. Таким образом, иначе .
Метод квантилей.
Это такой же эмпирический метод, как и метод моментов. Он состоит в том, что квантиль теоретического распределения приравниваются к эмпирической квантили. Если оценке подлежат несколько параметров, то соответствующие равенства пишутся для нескольких квантилей.
Рассмотрим случай, когда закон распределения F(t,α,β)
с двумя неизвестными параметрами α, β
. Пусть функция F(t,α,β
) имеет непрерывно дифференцируемую плотность , принимающую положительные значения для любых возможных значений параметров α, β.
Если испытания проводить по плану , r>>1
, то момент появления - го отказа можно рассматривать как эмпирическую квантиль уровня , i=1,2
… , ![]() - эмпирическая функция распределения. Если бы t l
и t
r – моменты появления l-го и r-го отказов известны точно, значения параметров α
и β
можно было бы найти из уравнений
- эмпирическая функция распределения. Если бы t l
и t
r – моменты появления l-го и r-го отказов известны точно, значения параметров α
и β
можно было бы найти из уравнений
В работах, предназначенных для первоначального знакомства с математической статистикой, обычно рассматривают оценки максимального правдоподобия (сокращенно ОМП):
Таким образом, сначала строится плотность распределения вероятностей, соответствующая выборке. Поскольку элементы выборки независимы, то эта плотность представляется в виде произведения плотностей для отдельных элементов выборки. Совместная плотность рассматривается в точке, соответствующей наблюденным значениям. Это выражение как функция от параметра (при заданных элементах выборки) называется функцией правдоподобия. Затем тем или иным способом ищется значение параметра, при котором значение совместной плотности максимально. Это и есть оценка максимального правдоподобия.
Хорошо известно, что оценки максимального правдоподобия входят в класс наилучших асимптотически нормальных оценок. Однако при конечных объемах выборки в ряде задач ОМП недопустимы, т.к. они хуже (дисперсия и средний квадрат ошибки больше), чем другие оценки, в частности, несмещенные. Именно поэтому в ГОСТ 11.010-81 для оценивания параметров отрицательного биномиального распределения используются несмещенные оценки, а не ОМП. Из сказанного следует априорно предпочитать ОМП другим видам оценок можно - если можно - лишь на этапе изучения асимптотического поведения оценок.
В отдельных случаях ОМП находятся явно, в виде конкретных формул, пригодных для вычисления.
В большинстве случаев аналитических решений не существует, для нахождения ОМП необходимо применять численные методы. Так обстоит дело, например, с выборками из гамма-распределения или распределения Вейбулла-Гнеденко. Во многих работах каким-либо итерационным методом решают систему уравнений максимального правдоподобия или впрямую максимизируют функцию правдоподобия.
Однако применение численных методов порождает многочисленные проблемы. Сходимость итерационных методов требует обоснования. В ряде примеров функция правдоподобия имеет много локальных максимумов, а потому естественные итерационные процедуры не сходятся. Для данных ВНИИ железнодорожного транспорта по усталостным испытаниям стали уравнение максимального правдоподобия имеет 11 корней. Какой из одиннадцати использовать в качестве оценки параметра?
Как следствие осознания указанных трудностей, стали появляться работы по доказательству сходимости алгоритмов нахождения оценок максимального правдоподобия для конкретных вероятностных моделей и конкретных алгоритмов.
Однако теоретическое доказательство сходимости итерационного алгоритма - это еще не всё. Возникает вопрос об обоснованном выборе момента прекращения вычислений в связи с достижением требуемой точности. В большинстве случаев он не решен.
Но и это не все. Точность вычислений необходимо увязывать с объемом выборки - чем он больше, тем точнее надо находить оценки параметров, в противном случае нельзя говорить о состоятельности метода оценивания. Более того, при увеличении объема выборки необходимо увеличивать и количество используемых в компьютере разрядов, переходить от одинарной точности расчетов к двойной и далее - опять-таки ради достижения состоятельности оценок.
Таким образом, при отсутствии явных формул для оценок максимального правдоподобия нахождение ОМП натыкается на ряд проблем вычислительного характера. Специалисты по математической статистике позволяют себе игнорировать все эти проблемы, рассуждая об ОМП в теоретическом плане. Однако прикладная статистика не может их игнорировать. Отмеченные проблемы ставят под вопрос целесообразность практического использования ОМП.
Пример 1. В статистических задачах стандартизации и управления качеством используют семейство гамма-распределений. Плотность гамма-распределения имеет вид

Плотность вероятности в формуле (7) определяется тремя параметрами a, b, c , где a >2, b >0. При этом a является параметром формы, b - параметром масштаба и с - параметром сдвига. Множитель 1/Г(а) является нормировочным, он введен, чтобы
Здесь Г(а) - одна из используемых в математике специальных функций, так называемая "гамма-функция", по которой названо и распределение, задаваемое формулой (7),

Подробные решения задач оценивания параметров для гамма-распределения содержатся в разработанном нами государственном стандарте ГОСТ 11,011-83 «Прикладная статистика. Правила определения оценок и доверительных границ для параметров гамма-распределения». В настоящее время эта публикация используется в качестве методического материала для инженерно-технических работников промышленных предприятий и прикладных научно-исследовательских институтов.
Поскольку гамма-распределение зависит от трех параметров, то имеется 2 3 - 1 = 7 вариантов постановок задач оценивания. Они описаны в табл. 1. В табл. 2 приведены реальные данные о наработке резцов до предельного состояния, в часах. Упорядоченная выборка (вариационный ряд) объема n = 50 взята из государственного стандарта. Именно эти данные будут служить исходным материалом для демонстрации тех или иных методов оценивания параметров.
Выбор «наилучших» оценок в определенной параметрической модели прикладной статистики - научно-исследовательская работа, растянутая во времени. Выделим два этапа. Этап асимптотики : оценки строятся и сравниваются по их свойствам при безграничном росте объема выборки. На этом этапе рассматривают такие характеристики оценок, как состоятельность, асимптотическая эффективность и др. Этап конечных объемов выборки: оценки сравниваются, скажем, при n = 10. Ясно, что исследование начинается с этапа асимптотики: чтобы сравнивать оценки, надо сначала их построить и быть уверенными, что они не являются абсурдными (такую уверенность дает доказательство состоятельности).
Пример 2. Оценивание методом моментов параметров гамма-распределения в случае трех неизвестных параметров (строка 7 таблицы 1).
В соответствии с проведенными выше рассуждениями для оценивания трех параметров достаточно использовать три выборочных момента - выборочное среднее арифметическое:
выборочную дисперсию
и выборочный третий центральный момент
Приравнивая теоретические моменты, выраженные через параметры распределения, и выборочные моменты, получаем систему уравнений метода моментов:
Решая эту систему, находим оценки метода моментов. Подставляя второе уравнение в третье, получаем оценку метода моментов для параметра сдвига:
Подставляя эту оценку во второе уравнение, находим оценку метода моментов для параметра формы:

Наконец, из первого уравнения находим оценку для параметра сдвига:
Для реальных данных, приведенных выше в табл. 2, выборочное среднее арифметическое = 57,88, выборочная дисперсия s 2 = 663,00, выборочный третий центральный момент m 3 = 14927,91. Согласно только что полученным формулам оценки метода моментов таковы: a * = 5,23; b * = 11,26, c * = - 1,01.
Оценки параметров гамма-распределения, полученные методом моментов, являются функциями от выборочных моментов. В соответствии со сказанным выше они являются асимптотически нормальными случайными величинами. В табл. 3 приведены оценки метода моментов и их асимптотические дисперсии при различных вариантах сочетания известных и неизвестных параметров гамма-распределения.
Все оценки метода моментов, приведенные в табл. 3, включены в государственный стандарт. Они охватывают все постановки задач оценивания параметров гамма-распределения (см. табл. 1), кроме тех, когда неизвестен только один параметр - a или b . Для этих исключительных случаев разработаны специальные методы оценивания.
Поскольку асимптотическое распределение оценок метода моментов известно, то не представляет труда формулировка правил проверки статистических гипотез относительно значений параметров распределений, а также построение доверительных границ для параметров. Например, в вероятностной модели, когда все три параметра неизвестны, в соответствии с третьей строкой таблицы 3 нижняя доверительная граница для параметра а , соответствующая доверительной вероятности г = 0,95, в асимптотике имеет вид
а верхняя доверительная граница для той же доверительной вероятности такова
где а * - оценка метода моментов параметра формы (табл. 3).
Пример 3. Найдем ОМП для выборки из нормального распределения, каждый элемент которой имеет плотность

Таким образом, надо оценить двумерный параметр (m , у 2).
Произведение плотностей вероятностей для элементов выборки, т.е. функция правдоподобия, имеет вид
Требуется решить задачу оптимизации
Как и во многих иных случаях, задача оптимизации проще решается, если прологарифмировать функцию правдоподобия, т.е. перейти к функции
называемой логарифмической функцией правдоподобия. Для выборки из нормального распределения
Необходимым условием максимума является равенство 0 частных производных от логарифмической функции правдоподобия по параметрам, т.е.
Система (10) называется системой уравнений максимального правдоподобия. В общем случае число уравнений равно числу неизвестных параметров, а каждое из уравнений выписывается путем приравнивания 0 частной производной логарифмической функции правдоподобия по тому или иному параметру.
При дифференцировании по m первые два слагаемых в правой части формулы (9) обращаются в 0, а последнее слагаемое дает уравнение
Следовательно, оценкой m * максимального правдоподобия параметра m является выборочное среднее арифметическое,
Для нахождения оценки дисперсии необходимо решить уравнение
Легко видеть, что
Следовательно, оценкой (у 2)* максимального правдоподобия для дисперсии у 2 с учетом найденной ранее оценки для параметра m является выборочная дисперсия,
Итак, система уравнений максимального правдоподобия решена аналитически, ОМП для математического ожидания и дисперсии нормального распределения - это выборочное среднее арифметическое и выборочная дисперсия. Отметим, что последняя оценка является смещенной.
Отметим, что в условиях примера 3 оценки метода максимального правдоподобия совпадают с оценками метода моментов. Причем вид оценок метода моментов очевиден и не требует проведения каких-либо рассуждений.
Пример 4. Попытаемся проникнуть в тайный смысл следующей фразы основателя современной статистики Рональда Фишера: “нет ничего проще, чем придумать оценку параметра”. Классик иронизировал: он имел в виду, что легко придумать плохую оценку. Хорошую оценку не надо придумывать (!) - ее надо получать стандартным образом, используя принцип максимального правдоподобия.
Задача. Согласно H 0 математические ожидания трех независимых пуассоновских случайных величин связаны линейной зависимостью: .
Даны реализации этих величин. Требуется оценить два параметра линейной зависимости и проверить H 0 .
Для наглядности можно представить линейную регрессию, которая в точках принимает средние значения. Пусть получены значения. Что можно сказать о величине и справедливости H 0 ?
Наивный подход
Казалось бы, оценить параметры можно из элементарного здравого смысла. Оценку наклона прямой регрессии получим, поделив приращение при переходе от x 1 =-1 к x 3 =+1 на, а оценку значения найдем как среднее арифметическое:
Легко проверить, что математические ожидания оценок равны (оценки несмещенные).
После того как оценки получены, H 0 проверяют как обычно с помощью хи-квадрат критерия Пирсона:
Оценки ожидаемых частот можно получить, исходя из оценок:

При этом, если наши оценки ”правильные”, то расстояние Пирсона будет распределено как случайная величина хи-квадрат с одной степенью свободы: 3-2=1. Напомним, что мы оцениваем два параметра, подгоняя данные под нашу модель. При этом сумма не фиксирована, поэтому дополнительную единицу вычитать не нужно.
Однако, подставив, получим странный результат:

С одной стороны ясно, что для данных частот нет оснований отвергать H 0 , но мы не в состоянии это проверить с помощью хи-квадрат критерия, так как оценка ожидаемой частоты в первой точке оказывается отрицательной. Итак, найденные из “здравого смысла” оценки не позволяют решить задачу в общем случае.
Метод максимального правдоподобия
Случайные величины независимы и имеют пуассоновское распределение. Вероятность получить значения равна:
Согласно принципу максимального правдоподобия значения неизвестных параметров надо искать, требуя, чтобы вероятность получить значения была максимальной:
Если постоянны, то мы имеем дело с обычной вероятностью. Фишер предложил новый термин “правдоподобие” для случая, когда постоянны, а переменными считаются. Если правдоподобие оказывается произведением вероятностей независимых событий, то естественно превратить произведение в сумму и дальше иметь дело с логарифмом правдоподобия:
Здесь все слагаемые, которые не зависят от, обозначены и в окончательном выражении отброшены. Чтобы найти максимум логарифма правдоподобия, приравняем производные по к нулю:
Решая эти уравнения, получим:
Таковы “правильные” выражения для оценок. Оценка среднего значения совпадает с тем, что предлагал здравый смысл, однако оценки для наклона различаются: . Что можно сказать по поводу формулы для?
- 1) Кажется странным, что ответ зависит от частоты в средней точке, так как величина определяет угол наклона прямой.
- 2) Тем не менее, если справедлива H 0 (линия регрессии - прямая), то при больших значениях наблюдаемых частот, они становятся близки к своим математическим ожиданием. Поэтому: , и оценка максимального правдоподобия становится близка к результату, полученному из здравого смысла.
3) Преимущества оценки начинают ощущаться, когда мы замечаем, что все ожидаемые частоты теперь оказываются всегда положительными:


Это было не так для “наивных” оценок, поэтому применить хи-квадрат критерий можно было не всегда (попытка заменить отрицательную или равную нулю ожидаемую частоту на единицу не спасает положения).
4) Численные расчеты показывают, что наивными оценками можно пользоваться только, если ожидаемые частоты достаточно велики. Если использовать их при малых значениях, то вычисленное расстояние Пирсона часто будет оказываться чрезмерно большим.
Вывод : Правильный выбор оценки важен, так как в противном случае проверить гипотезу с помощью критерия хи-квадрат не удастся. Оценка, казалось бы, очевидная может оказаться непригодной!
Метод максимального правдоподобия (ММП) является одним из наиболее широко используемых методов в статистике и эконометрике. Для его применения необходимо знание закона распределения исследуемой случайной величины.
Пусть имеется некоторая случайная величина У с заданным законом распределения ДУ). Параметры этого закона неизвестны и их нужно найти. В общем случае величину Y рассматривают как многомерную, т.е. состоящую из нескольких одномерных величин У1, У2, У3 ..., У.
Предположим, что У – одномерная случайная величина и ее отдельные значения являются числами. Каждое из них (У],у 2, у3, ...,у„) рассматривается как реализация не одной случайной величины У, а η случайных величин У1; У2, У3 ..., У„. То есть:
уj – реализация случайной величины У];
у2 – реализация случайной величины У2;
уз – реализация случайной величины У3;
у„ – реализация случайной величины У„.
Параметры закона распределения вектора У, состоящего из случайных величин Y b Y 2, У3,У„, представляют как вектор Θ, состоящий из к параметров: θχ, θ2,в к. Величины Υ ν Υ 2, У3,..., Υ η могут быть распределены как с одинаковыми параметрами, так и с различными; некоторые параметры могут совпадать, а другие различаться. Конкретный ответ на этот вопрос зависит от той задачи, которую решает исследователь.
Например, если стоит задача определения параметров закона распределения случайной величины У, реализацией которой являются величины У1; У2, У3, У,„ то предполагают, что каждая из этих величин распределена так же, как величина У. Иначе говоря, любая величина У, описывается одним и тем же законом распределения/(У, ), причем с одними и теми же параметрами Θ: θχ, θ2,..., д к.
Другой пример – нахождение параметров уравнения регрессии. В этом случае каждая величина У, рассматривается как случайная величина, имеющая "собственные" параметры распределения, которые могут частично совпадать с параметрами распределения других случайных величин, а могут и полностью различаться. Более подробно применение ММП для нахождения параметров уравнения регрессии будет рассмотрено ниже.
В рамках метода максимального правдоподобия совокупность имеющихся значений У], у2, у3, ...,у„ рассматривается как некоторая фиксированная, неизменная. То есть закон /(У;) есть функция от заданной величиныу, и неизвестных параметров Θ. Следовательно, для п наблюдений случайной величины У имеется п законов /(У;).
Неизвестные параметры этих законов распределения рассматриваются как случайные величины. Они могут меняться, однако приданном наборе значений Уі,у2,у3, ...,у„ наиболее вероятны конкретные значения параметров. Иначе говоря, вопрос ставится таким образом: каковы должны быть параметры Θ, чтобы значения уj, у2, у3, ...,у„ были наиболее вероятны?
Для ответа на него нужно найти закон совместного распределения случайных величин У1; У2, У3,..., Уп –КУі, У 2, Уз, У„). Если предположить, что наблюдаемые нами величиныу^ у2,у3, ...,у„ независимы, то он равен произведению п законов/
(У;) (произведению вероятностей появления данных значений для дискретных случайных величин или произведению плотностей распределения для непрерывных случайных величин):
![]()
Чтобы подчеркнуть тот факт, что в качестве переменных рассматриваются искомые параметры Θ, введем в обозначение закона распределения еще один аргумент – вектор параметров Θ:

С учетом введенных обозначений закон совместного распределения независимых величин с параметрами будет записан в виде
![]() (2.51)
(2.51)
Полученную функцию (2.51) называют функцией максимального правдоподобия и обозначают :
![]()
Еще раз подчеркнем тот факт, что в функции максимального правдоподобия значения У считаются фиксированными, а переменными являются параметры вектора (в частном случае – один параметр). Часто для упрощения процесса нахождения неизвестных параметров функцию правдоподобия логарифмируют, получая логарифмическую функцию правдоподобия
Дальнейшее решение по ММП предполагает нахождение таких значений Θ, при которых функция правдоподобия (или ее логарифм) достигает максимума. Найденные значения Θ; называют оценкой максимального правдоподобия.
Методы нахождения оценки максимального правдоподобия достаточно разнообразны. В простейшем случае функция правдоподобия является непрерывно дифференцируемой и имеет максимум в точке, для которой
В более сложных случаях максимум функции максимального правдоподобия не может быть найден путем дифференцирования и решения уравнения правдоподобия, что требует поиска других алгоритмов его нахождения, в том числе итеративных.
Оценки параметров, полученные с использованием ММП, являются:
- – состоятельными , т.е. с увеличением объема наблюдений разница между оценкой и фактическим значением параметра приближается к нулю;
- – инвариантными : если получена оценка параметра Θ, равная 0L, и имеется непрерывная функция q(0), то оценкой значения этой функции будет величина q(0L). В частности, если с помощью ММП мы оценили величину дисперсии какого-либо показателя (af ), то корень из полученной оценки будет оценкой среднего квадратического отклонения (σ,), полученной по ММП.
- – асимптотически эффективными ;
- – асимптотически нормально распределенными.
Последние два утверждения означают, что оценки параметров, полученные по ММП, проявляют свойства эффективности и нормальности при бесконечно большом увеличении объема выборки.
Для нахождения параметров множественной линейной регрессии вида
необходимо знать законы распределения зависимых переменных 7; или случайных остатков ε,. Пусть переменная Y t распределена по нормальному закону с параметрами μ, , σ, . Каждое наблюдаемое значение у, имеет, в соответствии с определением регрессии, математическое ожидание μ, = МУ„ равное его теоретическому значению при условии, что известны значения параметров регрессии в генеральной совокупности
где xfl, ..., x ip – значения независимых переменных в і -м наблюдении. При выполнении предпосылок применения МНК (предпосылок построения классической нормальной линейной модели), случайные величины У, имеют одинаковую дисперсию
![]()
Дисперсия величины определяется по формуле
![]()
Преобразуем эту формулу:
При выполнении условий Гаусса – Маркова о равенстве нулю математического ожидания случайных остатков и постоянстве их дисперсий можно перейти от формулы (2.52) к формуле
![]()
Иначе говоря, дисперсии случайной величины У,- и соответствующих ей случайных остатков совпадают.
Выборочную оценку математического ожидания случайной величины Yj будем обозначать
![]()
а оценку ее дисперсии (постоянной для разных наблюдений) как Sy.
Если предположить независимость отдельных наблюдений y it то получим функцию максимального правдоподобия
 (2.53)
(2.53)
В приведенной функции делитель является константой и не оказывает влияния на нахождение ее максимума. Поэтому для упрощения расчетов он может быть опущен. С учетом этого замечания и после логарифмирования функция (2.53) примет вид
В соответствии с ММП найдем производные логарифмической функции правдоподобия по неизвестным параметрам

Для нахождения экстремума приравняем полученные выражения к нулю. После преобразований получим систему
 (2.54)
(2.54)
Эта система соответствует системе, полученной по методу наименьших квадратов. То есть ММП и МНК дают одинаковые результаты, если соблюдаются предпосылки МНК. Последнее выражение в системе (2.54) дает оценку дисперсии случайной переменной 7, или, что одно и то же, дисперсии случайных остатков. Как было отмечено выше (см. формулу (2.23)), несмещенная оценка дисперсии случайных остатков равна
Аналогичная оценка, полученная с применением ММП (как следует из системы (2.54)), вычисляется по формуле
т.е. является смещенной .
Мы рассмотрели случай применения ММП для нахождения параметров линейной множественной регрессии при условии, что величина У, нормально распределена. Другой подход к нахождению параметров той же регрессии заключается в построении функции максимального правдоподобия для случайных остатков ε,. Для них также предполагается нормальное распределение с параметрами (0, σε). Нетрудно убедиться, что результаты решения в этом случае совпадут с результатами, полученными выше.
Известный таксономист Джо Фельзенштейн (Felsenstein, 1978) был первым, кто предложил оценивать филогенетические теории не на основе парсимо-
нии, а средствами математической статистистики. В результате был разработан метод максимального правдоподобия (maximum likelihood).
Этот метод основывается на предварительных знаниях о возможных путях эволюции, то есть требует создания модели изменений признаков перед проведением анализа. Именно для построения этих моделей и привлекаются законы статистики.
Под правдоподобим понимается вероятность наблюдения данных в случае принятия определенной модели событий. Различные модели могут делать наблюдаемые данные более или менее вероятными. Например, если вы подбрасываете монету и получаете «орлов» только в одном случае из ста, тогда вы можете предположить, что эта монета бракованная. В случае принятия вами данной модели, правдоподобие полученного результата будет достаточно высоким. Если же вы основываетесь на модели, согласно которой монета является небракованной, то вы могли бы ожидать увидеть «орлов» в пятидесяти случаях, а не в одном. Получить только одного «орла» при ста подбрасываниях небракованной монеты статистически маловероятно. Другими словами, правдоподобие получения результата один «орел» на сто «решек» является в модели небракованной монеты очень низким.
Правдоподобие – это математическая величина. Обычно оно вычисляется по формуле:
где Pr(D|H) – это вероятность получения данных D в случае принятия гипотезы H. Вертикальная черта в формуле читается как «для данной». Поскольку L часто оказывается небольшой величиной, то обычно в исследованиях используется натуральный логарифм правдоподобия.
Очень важно различать вероятность получения наблюдаемых данных и вероятность того, что принятая модель событий правильна. Правдоподобие данных ничего не говорит о вероятности модели самой по себе. Философ-биолог Э.Собер (Sober) использовал следующий пример для того, чтобы сделать ясным это различие. Представьте, что вы слышите сильный шум в комнате над вами. Вы могли бы предположить, что это вызвано игрой гномов в боулинг на чердаке. Для данной модели ваше наблюдение (сильный шум над вами) имеет высокое правдоподобие (если бы гномы действительно играли в боулинг над вами, вы почти наверняка услышали бы это). Однако, вероятность того, что ваша гипотеза истинна, то есть, что именно гномы вызвали этот шум, – нечто совсем иное. Почти наверняка это были не гномы. Итак, в этом случае ваша гипотеза обеспечивает имеющимся данным высокое правдоподобие, но сама по себе в высшей степени маловероятна.
Используя данную систему рассуждений, метод максимального правдоподобия позволяет статистически оценивать филогенетические деревья, полученные средствами традиционной кладистики. По сути, этот метод заключа-
ется в поиске кладограммы, обеспечивающей наиболее высокую вероятность имеющегося набора данных.
Рассмотрим пример, иллюстрирующий применение метода максимального правдоподобия. Предположим, что у нас имеется четыре таксона, для которых установлены последовательности нуклеотидов определенного сайта ДНК (рис.16).

Если модель предполагает возможность реверсий, то мы можем укоренить это дерево в любом узле. Одно из возможных корневых деревьев изображено на рис. 17.2.
Мы не знаем, какие нуклеотиды присутствовали в рассматриваемом локусе у общих предков таксонов 1-4 (эти предки соответствуют на кладограмме узлам X и Y). Для каждого из этих узлов существует по четыре варианта нуклеотидов, которые могли там находиться у предковых форм, что в результате дает 16 филогенетических сценариев, приводящих к дереву 2. Один из таких сценариев изображен на рис. 17.3.
Вероятность данного сценария может быть определена по формуле:
где P A – вероятность присутствия нуклеотида A в корне дерева, которая равна средней частоте нуклеотида А (в общем случае = 0,25); P AG – вероятность замены А на G; P AC – вероятность замены А на С; P AT – вероятность замены А на T; последние два множителя – это вероятность созраниния нуклеотида T в узлах X и Y соответственно.
Еще один возможный сценарий, который позволяет получить те же данные, показан на рис. 17.4. Поскольку существует 16 подобных сценариев, может быть определена вероятность каждого из них, а сумма этих вероятностей будет вероятностью дерева, изображенного на рис. 17.2:
Где P tree 2 – это вероятность наблюдения данных в локусе, обозначенном звездочкой, для дерева 2.
Вероятность наблюдения всех данных во всех локусах данной последовательности является произведением вероятностей для каждого локуса i от 1 до N:

Поскольку эти значения очень малы, используется и другой показатель – натуральный логарифм правдоподобия lnL i для каждого локуса i. В этом случае логарифм правдоподобия дерева является суммой логарифмов правдоподобий для каждого локуса:

Значение lnL tree – это логарифм правдоподобия наблюдения данных при выборе определенной эволюционной модели и дерева с характерной для него
последовательностью ветвления и длиной ветвей. Компьютерные программы, применяемые в методе максимального правдоподобия (например, уже упоминавшийся кладистический пакет PAUP), ведут поиск дерева с максимальным показателем lnL. Удвоенная разность логарифмов правдоподобий двух моделей 2Δ (где Δ = lnL tree A- lnL treeB) подчиняется известному статистическому распределению х 2 . Благодаря этому можно оценить, действительно ли одна модель достоверно лучше, чем другая. Это делает метод максимального правдоподобия мощным средством тестирования гипотез.
В случае четырех таксонов требуется вычисления lnL для 15 деревьев. При большом числе таксонов оценить все деревья оказывается невозможным, поэтому для поиска используются эвристические методы (см. выше).
В рассмотренном примере мы использовали значения вероятностей замены (субституции) нуклеотидов в процессе эволюции. Вычисление этих вероятностей является самостоятельно статистической задачей. Для того чтобы реконструировать эволюционное дерево, мы должны сделать определенные допущения по поводу процесса субституции и выразить эти допущения в виде модели.
В самой простой модели вероятности замен какого-либо нуклеотида на любой другой нуклеотид признаются равными. Эта простая модель имеет только один параметр - скорость субституции и известна как однопарамет-рическая модель Джукса - Кантора или JC (Jukes, Cantor, 1969). При использовании этой модели нам необходимо знать скорость, с которой происходит субституция нуклеотидов. Если мы знаем, что в момент времени t= 0 в некотором сайте присутствует нуклеотид G, то мы можем вычислить вероятность того, что в этом сайте через некоторый промежуток времени t нуклеотид G сохранится, и вероятность, того, что в этом сайте произойдет замена на другой нуклеотид, например A. Эти вероятности обозначаются как P(gg) и P (ga) соответственно. Если скорость субституции равна некоторому значению α в единицу времени, тогда

Поскольку в соответствии с однопараметрической моделью любые субституции равновероятны, более общее утверждение будет выглядеть следующим образом:

Разработаны и более сложные эволюционные модели. Эмпирические наблюдения свидетельствуют, что некоторые субституции могут происходить
чаще, чем другие. Субституции, в результате которых один пурин замещается другим пурином, называются транзициями, а замены пурина пиримидином или пиримидина пурином называются трансверсиями. Можно было бы ожидать, что трансверсии происходят чаще, чем транзиции, так как только одна из трех возможных субституций для какого-либо нуклеотида является транзицией. Тем не менее, обычно происходит обратное: транзиции, как правило, происходят чаще, чем трансверсии. Это в частности характерно для митохондриальной ДНК.
Другой причиной того, что некоторые субституции нуклеотидов происходят чаще, чем другие, является неравное соотношение оснований. Например, митохондриальная ДНК насекомых более богата аденином и тимином по сравнению с позвоночными. Если некоторые основания более распространены, можно ожидать, что некоторые субституции происходят чаще, чем другие. Например, если последовательность содержит очень немного гуанина, маловероятно, что будут происходить субституции этого нуклеотида.
Модели различаются тем, что в одних определенный параметр или параметры (например, соотношение оснований, скорости субституции) остаются фиксированными и варьируют в других. Существуют десятки эволюционных моделей. Ниже мы приведем наиболее известные из них.
Уже упомянутая Модель Джукса - Кантора (JC) характеризуется тем, что частоты оснований одинаковы: π A = π C = π G = π T , трансверсии и транзиции имеют одинаковые скорости α=β, и все субституции одинаково вероятны.
Двупараметрическая модель Кимуры (K2P) предполагает равные частоты оснований π A =π C =π G =π T , а трансверсии и транзиции имеют разные скорости α≠β.
Модель Фельзенштейна (F81) предполагает, что частоты оснований разные π A ≠π C ≠π G ≠π T , а скорости субституции одинаковы α=β.
Общая обратимая модель (REV) предполагает различные частоты оснований π A ≠π C ≠π G ≠π T , а все шесть пар субституций имеют различные скорости.
Упомянутые выше модели подразумевают, что скорости субституции одинаковы во всех сайтах. Однако в модели можно учесть и различия скоростей субституции в разных сайтах. Значения частот оснований и скоростей субституции можно как назначить априорно, так и получить эти значения из данных с помощью специальных программ, например PAUP.
Байесовский анализ
Метод максимального правдоподобия оценивает вероятность филогенетических моделей после того, как они созданы на основе имеющихся данных. Однако знание общих закономерностей эволюции данной группы позволяет создать серию наиболее вероятных моделей филогенеза без привлечения основных данных (например, нуклеотидных последовательностей). После того, как эти данные получены, появляется возможность оценить соответствие между ними и заранее построенными моделями, и пересмотреть вероятность этих исходных моделей. Метод, который позволяет это осуществить именуется байесовским анализом , и является новейшим из методов изучения филогении (см. подробный обзор: Huelsenbeck et al. , 2001).
Согласно стандартной терминологии, первоначальные вероятности принято называть априорными вероятностями (так как они принимаются прежде, чем получены данные) а пересмотренные вероятности – апостериорными (так как они вычисляются после получения данных).
Математической основой байесовского анализа является теорема Байеса, в которой априорная вероятность дерева Pr[Tree ] и правдоподобие Pr[Data|Tree ] используются, чтобы вычислить апостериорную вероятность дерева Pr[Tree|Data ]:

Апостериорная вероятность дерева может рассматриваться как вероятность того, что это дерево отражает истинный ход эволюции. Дерево с самой высокой апостериорной вероятностью выбирается в качестве наиболее вероятной модели филогенеза. Распределение апостериорных вероятностей деревьев вычисляется с использованием методов компьютерного моделирования.
Метод максимального правдоподобия и байесовский анализ нуждаются в эволюционных моделях, описывающих изменения признаков. Создание математических моделей морфологической эволюции в настоящее время не представляется возможным. По этой причине статистические методы филогенетического анализа применяются только для молекулярных данных.
Кроме метода моментов, который изложен в предыдущем параграфе, существуют и другие методы точечной оценки неизвестных параметров распределения. К ним относится метод наибольшего правдоподобия, предложенный Р. Фишером.
А. Дискретные случайные величины. Пусть X - дискретная случайная величина, которая в результате n испытаний приняла значения х 1 , х 2 , ..., х п . Допустим, что вид закона распределения величины X задан, но неизвестен параметр θ , которым определяется этот закон. Требуется найти его точечную оценку.
Обозначим вероятность того, что в результате испытания величина X примет значение х i (i = 1 , 2, . . . , n ), через p (х i ; θ ).
Функцией правдоподобия дискретной случайной вели чины X называют функцию аргумента θ :
L (х 1 , х 2 , ..., х п ; θ ) = p (х 1 ; θ ) р (х 2 ; θ ) . . . p (х n ; θ ),
где х 1 , х 2 , ..., х п - фиксированные числа.
В качестве точечной оценки параметра θ принимают такое его значение θ * = θ * (х 1 , х 2 , ..., х п ), при котором функция правдоподобия достигает максимума. Оценку θ * называют оценкой наибольшего правдоподобия.
Функции L и ln L достигают максимума при одном и том же значении θ , поэтому вместо отыскания максимума функции L ищут (что удобнее) максимум функции ln L .
Логарифмической функцией правдоподобия называют функцию ln L . Как известно, точку максимума функции ln L аргумента θ можно искать, например, так:
3) найти вторую производную ; если вторая производная приθ = θ * отрицательна, то θ * - точка максимума.
Найденную точку максимума θ * принимают в качестве оценки наибольшего правдоподобия параметра θ .
Метод наибольшего правдоподобия имеет ряд достоинств: оценки наибольшего правдоподобия, вообще говоря, состоятельны (но они могут быть смещенными), распределены асимптотически нормально (при больших значениях n приближенно нормальны) и имеют наименьшую дисперсию по сравнению с другими асимптотически нормальными оценками; если для оцениваемого параметра θ существует эффективная оценка θ *, то уравнение правдоподобия имеет единственное решение θ *; этот метод наиболее полно использует данные выборки об оцениваемом параметре, поэтому он особенно полезен в случае малых выборок.
Недостаток метода состоит в том, что он часто требует сложных вычислений.
Замечание 1. Функция правдоподобия - функция от аргумента θ ; оценка наибольшего правдоподобия - функция от независимых аргументов х 1 , х 2 , ..., х п .
Замечание 2. Оценка наибольшего правдоподобия не всегда совпадает с оценкой, найденной методом моментов.
Пример 1. λ распределения Пуассона
где m - число произведенных испытаний; x i - число появлений события в i -м (i =1, 2, ..., n ) опыте (опыт состоит из т испытаний).
Решение. Составим функцию правдоподобия, учитывая, что. θ= λ :
L = p (х 1 ; λ :) p (х 2 ; λ :) . . .p (х n ; λ :),=
![]() .
.
Напишем уравнение правдоподобия, для чего приравняем первую производную нулю:
Найдем критическую точку, для чего решим полученное уравнение относительно λ:
Найдем вторую производную по λ:
Легко видеть, что при λ = вторая производная отрицательна; следовательно,λ = - точка максимума и, значит, в качестве оценки наибольшого правдоподобия параметра λ распределения Пуассона надо принять выборочную среднюю λ* = .
Пример 2. Найти методом наибольшего правдоподобия оценку параметра p биномиального распределения
если в n 1 независимых испытаниях событие А появилось х 1 = m 1 раз и в п 2 независимых испытаниях событие А появилось х 2 = т 2 раз.
Решение. Составим функцию правдоподобия, учитывая, что θ = p :
Найдем логарифмическую функцию правдоподобия:
Найдем первую производную по р:
![]() .
.
![]() .
.
Найдем критическую точку, для чего решим полученное уравнение относительно p :
Найдем вторую производную по p :
![]() .
.
Легко убедиться, что при вторая производная отрицательна; следовательно, - точка максимума и, значит, ее надо принять в качестве оценки наибольшего правдоподобия неизвестной вероятности p биномиального распределения:
Б. Непрерывные случайные величины. Пусть X - непрерывная случайная величина, которая в результате n испытаний приняла значения х 1 , х 2 , ..., x п . Допустим, что вид плотности распределения f (x ) задан, но не известен параметр θ , которым определяется эта функция.
Функцией правдоподобия непрерывной случайной вели чины X называют функцию аргумента θ :
L (х 1 , х 2 , ..., х п ; θ ) = f (х 1 ; θ ) f (х 2 ; θ ) . . . f (x n ; θ ),
где х 1 , х 2 , ..., x п - фиксированные числа.
Оценку наибольшего правдоподобия неизвестного параметра распределения непрерывной случайной величины ищут так же, как в случае дискретной величины.
Пример 3. Найти методом наибольшего правдоподобия оценку параметра λ, показательного распределения
(0< х < ∞),
если в результате n испытаний случайная величина X , распределенная по показательному закону, приняла значения х 1 , х 2 , ..., х п .
Решение. Составим функцию правдоподобия, учитывая, что θ= λ:
L = f (х 1 ; λ ) f (х 2 ; λ ) . . . f (х n ; λ ) =.
Найдем логарифмическую функцию правдоподобия:
Найдем первую производную по λ:
Напишем уравнение правдоподобия, для чего приравняем первую производную нулю:
Найдем критическую точку, для чего решим полученное уравнение относительно λ:
Найдем вторую производную по λ:
Легко видеть, что при λ = 1/ вторая производная отрицательна; следовательно, λ = 1/- точка максимума и, значит, в качестве оценки наибольшего правдоподобия параметра λ показательного распределения надо принять величину, обратную выборочной средней:λ *= 1/.
Замечание. Если плотность распределения f (х ) непрерывной случайной величины X определяется двумя неизвестными параметрами θ 1 и θ 2 , то функция правдоподобия является функцией двух независимых аргументов θ 1 и θ 2:
L = f (х 1 ; θ 1 , θ 2) f (х 2 ; θ 1 , θ 2) . . . f (х n ; θ 1 , θ 2),
где х 1 , х 2 , ..., х п - наблюдавшиеся значения X . Далее находят логарифмическую функцию правдоподобия и для отыскания ее максимума составляют и решают систему
Пример 4. Найти методом наибольшего правдоподобия оценки параметров а и σ нормального распределения
если в результате n испытаний величина X приняла значения х 1 , х 2 , ..., х п .
Решение. Составим функцию правдоподобия, учитывая, что θ 1 =a и θ 2 =σ
![]() .
.
Найдем логарифмическую функцию правдоподобия:
![]() .
.
Найдем частные производные по а и по σ:
Приравняв частные производные нулю и решив полученную систему двух уравнений относительно а и σ 2 , получим:
Итак, искомые оценки наибольшего правдоподобия: а * = ;σ*= . Заметим, что первая оценка несмещенная, а вторая смещенная.