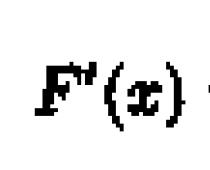5.1. Che cos'è l'analisi della varianza?
L'analisi della varianza è stata sviluppata negli anni '20 dal matematico e genetista inglese Ronald Fisher. Secondo un sondaggio tra gli scienziati, che ha scoperto chi ha maggiormente influenzato la biologia del 20 ° secolo, è stato Sir Fisher a vincere il campionato (per i suoi servizi è stato insignito del cavalierato - uno dei più alti riconoscimenti in Gran Bretagna); sotto questo aspetto, Fisher è paragonabile a Charles Darwin, che ha avuto la maggiore influenza sulla biologia nel 19° secolo.
L'analisi della dispersione (Analis of variance) è ora un ramo separato della statistica. Si basa sul fatto scoperto da Fisher che la misura della variabilità della grandezza in studio può essere scomposta in parti corrispondenti ai fattori che influenzano tale grandezza e deviazioni casuali.
Per comprendere l'essenza dell'analisi della varianza, eseguiremo lo stesso tipo di calcoli due volte: "manualmente" (con una calcolatrice) e utilizzando il programma Statistica. Per semplificare il nostro compito, non lavoreremo con i risultati di una descrizione reale della diversità delle rane verdi, ma con un esempio fittizio che riguarda il confronto tra donne e uomini nell'uomo. Considera la diversità di altezza di 12 adulti: 7 donne e 5 uomini.
Tabella 5.1.1. Esempio ANOVA unidirezionale: dati di sesso e altezza per 12 persone
Eseguiamo un'analisi della varianza unidirezionale: confrontiamo se uomini e donne differiscono in modo statisticamente significativo o meno nel gruppo caratterizzato in termini di altezza.
5.2. Test per la distribuzione normale
Un ulteriore ragionamento si basa sul fatto che la distribuzione nel campione considerato è normale o prossima alla normalità. Se la distribuzione è lontana dalla normalità, la varianza (varianza) non è una misura adeguata della sua variabilità. Tuttavia, l'analisi della varianza è relativamente resistente alle deviazioni della distribuzione dalla normalità.
La verifica della normalità di questi dati può essere eseguita in due modi diversi. Primo: Statistiche / Statistiche di base/Tabelle / Statistiche descrittive / Scheda Normalità. Nella scheda Normalità puoi scegliere quali test di distribuzione normale utilizzare. Quando si fa clic sul pulsante Tabelle di frequenza, verrà visualizzata la tabella di frequenza e i pulsanti Istogrammi: un istogramma. La tabella e il grafico a barre mostreranno i risultati dei vari test.
Il secondo metodo è associato all'uso delle possibilità appropriate durante la costruzione degli istogrammi. Nella finestra di dialogo di costruzione dell'istogramma (Grafs / Histograms...), selezionare la scheda Avanzate. Nella sua parte inferiore è presente un blocco Statistiche. Nota su di esso Shapiro-Wilk t est e test di Kolmogorov-Smirnov, come mostrato nella figura.
Riso. 5.2.1. Test statistici per la distribuzione normale nella finestra di dialogo di costruzione dell'istogramma
Come si può vedere dall'istogramma, la distribuzione della crescita nel nostro campione differisce da quella normale (al centro - "fallimento").

Riso. 5.2.2. Istogramma tracciato con i parametri specificati nella figura precedente
La terza riga nel titolo del grafico indica i parametri della distribuzione normale, che è la più vicina alla distribuzione osservata. La media generale è 173, la deviazione standard generale è 10,4. L'inserto in fondo al grafico mostra i risultati dei test di normalità. D è il test di Kolmogorov-Smirnov e SW-W è il test di Shapiro-Wilk. Come si può notare, per tutti i test utilizzati, le differenze nella distribuzione della crescita rispetto alla distribuzione normale sono risultate statisticamente non significative ( p in tutti i casi maggiore di 0,05).
Quindi, formalmente parlando, i test di distribuzione normale non ci hanno “proibito” di utilizzare un metodo parametrico basato sull'assunzione di una distribuzione normale. Come già accennato, l'analisi della varianza è relativamente resistente alle deviazioni dalla normalità, quindi la usiamo ancora.
5.3. ANOVA unidirezionale: calcoli manuali
Per caratterizzare la variabilità dell'altezza delle persone nell'esempio sopra, calcoliamo la somma delle deviazioni al quadrato (in inglese è indicato come SS
, Somma dei quadrati o ) valori individuali dalla media:  . Il valore medio per l'altezza nell'esempio sopra è 173 centimetri. Basato su questo,
. Il valore medio per l'altezza nell'esempio sopra è 173 centimetri. Basato su questo,
SS = (186–173) 2 + (169–173) 2 + (166–173) 2 + (188–173) 2 + (172–173) 2 + (179–173) 2 + (165–173) 2 + (174–173) 2 + (163–173) 2 + (162–173) 2 + (162–173) 2 + (190–173) 2 ;
SS = 132 + 42 + 72 + 152 + 12 + 62 + 82 + 12 + 102 + 112 + 112 + 172;
SS = 169 + 16 + 49 + 225 + 1 + 36 + 64 + 1 + 100 + 121 + 121 + 289 = 1192.
Il valore risultante (1192) è una misura della variabilità dell'intero set di dati. Tuttavia, sono costituiti da due gruppi, per ciascuno dei quali è possibile allocare la propria media. Nei dati forniti, l'altezza media delle donne è di 168 cm e gli uomini di 180 cm.
Calcola la somma delle deviazioni al quadrato per le donne:
SS f = (169–168) 2 + (166–168) 2 + (172–168) 2 + (179–168) 2 + (163–168) 2 + (162–168) 2 ;
SS f = 12 + 22 + 42 + 112 + 32 + 52 + 62 = 1 + 4 + 16 + 121 + 9 + 25 + 36 = 212.
Calcoliamo anche la somma delle deviazioni al quadrato per gli uomini:
SS m = (186–180) 2 + (188–180) 2 + (174–180) 2 + (162–180) 2 + (190–180) 2 ;
SS m = 62 + 82 + 62 + 182 + 102 = 36 + 64 + 36 + 324 + 100 = 560.
Da cosa dipende il valore in esame secondo la logica dell'analisi della varianza?
Due quantità calcolate, SS f e SS m , caratterizzano la varianza intragruppo, che nell'analisi della varianza viene solitamente chiamata "errore". L'origine di questo nome è legata alla logica seguente.
Cosa determina l'altezza di una persona in questo esempio? Innanzitutto dall'altezza media delle persone in generale, indipendentemente dal sesso. In secondo luogo, dal pavimento. Se le persone di un sesso (maschio) sono più alte dell'altro (femmina), questo può essere rappresentato come un'aggiunta alla media "universale" di un certo valore, l'effetto del sesso. Infine, le persone dello stesso sesso differiscono in altezza a causa delle differenze individuali. All'interno di un modello che descrive l'altezza come la somma della media umana più un adattamento del sesso, le differenze individuali sono inspiegabili e possono essere viste come un "errore".
Quindi, secondo la logica dell'analisi della varianza, il valore in esame è determinato come segue: ![]() , dove xij
- i-esimo valore della grandezza studiata al j-esimo valore del fattore studiato; - media generale; Fj
- l'influenza del j-esimo valore del fattore studiato; - “errore”, il contributo dell'individualità dell'oggetto a cui si riferisce il valorexij
.
, dove xij
- i-esimo valore della grandezza studiata al j-esimo valore del fattore studiato; - media generale; Fj
- l'influenza del j-esimo valore del fattore studiato; - “errore”, il contributo dell'individualità dell'oggetto a cui si riferisce il valorexij
.
Somma intergruppo di quadrati
Così, SS errori = SS f + SS m = 212 + 560 = 772. Con questo valore abbiamo descritto la variabilità intragruppo (separando i gruppi per sesso). Ma c'è anche una seconda parte della variabilità - intergruppo, che chiameremoEffetto SS (perché stiamo parlando dell'effetto della divisione dell'insieme di oggetti in esame in donne e uomini).
La media di ciascun gruppo differisce dalla media complessiva. Quando si calcola il contributo di questa differenza alla misura complessiva della variabilità, dobbiamo moltiplicare la differenza tra il gruppo e la media totale per il numero di oggetti in ciascun gruppo.
Effetto SS = = 7x(168-173) 2 + 5x(180-173) 2 = 7x52 + 5x72 = 7x25 + 5x49 = 175 + 245 = 420.
Qui si manifestava il principio della costanza della somma dei quadrati, scoperto da Fisher: SS = effetto SS + errori SS , cioè. per questo esempio, 1192 = 440 + 722.
Piazze di mezzo
Confrontando nel nostro esempio le somme dei quadrati intergruppo e intragruppo, possiamo vedere che il primo è associato alla variazione dei due gruppi e il secondo - 12 valori in 2 gruppi. Numero di gradi di libertà ( df ) per alcuni parametri può essere definito come la differenza tra il numero di oggetti nel gruppo e il numero di dipendenze (equazioni) che collegano questi valori.
Nel nostro esempio effetto df = 2–1 = 1, un errori df = 12–2 = 10.
Possiamo dividere la somma dei quadrati per il numero dei loro gradi di libertà per ottenere i quadrati medi ( SM , Mezzi dei quadrati). Fatto ciò, possiamo stabilirlo SM - nient'altro che varianze ("dispersioni", risultato della divisione della somma dei quadrati per il numero dei gradi di libertà). Dopo questa scoperta, possiamo capire la struttura della tabella ANOVA. Per il nostro esempio, sarà simile a questo.
|
Effetto |
|||||
|
Errore |
Effetto SM e Errori MS sono stime degli scostamenti infragruppo e infragruppo e, pertanto, possono essere confrontati secondo il criterioF (Criterio di Snedecor, dal nome Fischer), pensato per confrontare le varianti. Questo criterio è semplicemente il quoziente di divisione della varianza maggiore per quella minore. Nel nostro caso, questo è 420 / 77,2 = 5,440.
Determinazione della significatività statistica del test di Fisher secondo le tabelle
Se dovessimo determinare manualmente la significatività statistica dell'effetto, utilizzando le tabelle, dovremmo confrontare il valore del criterio ottenuto F con critico, corrispondente a un certo livello di significatività statistica per determinati gradi di libertà.

Riso. 5.3.1. Frammento di tabella con valori critici del criterio F
Come si vede, per il livello di significatività statistica p=0,05, il valore critico del criterioF è 4,96. Ciò significa che nel nostro esempio, l'effetto del sesso studiato è stato registrato con un livello di significatività statistica di 0,05.
Il risultato ottenuto può essere interpretato come segue. La probabilità dell'ipotesi nulla, secondo la quale l'altezza media di donne e uomini è la stessa, e la differenza registrata nella loro altezza è dovuta alla casualità nella formazione dei campioni, è inferiore al 5%. Ciò significa che dobbiamo scegliere l'ipotesi alternativa che l'altezza media di donne e uomini sia diversa.
5.4. Analisi unidirezionale della varianza ( ANOVA) nel pacchetto Statistica
Nei casi in cui i calcoli non vengano effettuati manualmente, ma con l'ausilio di appositi programmi (ad esempio il pacchetto Statistica), il valore p determinato automaticamente. Si può notare che è leggermente superiore al valore critico.
Per analizzare l'esempio in discussione utilizzando la versione più semplice dell'analisi della varianza, è necessario eseguire la procedura Statistica / ANOVA per il file con i dati corrispondenti e selezionare l'opzione ANOVA unidirezionale (ANOVA unidirezionale) nella Tipo di finestra di analisi e l'opzione della finestra di dialogo Specifiche rapide nella finestra del metodo di specifica.

Riso. 5.4.1. Finestra di dialogo Generale ANOVA/MANOVA (ANOVA)
Nella finestra di dialogo veloce che si apre, nel campo Variabili, è necessario specificare quelle colonne che contengono i dati di cui stiamo studiando la variabilità (Elenco variabili dipendenti; nel nostro caso, la colonna Crescita), nonché una colonna contenente i valori che suddividono il valore studiato in gruppi (Predittore categoriale (fattore); nel nostro caso, la colonna Sesso). In questa versione dell'analisi, a differenza dell'analisi multivariata, può essere considerato un solo fattore.

Riso. 5.4.2. Finestra di dialogo ANOVA unidirezionale (analisi della varianza unidirezionale)
Nella finestra Codici fattore, è necessario specificare quei valori del fattore in considerazione che devono essere elaborati durante questa analisi. Tutti i valori disponibili possono essere visualizzati utilizzando il pulsante Zoom; se, come nel nostro esempio, devi considerare tutti i valori dei fattori (e per il genere nel nostro esempio ce ne sono solo due), puoi cliccare sul pulsante Tutti. Una volta impostate le colonne di elaborazione e i codici fattore, è possibile fare clic sul pulsante OK e passare alla finestra di analisi rapida per i risultati: Risultati ANOVA 1, nella scheda Rapida.

Riso. 5.4.3. La scheda rapida della finestra dei risultati di ANOVA
Il pulsante Tutti gli effetti/Grafici ti consente di vedere come si confrontano le medie dei due gruppi. Sopra il grafico è indicato il numero di gradi di libertà, nonché i valori di F e p per il fattore in esame.

Riso. 5.4.4. Visualizzazione grafica dei risultati dell'analisi della varianza
Il pulsante Tutti gli effetti permette di ottenere una tabella ANOVA simile a quella sopra descritta (con alcune differenze significative).

Riso. 5.4.5. Tabella con i risultati dell'analisi della varianza (confrontare con una tabella simile ottenuta "manualmente")
La riga inferiore della tabella mostra la somma dei quadrati, il numero di gradi di libertà e i quadrati medi per l'errore (variabilità all'interno del gruppo). Sulla riga sopra - indicatori simili per il fattore studiato (in questo caso, il segno del sesso), nonché il criterio F (il rapporto tra i quadrati medi dell'effetto ei quadrati medi dell'errore) e il suo livello di significatività statistica. Il fatto che l'effetto del fattore in esame sia risultato statisticamente significativo è evidenziato dall'evidenziazione rossa.
E la prima riga mostra i dati sull'indicatore "Intercetta". Questo la riga della tabella è un mistero per gli utenti che si uniscono al pacchetto Statistica nella sua sesta versione o successiva. Il valore Intercetta è probabilmente correlato all'espansione della somma dei quadrati di tutti i valori dei dati (es. 1862 + 1692 … = 360340). Il valore del criterio F indicato per esso si ottiene dividendo Errore MS Intercetta /MS = 353220 / 77.2 = 4575.389 e dà naturalmente un valore molto basso p . È interessante notare che in Statistica-5 questo valore non è stato calcolato affatto, ei manuali per l'utilizzo delle versioni successive del pacchetto non commentano in alcun modo la sua introduzione. Probabilmente la cosa migliore che un biologo di Statistica-6 e successivi può fare è semplicemente ignorare la riga Intercept nella tabella ANOVA.
5.5. ANOVA e criteri di Student e Fisher: quale è meglio?
Come puoi vedere, i dati che abbiamo confrontato utilizzando l'analisi della varianza unidirezionale, potremmo anche esaminarli utilizzando i test di Student e Fisher. Confrontiamo questi due metodi. Per fare ciò, calcoliamo la differenza di altezza di uomini e donne utilizzando questi criteri. Per fare ciò, dovremo seguire il percorso Statistica / Statistica di base / t-test, indipendente, per gruppi. Naturalmente, la variabile Dipendente è la variabile Crescita e la variabile Raggruppamento è la variabile Sesso.

Riso. 5.5.1. Confronto dei dati elaborati mediante ANOVA, secondo i criteri di Student e Fisher
Come puoi vedere, il risultato è lo stesso di quando si utilizza ANOVA. p = 0,041874 in entrambi i casi, come mostrato in fig. 5.4.5 e mostrato in Fig. 5.5.2 (guarda tu stesso!).

Riso. 5.5.2. I risultati dell'analisi (interpretazione dettagliata della tabella dei risultati - nel paragrafo sul criterio dello studente)
È importante sottolineare che sebbene il criterio F da un punto di vista matematico nell'analisi in esame secondo i criteri di Student e Fisher sia lo stesso dell'ANOVA (ed esprima il rapporto di varianza), il suo significato nei risultati della l'analisi rappresentata dal tavolo finale è completamente diversa. Quando si confrontano secondo i criteri di Student e Fisher, il confronto dei valori medi dei campioni viene effettuato secondo il criterio di Student e il confronto della loro variabilità viene effettuato secondo il criterio di Fisher. Nei risultati dell'analisi, non viene visualizzata la varianza stessa, ma la sua radice quadrata, la deviazione standard.
Al contrario, in ANOVA, il test di Fisher viene utilizzato per confrontare le medie di diversi campioni (come abbiamo discusso, ciò viene fatto dividendo la somma dei quadrati in parti e confrontando la somma media dei quadrati corrispondenti alla variabilità inter- e intra-gruppo) .
Tuttavia, la differenza di cui sopra riguarda la presentazione dei risultati di uno studio statistico piuttosto che la sua essenza. Come sottolinea Glantz (1999, p. 99), ad esempio, il confronto di gruppi mediante il test di Student può essere considerato un caso speciale di analisi della varianza per due campioni.
Quindi, il confronto dei campioni secondo i test di Student e Fisher ha un importante vantaggio rispetto all'analisi della varianza: può confrontare i campioni in termini di variabilità. Ma i vantaggi di ANOVA sono ancora significativi. Tra questi, ad esempio, c'è la possibilità di confronto simultaneo di più campioni.
Nella pratica dei medici durante la conduzione di ricerche biomediche, sociologiche e sperimentali, diventa necessario stabilire l'influenza dei fattori sui risultati dello studio dello stato di salute della popolazione, quando si valuta l'attività professionale e l'efficacia delle innovazioni.
Esistono numerosi metodi statistici che consentono di determinare la forza, la direzione, i modelli di influenza dei fattori sul risultato nella popolazione generale o campionaria (calcolo del criterio I, analisi di correlazione, regressione, Χ 2 - (criterio dell'accordo di Pearson, L'analisi della varianza è stata sviluppata e proposta dallo scienziato, matematico e genetista inglese Ronald Fisher negli anni '20.
L'analisi della varianza è più spesso utilizzata negli studi scientifici e pratici sulla salute pubblica e sull'assistenza sanitaria per studiare l'influenza di uno o più fattori sul tratto risultante. Si basa sul principio di "riflettere la diversità dei valori del(i) fattore(i) sulla diversità dei valori dell'attributo risultante" e stabilisce la forza dell'influenza del(i) fattore(i) nel popolazioni campione.
L'essenza del metodo di analisi della varianza è misurare le varianze individuali (totali, fattoriali, residue) e determinare ulteriormente la forza (quota) dell'influenza dei fattori studiati (valutazione del ruolo di ciascuno dei fattori o della loro influenza combinata ) sugli attributi risultanti.
Analisi della varianza- si tratta di un metodo statistico per valutare la relazione tra fattore e caratteristiche prestazionali in diversi gruppi, selezionati casualmente, in base alla determinazione delle differenze (diversità) nei valori delle caratteristiche. L'analisi della varianza si basa sull'analisi delle deviazioni di tutte le unità della popolazione studiata dalla media aritmetica. Come misura delle deviazioni, viene presa la dispersione (B), il quadrato medio delle deviazioni. Le deviazioni causate dall'influenza di un attributo fattore (fattore) vengono confrontate con l'entità delle deviazioni causate da circostanze casuali. Se le deviazioni causate dall'attributo fattore sono più significative delle deviazioni casuali, si considera che il fattore abbia un impatto significativo sull'attributo risultante.
Per calcolare la varianza del valore di deviazione di ciascuna opzione (ciascun valore numerico registrato dell'attributo) dalla media aritmetica, al quadrato. Questo eliminerà i segni negativi. Quindi queste deviazioni (differenze) vengono sommate e divise per il numero di osservazioni, ad es. media delle deviazioni. Si ottengono così i valori di dispersione.
Un importante valore metodologico per l'applicazione dell'analisi della varianza è la corretta formazione del campione. A seconda dell'obiettivo e degli obiettivi, i gruppi selettivi possono essere formati casualmente indipendentemente l'uno dall'altro (gruppi di controllo e sperimentali per studiare alcuni indicatori, ad esempio l'effetto dell'ipertensione sullo sviluppo dell'ictus). Tali campioni sono chiamati indipendenti.
Spesso, i risultati dell'esposizione a fattori vengono studiati nello stesso gruppo campione (ad esempio negli stessi pazienti) prima e dopo l'esposizione (trattamento, prevenzione, misure riabilitative), tali campioni sono chiamati dipendenti.
L'analisi della varianza, in cui viene verificata l'influenza di un fattore, è chiamata analisi a un fattore (analisi univariata). Quando si studia l'influenza di più di un fattore, viene utilizzata l'analisi multivariata della varianza (analisi multivariata).
I segni fattoriali sono quei segni che influenzano il fenomeno in esame.
I segni efficaci sono quei segni che cambiano sotto l'influenza dei segni fattoriali.
Sia le caratteristiche qualitative (sesso, professione) che quelle quantitative (numero di iniezioni, pazienti in reparto, numero di giorni di letto) possono essere utilizzate per condurre l'analisi della varianza.
Metodi di analisi della dispersione:
- Metodo secondo Fisher (Fisher) - criterio F (valori di F, vedere Appendice n. 1);
Il metodo viene utilizzato nell'analisi unidirezionale della varianza, quando la varianza totale di tutti i valori osservati viene scomposta nella varianza all'interno dei singoli gruppi e nella varianza tra i gruppi. - Metodo del "modello lineare generale".
Si basa sull'analisi di correlazione o regressione utilizzata nell'analisi multivariata.
Di solito, nella ricerca biomedica vengono utilizzati solo complessi di dispersione a un fattore e massimo due fattori. I complessi multifattoriali possono essere studiati analizzando in sequenza i complessi a uno o due fattori isolati dall'intera popolazione osservata.
Condizioni per l'uso dell'analisi della varianza:
- Il compito dello studio è determinare la forza dell'influenza di uno (fino a 3) fattori sul risultato o determinare la forza dell'influenza combinata di vari fattori (sesso ed età, attività fisica e alimentazione, ecc.).
- I fattori studiati dovrebbero essere indipendenti (non correlati) tra loro. Ad esempio, non si può studiare l'effetto combinato dell'esperienza lavorativa e dell'età, dell'altezza e del peso dei bambini, ecc. sull'incidenza della popolazione.
- La selezione dei gruppi per lo studio viene effettuata in modo casuale (selezione casuale). L'organizzazione di un complesso di dispersione con l'attuazione del principio della selezione casuale delle opzioni è chiamata randomizzazione (tradotta dall'inglese - casuale), ad es. scelto a caso.
- Possono essere utilizzate caratteristiche sia quantitative che qualitative (attributive).
Quando si esegue un'analisi unidirezionale della varianza, si raccomanda (condizione necessaria per l'applicazione):
- La normalità della distribuzione dei gruppi analizzati o la corrispondenza dei gruppi campionari a popolazioni generali con distribuzione normale.
- Indipendenza (non connessione) della distribuzione delle osservazioni in gruppi.
- Presenza di frequenza (ricorrenza) delle osservazioni.
La normalità della distribuzione è determinata dalla curva di Gauss (De Mavour), che può essere descritta dalla funzione y \u003d f (x), poiché è una delle leggi di distribuzione utilizzate per approssimare la descrizione di fenomeni casuali, di natura probabilistica. Oggetto della ricerca biomedica è il fenomeno di natura probabilistica, la distribuzione normale in tali studi è molto comune.
Il principio di applicazione del metodo di analisi della varianza
Per prima cosa viene formulata un'ipotesi nulla, ovvero si presume che i fattori oggetto di studio non abbiano alcun effetto sui valori dell'attributo risultante e le differenze risultanti siano casuali.
Quindi determiniamo qual è la probabilità di ottenere le differenze osservate (o più forti), a condizione che l'ipotesi nulla sia vera.
Se questa probabilità è piccola*, allora rifiutiamo l'ipotesi nulla e concludiamo che i risultati dello studio sono statisticamente significativi. Ciò non significa ancora che l'effetto dei fattori studiati sia stato dimostrato (questo è principalmente una questione di pianificazione della ricerca), ma è comunque improbabile che il risultato sia dovuto al caso.
__________________________________
* La probabilità massima accettabile di rifiutare un'ipotesi nulla vera è chiamata livello di significatività e indicata con α = 0,05.
Quando tutte le condizioni per applicare l'analisi della varianza sono soddisfatte, la scomposizione della varianza totale appare matematicamente così:
D gen. = D fatto + D riposo. ,
D gen. - la varianza totale dei valori osservati (variante), caratterizzata dallo spread della variante dalla media totale. Misura la variazione di un tratto nell'intera popolazione sotto l'influenza di tutti i fattori che hanno causato questa variazione. La diversità complessiva è costituita da intergruppo e intragruppo;
D fact - varianza fattoriale (intergruppo), caratterizzata dalla differenza delle medie in ciascun gruppo e dipende dall'influenza del fattore studiato, per cui ogni gruppo è differenziato. Ad esempio, in gruppi di diversi fattori eziologici del decorso clinico della polmonite, il livello medio del giorno trascorso a letto non è lo stesso: si osserva la diversità tra i gruppi.
D riposo. - varianza residua (intragruppo), che caratterizza la dispersione della variante all'interno dei gruppi. Riflette variazioni casuali, ad es. parte della variazione che si verifica sotto l'influenza di fattori non specificati e non dipende dal tratto, il fattore alla base del raggruppamento. La variazione del tratto in studio dipende dalla forza dell'influenza di alcuni fattori casuali non contabilizzati, sia su fattori organizzati (dati dal ricercatore) che casuali (sconosciuti).
Pertanto, la variazione totale (dispersione) è composta dalla variazione causata da fattori organizzati (data), chiamata variazione fattoriale e fattori non organizzati, cioè variazione residua (casuale, sconosciuta).
L'analisi classica della varianza viene eseguita nei seguenti passaggi:
- Costruzione di un complesso di dispersione.
- Calcolo dei quadrati medi delle deviazioni.
- Calcolo della varianza.
- Confronto tra varianze fattoriali e residue.
- Valutazione dei risultati utilizzando i valori teorici della distribuzione Fisher-Snedekor (Appendice N 1).
ALGORITMO PER EFFETTUARE UN'ANALISI DELL'ANOVANO SECONDO UNA VARIANTE SEMPLIFICATA
L'algoritmo per condurre l'analisi della varianza utilizzando un metodo semplificato consente di ottenere gli stessi risultati, ma i calcoli sono molto più semplici:
io in scena. Costruzione di un complesso di dispersione
La costruzione di un complesso di dispersione significa la costruzione di una tabella in cui sarebbero chiaramente distinti i fattori, il segno effettivo e la selezione delle osservazioni (pazienti) in ciascun gruppo.
Un complesso a un fattore è costituito da più gradazioni di un fattore (A). Le gradazioni sono campioni di diverse popolazioni generali (A1, A2, AZ).
Complesso a due fattori: consiste in diverse gradazioni di due fattori in combinazione tra loro. I fattori eziologici nell'incidenza della polmonite sono gli stessi (A1, A2, A3) in combinazione con diverse forme del decorso clinico della polmonite (H1 - acuto, H2 - cronico).
| Segno di esito (numero di giorni di letto in media) | Fattori eziologici nello sviluppo della polmonite | |||||
| A1 | A2 | A3 | ||||
| H1 | H2 | H1 | H2 | H1 | H2 | |
| M = 14 giorni | ||||||
II stadio. Calcolo della media complessiva (M obsh)
Calcolo della somma delle opzioni per ciascuna gradazione di fattori: Σ Vj = V 1 + V 2 + V 3
Calcolo della somma totale della variante (Σ V totale) su tutte le gradazioni dell'attributo fattore: Σ V totale = Σ Vj 1 + Σ Vj 2 + Σ Vj 3
Calcolo della media del gruppo (M gr.) Segno del fattore: M gr. = Σ Vj / N,
dove N è la somma del numero di osservazioni per tutte le gradazioni della caratteristica del fattore I (Σn per gruppi).
III stadio. Calcolo delle varianze:
Fatte salve tutte le condizioni per l'applicazione dell'analisi della varianza, la formula matematica è la seguente:
D gen. = D fatto + D riposo.
D gen. - varianza totale, caratterizzata dallo scarto della variante (valori osservati) dalla media generale;
D fatto. - la varianza fattoriale (intergruppo) caratterizza lo spread delle medie di gruppo dalla media generale;
D riposo. - varianza residua (intragruppo) caratterizza la dispersione della variante all'interno dei gruppi.
- Calcolo della varianza fattoriale (fatto D): D fatto. = Σh - H
- Il calcolo h viene effettuato secondo la formula: h = (Σ Vj) / N
- Il calcolo di H si effettua secondo la formula: H = (ΣV) 2 / N
- Calcolo della varianza residua: D riposo. = (Σ V) 2 - Σ h
- Calcolo della varianza totale: D gen. = (ΣV) 2 - ΣH
IV stadio. Calcolo dell'indicatore principale della forza di influenza del fattore oggetto di studio L'indicatore della forza di influenza (η 2) di un attributo fattore sul risultato è determinato dalla quota di varianza fattoriale (D fact.) nella varianza totale (D generale), η 2 (questo) - mostra quale proporzione il l'influenza del fattore in esame occupa tra tutti gli altri fattori ed è determinata dalla formula:
V stadio. La determinazione dell'affidabilità dei risultati dello studio con il metodo Fisher viene effettuata secondo la formula:

F - Criterio di Fisher;
Fst. - valore tabulare (vedi Appendice 1).
σ 2 fatto, σ 2 resto. - deviazioni fattoriali e residue (dal lat. de - da, via - strada) - deviazioni dalla linea mediana, determinate dalle formule:

r è il numero di gradazioni dell'attributo factor.
Il confronto del criterio di Fisher (F) con lo standard (tabulare) F viene effettuato secondo le colonne della tabella, tenendo conto dei gradi di libertà:
v 1 \u003d n - 1
v 2 \u003d N - 1
Determinare orizzontalmente v 1 verticalmente - v 2 , alla loro intersezione determinare il valore tabulare F, dove il valore tabulare superiore p ≥ 0,05, e quello inferiore corrisponde a p > 0,01, e confrontare con il criterio calcolato F. Se il valore del calcolato il criterio F uguale o maggiore di quello tabulare, i risultati sono attendibili e H 0 non viene rifiutato.
L'obiettivo:
Nell'impresa di N., il livello degli infortuni è aumentato, in relazione al quale il medico ha condotto uno studio di fattori individuali, tra i quali è stata studiata l'esperienza lavorativa dei lavoratori nei negozi. Sono stati prelevati campioni presso l'impresa N. da 4 negozi con condizioni simili e natura del lavoro. I tassi di infortunio sono calcolati per 100 dipendenti nell'ultimo anno.
Nello studio del fattore esperienza lavorativa sono stati ottenuti i seguenti dati:
Sulla base dei dati dello studio, è stata avanzata un'ipotesi nulla (H 0) sull'effetto dell'esperienza lavorativa sul livello di infortuni dei dipendenti dell'impresa A.
Esercizio
Conferma o confuta l'ipotesi nulla utilizzando l'analisi della varianza unidirezionale:
- determinare la forza dell'influenza;
- valutare l'affidabilità dell'influenza del fattore.
Fasi di applicazione dell'analisi della varianza
determinare l'influenza di un fattore (esperienza lavorativa) sul risultato (tasso di infortunio)

Conclusione. Nel complesso campionario è emerso che l'influenza dell'esperienza lavorativa sul livello degli infortuni è dell'80% sul numero totale degli altri fattori. Per tutte le officine dello stabilimento si può affermare con una probabilità del 99,7% (13,3 > 8,7) che l'esperienza lavorativa influisca sul livello degli infortuni.
Pertanto, l'ipotesi nulla (Н 0) non viene respinta e si considera provato l'effetto dell'esperienza lavorativa sul livello degli infortuni nelle officine dell'impianto A.
Valore F (test Fisher) standard a p ≥ 0,05 (valore superiore) a p ≥ 0,01 (valore inferiore)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
| 6 | 6,0 13,4 | 5,1 10,9 | 4,8 9,8 | 4,5 9,2 | 4,4 8,8 | 4,3 8,5 | 4,2 8,3 | 4,1 8,1 | 4,1 8,0 | 4,1 7,9 | 4,0 7,8 |
| 7 | 5,6 12,3 | 4,7 9,6 | 4,4 8,5 | 4,1 7,9 | 4,0 7,5 | 3,9 7,2 | 3,8 7,0 | 3,7 6,8 | 3,7 6,7 | 3,6 6,6 | 3,6 6,5 |
| 8 | 5,3 11,3 | 4,6 8,7 | 4,1 7,6 | 3,8 7,0 | 3,7 6,6 | 3,6 6,4 | 3,5 6,2 | 3,4 6,0 | 3,4 5,9 | 3,3 5,8 | 3,1 5,7 |
| 9 | 5,1 10,6 | 4,3 8,0 | 3,6 7,0 | 3,6 6,4 | 3,5 6,1 | 3,4 5,8 | 3,3 5,6 | 3,2 5,5 | 3,2 5,4 | 3,1 5,3 | 3,1 5,2 |
| 10 | 5,0 10,0 | 4,1 7,9 | 3,7 6,6 | 3,5 6,0 | 3,3 5,6 | 3,2 5,4 | 3,1 5,2 | 3,1 5,1 | 3,0 5,0 | 2,9 4,5 | 2,9 4,8 |
| 11 | 4,8 9,7 | 4,0 7,2 | 3,6 6,2 | 3,6 5,7 | 3,2 5,3 | 3,1 5,1 | 3,0 4,9 | 3,0 4,7 | 2,9 4,6 | 2,9 4,5 | 2,8 4,5 |
| 12 | 4,8 9,3 | 3,9 6,9 | 3,5 6,0 | 3,3 5,4 | 3,1 5,1 | 3,0 4,7 | 2,9 4,7 | 2,9 4,5 | 2,8 4,4 | 2,8 4,3 | 2,7 4,2 |
| 13 | 4,7 9,1 | 3,8 6,7 | 3,4 5,7 | 3,2 5,2 | 3,0 4,9 | 2,9 4,6 | 2,8 4,4 | 2,8 4,3 | 2,7 4,2 | 2,7 4,1 | 2,6 4,0 |
| 14 | 4,6 8,9 | 3,7 6,5 | 3,3 5,6 | 3,1 5,0 | 3,0 4,7 | 2,9 4,5 | 2,8 4,3 | 2,7 4,1 | 2,7 4,0 | 2,6 3,9 | 2,6 3,9 |
| 15 | 4,5 8,7 | 3,7 6,4 | 3,3 5,4 | 3,1 4,9 | 2,9 4,6 | 2,8 4,3 | 2,7 4,1 | 2,6 4,0 | 2,6 3,9 | 2,5 3,8 | 2,5 3,7 |
| 16 | 4,5 8,5 | 3,6 6,2 | 3,2 5,3 | 3,0 4,8 | 2,9 4,4 | 2,7 4,2 | 2,7 4,0 | 2,6 3,9 | 2,5 3,8 | 2,5 3,7 | 2,5 3,6 |
| 17 | 4,5 8,4 | 3,6 6,1 | 3,2 5,2 | 3,0 4,7 | 2,8 4,3 | 2,7 4,1 | 2,6 3,9 | 2,6 3,8 | 2,5 3,8 | 2,5 3,6 | 2,4 3,5 |
| 18 | 4,4 8,3 | 3,5 6,0 | 3,2 5,1 | 2,9 4,6 | 2,8 4,2 | 2,7 4,0 | 2,6 3,8 | 2,5 3,7 | 2,7 3,6 | 2,4 3,6 | 3,4 3,5 |
| 19 | 4,4 8,2 | 3,5 5,9 | 3,1 5,0 | 2,9 4,5 | 2,7 4,2 | 2,6 3,9 | 2,5 3,8 | 2,5 3,6 | 2,4 3,5 | 2,4 3,4 | 2,3 3,4 |
| 20 | 4,3 8,1 | 3,5 5,8 | 3,1 4,9 | 2,9 4,4 | 2,7 4,1 | 2,6 3,9 | 2,5 3,7 | 2,4 3,6 | 2,4 3,4 | 2,3 3,4 | 2,3 3,3 |
- Vlasov V.V. Epidemiologia. - M.: GEOTAR-MED, 2004. 464 p.
- Arkhipova GL, Lavrova IG, Troshina I.M. Alcuni metodi moderni di analisi statistica in medicina. - M.: Metrosnab, 1971. - 75 p.
- Zaitsev VM, Liflyandsky VG, Marinkin VI Statistica medica applicata. - San Pietroburgo: LLC "FOLIANT Publishing House", 2003. - 432 p.
- Platonov A.E. L'analisi statistica in medicina e biologia: compiti, terminologia, logica, metodi informatici. - M.: Casa editrice dell'Accademia Russa di Scienze Mediche, 2000. - 52 p.
- Plokhinsky NA Biometrica. - Casa editrice della filiale siberiana dell'Accademia delle scienze dell'URSS Novosibirsk. - 1961. - 364 pag.
A cosa serve l'analisi della varianza? Lo scopo dell'analisi della varianza è studiare la presenza o l'assenza di un'influenza significativa di qualsiasi fattore qualitativo o quantitativo sui cambiamenti nel tratto efficace studiato. A tal fine, il fattore, presumibilmente avente o meno un'influenza notevole, viene suddiviso in classi di gradazione (in altre parole, gruppi) e si scopre se l'influenza del fattore è la stessa esaminando la significatività tra le medie in gli insiemi di dati corrispondenti alle gradazioni del fattore. Esempi: viene studiata la dipendenza del profitto di un'impresa dal tipo di materie prime utilizzate (quindi le classi di gradazione sono i tipi di materie prime), la dipendenza del costo di produzione di un'unità di produzione dalle dimensioni dell'impresa divisione (quindi le classi di gradazione sono le caratteristiche della dimensione dell'unità: grande, media, piccola).
Il numero minimo di classi di laurea (gruppi) è due. Le classi di valutazione possono essere qualitative o quantitative.
Perché l'analisi della varianza è chiamata analisi della dispersione? L'analisi della varianza esamina il rapporto di due varianze. La dispersione, come sappiamo, è una misura della dispersione dei dati attorno alla media. Il primo è la varianza spiegata dall'influenza del fattore, che caratterizza la diffusione dei valori tra le gradazioni del fattore (gruppi) attorno alla media di tutti i dati. La seconda è la varianza inspiegabile, che caratterizza la dispersione dei dati all'interno delle gradazioni (gruppi) attorno ai valori medi dei gruppi stessi. La prima dispersione può essere chiamata intergruppo e la seconda - intragruppo. Il rapporto di queste varianze è chiamato rapporto di Fisher effettivo e viene confrontato con il valore critico del rapporto di Fisher. Se il rapporto di Fisher effettivo è maggiore di quello critico, le classi di gradazione media differiscono l'una dall'altra e il fattore in esame influisce in modo significativo sulla modifica dei dati. Se inferiore, le classi di gradazione media non differiscono l'una dall'altra e il fattore non ha un effetto significativo.
Come vengono formulate, accettate e rifiutate le ipotesi nell'analisi della varianza? Nell'analisi della varianza viene determinato il peso specifico dell'impatto totale di uno o più fattori. La significatività dell'influenza del fattore è determinata verificando ipotesi:
- H0 : μ 1 = μ 2 = ... = μ un, dove un- numero di classi di gradazione - tutte le classi di gradazione hanno un valore medio,
- H1 : Non tutto μ io sono uguali - non tutte le classi di gradazione hanno lo stesso valore medio.
Se l'influenza di un fattore non è significativa, anche la differenza tra le classi di gradazione di tale fattore è insignificante e, nel corso dell'analisi della varianza, l'ipotesi nulla H0 non viene rifiutato. Se l'influenza del fattore è significativa, allora l'ipotesi nulla H0 rifiutato: non tutte le classi di gradazione hanno la stessa media, cioè tra le possibili differenze tra classi di gradazione, una o più sono significative.
Alcuni altri concetti di analisi della varianza. Un complesso statistico nell'analisi della dispersione è una tabella di dati empirici. Se in tutte le classi di gradazioni lo stesso numero di opzioni, il complesso statistico è chiamato omogeneo (omogeneo), se il numero di opzioni è diverso - eterogeneo (eterogeneo).
A seconda del numero di fattori stimati, si distingue l'analisi della varianza a un fattore, a due fattori e multifattoriale.
Analisi unidirezionale della varianza: l'essenza del metodo, formule, esempi
L'essenza del metodo, le formule
si basa sul fatto che la somma delle deviazioni al quadrato del complesso statistico può essere suddivisa in componenti:
SS = SS un + SS e,
SS
SSun un somma delle deviazioni al quadrato,
SSeè la somma inspiegabile delle deviazioni al quadrato o la somma delle deviazioni al quadrato dell'errore.
Se attraverso nio indicare il numero di opzioni in ciascuna classe di gradazione (gruppo) e un- il numero totale di gradazioni del fattore (gruppi), quindi - il numero totale di osservazioni e puoi ottenere le seguenti formule:
numero totale di deviazioni al quadrato: ![]() ,
,
spiegato dall'influenza del fattore un somma delle deviazioni al quadrato: ![]() ,
,
somma inspiegabile di deviazioni al quadrato o somma di deviazioni di errore al quadrato: ![]() ,
,
![]() - media totale delle osservazioni,
- media totale delle osservazioni,
(gruppo).
Oltretutto,

dove è la dispersione della gradazione del fattore (gruppo).
Per condurre un'analisi unidirezionale della varianza sui dati di un complesso statistico, è necessario trovare il rapporto di Fisher effettivo, il rapporto della varianza spiegato dall'influenza del fattore (intergruppo) e dalla varianza inspiegabile (intragruppo):
e confrontarlo con il valore critico di Fisher.
Gli scostamenti sono calcolati come segue:
varianza spiegata,
varianza inspiegabile,
vun = un − 1 è il numero di gradi di libertà della dispersione spiegata,
ve= n − un è il numero di gradi di libertà della dispersione inspiegabile,
v = n
Il valore critico del Fisher ratio con determinati valori del livello di significatività e dei gradi di libertà è reperibile nelle tabelle statistiche o calcolato utilizzando la funzione F.OBR di MS Excel (la figura sottostante, per ingrandirla, cliccarci sopra con il tasto sinistro del mouse).

La funzione richiede l'inserimento dei seguenti dati:
Probabilità - livello di significatività α ,
gradi_di_libertà1 - il numero di gradi di libertà della varianza spiegata vun,
gradi_di_libertà2 - numero di gradi di libertà di varianza inspiegabile ve.
Se il valore effettivo del rapporto di Fisher è maggiore del valore critico (), l'ipotesi nulla viene rifiutata con un livello di significatività α . Ciò significa che il fattore influisce in modo significativo sulla modifica dei dati e che i dati dipendono dal fattore con una probabilità P = 1 − α .
Se il valore effettivo del rapporto di Fisher è inferiore al critico (), l'ipotesi nulla non può essere rifiutata con un livello di significatività α . Ciò significa che il fattore non influisce in modo significativo sui dati con la probabilità P = 1 − α .
ANOVA unidirezionale: esempi
Esempio 1È necessario scoprire se il tipo di materie prime utilizzate influisce sul profitto dell'impresa. In sei classi di gradazione (gruppi) del fattore (tipo 1, tipo 2, ecc.), Sono stati raccolti dati sul profitto dalla produzione di 1000 unità di prodotti in milioni di rubli in 4 anni.
| Tipo di materia prima | 2014 | 2015 | 2016 | 2017 |
| 1° | 7,21 | 7,55 | 7,29 | 7,6 |
| 2° | 7,89 | 8,27 | 7,39 | 8,18 |
| 3° | 7,25 | 7,01 | 7,37 | 7,53 |
| 4° | 7,75 | 7,41 | 7,27 | 7,42 |
| 5° | 7,7 | 8,28 | 8,55 | 8,6 |
| 6° | 7,56 | 8,05 | 8,07 | 7,84 |
| Media | Dispersione |
| 7,413 | 0,0367 |
| 7,933 | 0,1571 |
| 7,290 | 0,0480 |
| 7,463 | 0,0414 |
| 8,283 | 0,1706 |
| 7,880 | 0,0563 |
un= 6 e in ogni classe (gruppo) nio = 4 osservazioni. Numero totale di osservazioni n = 24 .
Numeri di gradi di libertà:
vun = un − 1 = 6 − 1 = 5 ,
ve= n − un = 24 − 6 = 18 ,
v = n − 1 = 24 − 1 = 23 .




Calcoliamo le varianze:
![]()
![]() .
.
![]() .
.
Poiché il rapporto di Fisher effettivo è maggiore di quello critico:
con livello di significatività α = 0,05 concludiamo che il profitto dell'impresa, a seconda del tipo di materie prime utilizzate nella produzione, differisce significativamente.
Oppure, ciò che è lo stesso, respingiamo l'ipotesi principale sull'uguaglianza dei mezzi in tutte le classi di gradazione fattoriale (gruppi).
Nell'esempio appena considerato, ogni classe di gradazione fattoriale aveva lo stesso numero di opzioni. Ma, come accennato nella parte introduttiva, il numero di opzioni può essere diverso. E questo non complica in alcun modo la procedura per l'analisi della varianza. Questo è il prossimo esempio.
Esempio 2È necessario scoprire se esiste una dipendenza del costo unitario della produzione dalle dimensioni dell'unità aziendale. Il fattore (valore di suddivisione) è suddiviso in tre classi di gradazione (gruppi): piccolo, medio, grande. Vengono riepilogati i dati corrispondenti a questi gruppi sul costo di produzione di un'unità dello stesso tipo di prodotto per un certo periodo.
| piccolo | media | grande | |
| 48 | 47 | 46 | |
| 50 | 61 | 57 | |
| 63 | 63 | 57 | |
| 72 | 47 | 55 | |
| 43 | 32 | ||
| 59 | 59 | ||
| 58 | |||
| Media | 58,6 | 54,0 | 51,0 |
| Dispersione | 128,25 | 65,00 | 107,60 |
Numero di classi di gradazione dei fattori (gruppi) un= 3 , numero di osservazioni nelle classi (gruppi) n1 = 4 , n2 = 7 , n3 = 6 . Numero totale di osservazioni n = 17 .
Numeri di gradi di libertà:
vun = un − 1 = 2 ,
ve= n − un = 17 − 3 = 14 ,
v = n − 1 = 16 .
Calcoliamo la somma delle deviazioni al quadrato:




Calcoliamo le varianze:
![]() ,
,
![]() .
.
Calcoliamo il rapporto di Fisher effettivo:
![]() .
.
Il valore critico del Fisher ratio:
Poiché il valore effettivo del Fisher ratio è inferiore a quello critico: , concludiamo che la dimensione dell'unità aziendale non ha un impatto significativo sul costo di produzione.
Oppure, che è lo stesso, con una probabilità del 95% accettiamo l'ipotesi principale che il costo medio di produzione di un'unità dello stesso prodotto in piccole, medie e grandi divisioni dell'impresa non differisca in modo significativo.
ANOVA unidirezionale in MS Excel
L'analisi unidirezionale della varianza può essere eseguita utilizzando la procedura MS Excel Analisi unidirezionale della varianza. Lo utilizziamo per analizzare i dati sulla relazione tra il tipo di materie prime utilizzate e il profitto dell'impresa dell'esempio 1.
Servizio/Analisi dei dati e scegli uno strumento di analisi Analisi unidirezionale della varianza.
nella finestra intervallo di input specificare l'area dati (nel nostro caso è $A$2:$E$7). Indichiamo come è raggruppato il fattore - per colonne o per righe (nel nostro caso, per righe). Se la prima colonna contiene i nomi delle classi di fattori, selezionare la casella Etichette nella prima colonna. Nella finestra Alfa indicare il livello di significatività α = 0,05 .



La seconda tabella - Analisi della varianza - contiene i dati sui valori per il fattore tra gruppi e all'interno di gruppi e totali. Questi sono la somma delle deviazioni al quadrato (SS), il numero di gradi di libertà (df) e la dispersione (MS). Nelle ultime tre colonne - il valore effettivo del rapporto di Fisher (F), il livello p (valore P) e il valore critico del rapporto di Fisher (F critico).
| SM | F | valore p | Fcrit |
| 0,58585 | 6,891119 | 0,000936 | 2,77285 |
| 0,085017 | |||
Poiché il valore effettivo del Fisher ratio (6,89) è maggiore del valore critico (2,77), con una probabilità del 95% respingiamo l'ipotesi nulla sull'uguaglianza della produttività media quando si utilizzano tutti i tipi di materie prime, ovvero si concludere che il tipo di materie prime utilizzate incide sulle imprese profit.
Analisi bidirezionale della varianza senza ripetizioni: l'essenza del metodo, formule, esempio
L'analisi della varianza a due vie viene utilizzata per verificare la possibile dipendenza della caratteristica effettiva da due fattori: UN e B. Quindi un- numero di gradazioni del fattore UN e b- numero di gradazioni del fattore B. Nel complesso statistico, la somma dei quadrati dei residui è divisa in tre componenti:
SS = SS un + SS b+ SS e,
![]() è la somma totale delle deviazioni al quadrato,
è la somma totale delle deviazioni al quadrato,
![]() - spiegato dall'influenza del fattore UN somma delle deviazioni al quadrato,
- spiegato dall'influenza del fattore UN somma delle deviazioni al quadrato,
![]() - spiegato dall'influenza del fattore B somma delle deviazioni al quadrato,
- spiegato dall'influenza del fattore B somma delle deviazioni al quadrato,
![]()
![]() - media totale delle osservazioni,
- media totale delle osservazioni,
Media delle osservazioni in ciascuna gradazione del fattore UN ,
B .
UN ,
Dispersione spiegata dall'influenza del fattore B ,
![]()
vun = un − 1 UN ,
vb= b − 1 - il numero di gradi di libertà della dispersione, spiegato dall'influenza del fattore B ,
ve = ( un − 1)(b − 1)
v = ab− 1 - numero totale di gradi di libertà.
Se i fattori sono indipendenti l'uno dall'altro, vengono avanzate due ipotesi nulle e le corrispondenti ipotesi alternative per determinare la significatività dei fattori:
per il fattore UN :
H0 : μ 1A= μ 2A = ... = μ aa,
H1 : Non tutto μ iA sono uguali;
per il fattore B :
H0 : μ 1B= μ 2B=...= μ aB,
H1 : Non tutto μ iB sono uguali.
UN
Per determinare l'influenza di un fattore B, dobbiamo confrontare il rapporto Fisher effettivo con il rapporto Fisher critico .
α P = 1 − α .
α P = 1 − α .
Analisi bidirezionale della varianza senza ripetizioni: un esempio
Esempio 3 Vengono fornite informazioni sul consumo medio di carburante per 100 chilometri in litri, a seconda della cilindrata del motore e del tipo di carburante.
È necessario verificare se il consumo di carburante dipende dalla cilindrata e dal tipo di carburante.
Soluzione. Per il fattore UN numero di classi di gradazione un= 3 , per il fattore B numero di classi di gradazione b = 3 .
Calcoliamo la somma delle deviazioni al quadrato:
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Variazioni rilevanti:
![]() ,
,
![]() ,
,
![]() .
.
UN
![]()
![]() . Poiché il rapporto Fisher effettivo è inferiore a quello critico, con una probabilità del 95% accettiamo l'ipotesi che la cilindrata del motore non influisca sul consumo di carburante. Tuttavia, se scegliamo il livello di significatività α
= 0,1 , quindi il valore effettivo del Fisher ratio e quindi con una probabilità del 95% possiamo accettare che la cilindrata del motore influisca sul consumo di carburante.
. Poiché il rapporto Fisher effettivo è inferiore a quello critico, con una probabilità del 95% accettiamo l'ipotesi che la cilindrata del motore non influisca sul consumo di carburante. Tuttavia, se scegliamo il livello di significatività α
= 0,1 , quindi il valore effettivo del Fisher ratio e quindi con una probabilità del 95% possiamo accettare che la cilindrata del motore influisca sul consumo di carburante.
Rapporto di Fisher effettivo per un fattore B
![]() , il valore critico del Fisher ratio:
, il valore critico del Fisher ratio: ![]() . Poiché il rapporto Fisher effettivo è maggiore del valore critico del rapporto Fisher, assumiamo con una probabilità del 95% che il tipo di carburante influisca sul suo consumo.
. Poiché il rapporto Fisher effettivo è maggiore del valore critico del rapporto Fisher, assumiamo con una probabilità del 95% che il tipo di carburante influisca sul suo consumo.

Analisi bidirezionale della varianza senza ripetizioni in MS Excel
L'analisi della varianza a due vie senza ripetizioni può essere eseguita utilizzando la procedura MS Excel. Lo utilizziamo per analizzare i dati sulla relazione tra il tipo di carburante e il suo consumo dell'esempio 3.
Nel menu di MS Excel, eseguire il comando Servizio/Analisi dei dati e scegli uno strumento di analisi Analisi bidirezionale della varianza senza ripetizioni.
Compiliamo i dati come nel caso dell'ANOVA unidirezionale.

Come risultato della procedura, vengono visualizzate due tabelle. La prima tabella è Totals. Contiene dati su tutte le classi di gradazione dei fattori: numero di osservazioni, valore totale, valore medio e varianza.

La seconda tabella - Analisi della varianza - contiene i dati sulle fonti di variazione: dispersione tra righe, dispersione tra colonne, dispersione dell'errore, dispersione totale, somma delle deviazioni al quadrato (SS), numero di gradi di libertà (df), varianza (MS ). Nelle ultime tre colonne - il valore effettivo del rapporto di Fisher (F), il livello p (valore P) e il valore critico del rapporto di Fisher (F critico).
| SM | F | valore p | Fcrit |
| 3,13 | 5,275281 | 0,075572 | 6,94476 |
| 8,043333 | 13,55618 | 0,016529 | 6,944276 |
| 0,593333 | |||
Fattore UN(dimensione del motore) è raggruppato in righe. Poiché l'effettivo rapporto Fisher 5,28 è inferiore al critico 6,94, assumiamo con una probabilità del 95% che il consumo di carburante non dipenda dalla cilindrata del motore.
Fattore B(tipo di carburante) è raggruppato in colonne. Il rapporto Fisher effettivo di 13,56 è maggiore del rapporto critico di 6,94, pertanto, con una probabilità del 95%, assumiamo che il consumo di carburante dipenda dal tipo.
Analisi bidirezionale della varianza con ripetizioni: l'essenza del metodo, formule, esempio
L'analisi bidirezionale della varianza con le ripetizioni viene utilizzata per verificare non solo la possibile dipendenza della caratteristica effettiva da due fattori: UN e B, ma anche la possibile interazione di fattori UN e B. Quindi un- numero di gradazioni del fattore UN e b- numero di gradazioni del fattore B, r- numero di ripetizioni. Nel complesso statistico, la somma dei residui al quadrato è divisa in quattro componenti:
SS = SS un + SS b+ SS ab + SS e,
![]() è la somma totale delle deviazioni al quadrato,
è la somma totale delle deviazioni al quadrato,
![]() - spiegato dall'influenza del fattore UN somma delle deviazioni al quadrato,
- spiegato dall'influenza del fattore UN somma delle deviazioni al quadrato,
![]() - spiegato dall'influenza del fattore B somma delle deviazioni al quadrato,
- spiegato dall'influenza del fattore B somma delle deviazioni al quadrato,
![]() - spiegato dall'influenza dell'interazione di fattori UN e B somma delle deviazioni al quadrato,
- spiegato dall'influenza dell'interazione di fattori UN e B somma delle deviazioni al quadrato,
![]() - somma inspiegabile di deviazioni al quadrato o somma di deviazioni di errore al quadrato,
- somma inspiegabile di deviazioni al quadrato o somma di deviazioni di errore al quadrato,
![]() - media totale delle osservazioni,
- media totale delle osservazioni,
![]() - media delle osservazioni in ciascuna gradazione del fattore UN
,
- media delle osservazioni in ciascuna gradazione del fattore UN
,
![]() - il numero medio di osservazioni in ciascuna gradazione del fattore B
,
- il numero medio di osservazioni in ciascuna gradazione del fattore B
,
Numero medio di osservazioni in ciascuna combinazione di gradazioni fattoriali UN e B ,
n = abrè il numero totale di osservazioni.
Le varianze sono calcolate come segue:
Dispersione spiegata dall'influenza del fattore UN ,
Dispersione spiegata dall'influenza del fattore B ,
![]() - dispersione spiegata dall'interazione di fattori UN e B
,
- dispersione spiegata dall'interazione di fattori UN e B
,
![]() - varianza inspiegabile o varianza di errore,
- varianza inspiegabile o varianza di errore,
vun = un − 1 - il numero di gradi di libertà della dispersione, spiegato dall'influenza del fattore UN ,
vb= b − 1 - il numero di gradi di libertà della dispersione, spiegato dall'influenza del fattore B ,
vab = ( un − 1)(b − 1) - il numero di gradi di libertà della dispersione, spiegato dall'interazione di fattori UN e B ,
ve= ab(r − 1) è il numero di gradi di libertà della varianza inspiegabile o dell'errore,
v = abr− 1 - numero totale di gradi di libertà.
Se i fattori sono indipendenti l'uno dall'altro, vengono avanzate tre ipotesi nulle e le corrispondenti ipotesi alternative per determinare la significatività dei fattori:
per il fattore UN :
H0 : μ 1A= μ 2A = ... = μ aa,
H1 : Non tutto μ iA sono uguali;
per il fattore B :
Per determinare l'influenza dell'interazione di fattori UN e B, dobbiamo confrontare il rapporto Fisher effettivo con il rapporto Fisher critico .
Se il rapporto di Fisher effettivo è maggiore del rapporto di Fisher critico, l'ipotesi nulla dovrebbe essere rifiutata con un livello di significatività α . Ciò significa che il fattore influisce in modo significativo sui dati: i dati dipendono dal fattore con una probabilità P = 1 − α .
Se il rapporto di Fisher effettivo è inferiore al rapporto di Fisher critico, l'ipotesi nulla dovrebbe essere accettata con un livello di significatività α . Ciò significa che il fattore non influisce in modo significativo sui dati con la probabilità P = 1 − α .
Analisi bidirezionale della varianza con ripetizioni: un esempio
sull'interazione dei fattori UN e B: il Fisher ratio effettivo è inferiore a quello critico, pertanto l'interazione tra la campagna pubblicitaria e lo specifico punto vendita non è significativa.
Analisi bidirezionale della varianza con ripetizioni in MS Excel
L'analisi bidirezionale della varianza con ripetizioni può essere eseguita utilizzando la procedura MS Excel. Lo utilizziamo per analizzare i dati sulla relazione tra i ricavi del negozio e la scelta di un determinato negozio e la campagna pubblicitaria dell'esempio 4.
Nel menu di MS Excel, eseguire il comando Servizio/Analisi dei dati e scegli uno strumento di analisi Analisi bidirezionale della varianza con ripetizioni.
Compiliamo i dati come nel caso di un'ANOVA a due vie senza ripetizioni, con l'aggiunta che nella casella numero righe da campionare, è necessario inserire il numero di ripetizioni.

Come risultato della procedura, vengono visualizzate due tabelle. La prima tabella è composta da tre parti: le prime due corrispondono a ciascuna delle due campagne pubblicitarie, la terza contiene i dati di entrambe le campagne pubblicitarie. Le colonne della tabella contengono informazioni su tutte le classi di gradazione del secondo fattore - memorizzare: numero di osservazioni, valore totale, valore medio e varianza.

Nella seconda tabella - dati sulla somma delle deviazioni quadrate (SS), il numero di gradi di libertà (df), la dispersione (MS), il valore effettivo del rapporto di Fisher (F), il livello p (valore P) e il valore critico del rapporto di Fisher (F critico) per diverse fonti di variazione: due fattori indicati in righe (campione) e colonne, interazioni tra fattori, errori (interni) e totali (totale).
| SM | F | valore p | Fcrit |
| 8,013339 | 0,500252 | 0,492897 | 4,747221 |
| 189,1904 | 11,81066 | 0,001462 | 3,88529 |
| 6,925272 | 0,432327 | 0,658717 | 3,88529 |
| 16,01861 | |||
Per il fattore B il Fisher ratio effettivo è maggiore del rapporto critico, quindi, con una probabilità del 95%, i ricavi variano in modo significativo tra i negozi.
Per l'interazione di fattori UN e B il rapporto effettivo di Fisher è meno che critico, quindi, con una probabilità del 95%, l'interazione tra la campagna pubblicitaria e un determinato negozio non è significativa.
Tutto su "Statistica matematica"
Analisi della varianza
1. Il concetto di analisi della varianza
Analisi della varianza- si tratta di un'analisi della variabilità di un tratto sotto l'influenza di eventuali fattori variabili controllati. Nella letteratura straniera, l'analisi della varianza è spesso indicata come ANOVA, che si traduce come analisi della varianza (Analisi della varianza).
Il compito di analisi della varianza consiste nell'isolare la variabilità di tipo diverso dalla variabilità generale del tratto:
a) variabilità dovuta all'azione di ciascuna delle variabili indipendenti studiate;
b) variabilità dovuta all'interazione delle variabili indipendenti studiate;
c) variazione casuale dovuta a tutte le altre variabili sconosciute.
La variabilità dovuta all'azione delle variabili studiate e alla loro interazione è correlata alla variabilità casuale. Un indicatore di questo rapporto è il test F di Fisher.
La formula per calcolare il criterio F include stime di varianze, cioè i parametri di distribuzione di una caratteristica, quindi il criterio F è un criterio parametrico.
Quanto più la variabilità del tratto è dovuta alle variabili studiate (fattori) o alla loro interazione, tanto maggiore è valori empirici del criterio.
Zero l'ipotesi nell'analisi della varianza dirà che i valori medi della caratteristica effettiva studiata in tutte le gradazioni sono gli stessi.
Alternativa l'ipotesi affermerà che i valori medi dell'attributo efficace in diverse gradazioni del fattore studiato sono diversi.
L'analisi della varianza ci consente di affermare un cambiamento in un tratto, ma non lo indica direzione questi cambiamenti.
Iniziamo l'analisi della varianza con il caso più semplice, quando studiamo l'azione di only uno variabile (fattore singolo).
2. Analisi unidirezionale della varianza per campioni non correlati
2.1. Scopo del metodo
Il metodo dell'analisi della varianza a fattore singolo viene utilizzato nei casi in cui i cambiamenti nell'attributo effettivo vengono studiati sotto l'influenza di condizioni mutevoli o gradazioni di qualsiasi fattore. In questa versione del metodo, l'influenza di ciascuna delle gradazioni del fattore è vari campione di soggetti di prova. Devono esserci almeno tre gradazioni del fattore. (Potrebbero esserci due gradazioni, ma in questo caso non saremo in grado di stabilire dipendenze non lineari e sembra più ragionevole usarne di più semplici).
Una variante non parametrica di questo tipo di analisi è il test H di Kruskal-Wallis.
Ipotesi
H 0: Le differenze tra i gradi dei fattori (condizioni diverse) non sono più pronunciate delle differenze casuali all'interno di ciascun gruppo.
H 1: Le differenze tra le gradazioni dei fattori (condizioni diverse) sono più pronunciate delle differenze casuali all'interno di ciascun gruppo.
2.2. Limitazioni dell'analisi univariata della varianza per campioni non correlati
1. L'analisi univariata della varianza richiede almeno tre gradazioni del fattore e almeno due soggetti in ciascuna gradazione.
2. Il tratto risultante deve essere normalmente distribuito nel campione di studio.
Vero, di solito non viene indicato se si tratta della distribuzione di un tratto nell'intero campione intervistato o in quella parte di esso che costituisce il complesso di dispersione.
3. Un esempio di risoluzione del problema con il metodo dell'analisi della varianza a fattore singolo per campioni non correlati utilizzando l'esempio:
Tre diversi gruppi di sei soggetti hanno ricevuto liste di dieci parole. Le parole sono state presentate al primo gruppo con una frequenza bassa di 1 parola ogni 5 secondi, al secondo gruppo con una frequenza media di 1 parola ogni 2 secondi e al terzo gruppo con una frequenza elevata di 1 parola al secondo. Si prevedeva che le prestazioni di riproduzione dipendessero dalla velocità di presentazione delle parole. I risultati sono presentati nella tabella. uno.
Numero di parole riprodotte Tabella 1
|
numero del soggetto |
bassa velocità |
velocità media |
alta velocità |
|
importo totale |
|||
H 0: Differenze nel volume delle parole fra i gruppi non sono più pronunciati delle differenze casuali dentro ciascun gruppo.
H1: Differenze nel volume delle parole fra i gruppi sono più pronunciati delle differenze casuali dentro ciascun gruppo. Utilizzando i valori sperimentali presentati in Tabella. 1, stabiliremo alcuni valori che serviranno per calcolare il criterio F.
Il calcolo delle principali grandezze per l'analisi della varianza unidirezionale è presentato nella tabella:
Tavolo 2
Tabella 3
Sequenza di operazioni in ANOVA unidirezionale per campioni disconnessi

Usata frequentemente in questa e nelle successive tabelle, la designazione SS è l'abbreviazione di "somma dei quadrati". Questa abbreviazione è usata più spesso nelle fonti tradotte.
SS fatto indica la variabilità del tratto, dovuta all'azione del fattore studiato;
SS Comune- variabilità generale del tratto;
S circa- variabilità dovuta a fattori non contabilizzati, variabilità “casuale” o “residua”.
SM- "quadrato medio", ovvero l'aspettativa matematica della somma dei quadrati, il valore medio del corrispondente SS.
df - il numero di gradi di libertà, che, considerando criteri non parametrici, abbiamo indicato con la lettera greca v.
Conclusione: H 0 è respinto. H 1 è accettato. Le differenze nel volume di riproduzione delle parole tra i gruppi sono più pronunciate delle differenze casuali all'interno di ciascun gruppo (α=0,05). Quindi, la velocità di presentazione delle parole influisce sul volume della loro riproduzione.
Di seguito viene presentato un esempio di risoluzione del problema in Excel:
Dati iniziali:

Utilizzando il comando: Strumenti->Analisi dati->Analisi della varianza unidirezionale, otteniamo i seguenti risultati:

Lo schema di analisi della varianza considerato si differenzia in funzione: a) della natura dell'attributo, in base al quale la popolazione è suddivisa in gruppi (campioni); b) del numero di segni, in base al quale la popolazione è suddivisa in gruppi ( campioni); c) sul metodo di campionamento.
Valori delle caratteristiche. che suddivide la popolazione in gruppi può rappresentare una popolazione generale o una popolazione ad essa prossima per dimensione. In questo caso, lo schema per condurre l'analisi della varianza corrisponde a quello sopra considerato. Se i valori dell'attributo che forma gruppi diversi rappresentano un campione della popolazione generale, cambia la formulazione delle ipotesi nulle e alternative. Come ipotesi nulla, si presume che ci siano differenze tra i gruppi, ovvero che i mezzi del gruppo mostrino qualche variazione. Un'ipotesi alternativa è che non vi sia volatilità. Ovviamente, con una tale formulazione di ipotesi, non c'è motivo di concretizzare i risultati del confronto delle varianze.
Con un aumento del numero di funzioni di raggruppamento, ad esempio, fino a 2, in primo luogo, aumenta il numero di ipotesi nulle e, di conseguenza, alternative. In questo caso, la prima ipotesi nulla indica l'assenza di differenze tra le medie per i gruppi del primo tratto di raggruppamento, la seconda ipotesi nulla indica l'assenza di differenze nelle medie per i gruppi del secondo tratto di raggruppamento ed infine la terza ipotesi nulla indica l'assenza del cosiddetto effetto dell'interazione di fattori (tratti di raggruppamento).
Per effetto dell'interazione si intende un tale cambiamento nel valore della caratteristica effettiva, che non può essere spiegato dall'azione totale di due fattori. Per verificare le tre coppie di ipotesi avanzate, è necessario calcolare tre valori effettivi del criterio F-Fisher, che a sua volta implica la seguente variante dell'espansione del volume totale di variazione
Le dispersioni necessarie per ottenere il criterio F si ottengono in modo noto dividendo i volumi di variazione per il numero di gradi di libertà.
Come sapete, i campioni possono essere dipendenti indipendenti. Se i campioni sono dipendenti, nell'ammontare totale della variazione si dovrebbe distinguere la cosiddetta variazione nelle ripetizioni  . Se non viene individuata, questa variazione può aumentare significativamente la variazione intragruppo (
. Se non viene individuata, questa variazione può aumentare significativamente la variazione intragruppo (  ), che possono falsare i risultati dell'analisi della varianza.
), che possono falsare i risultati dell'analisi della varianza.
Domande di revisione
17-1 Qual è la specificazione dei risultati dell'analisi della varianza?
17-2. In che caso viene utilizzato il criterio Q-Tukey per la concretizzazione?
17-3 Quali sono le differenze tra il primo, il secondo e così via?
17-4. Come trovare il valore effettivo del criterio Q di Tukey?
17-5 Quali sono le ipotesi per ciascuna differenza?
17-6. Da cosa dipende il valore tabulare del test Q di Tukey?
17-7. Quale sarà l'ipotesi nulla se i livelli della caratteristica di raggruppamento rappresentano un campione?
17-8 Come viene scomposta la quantità totale di variazione quando si raggruppano i dati secondo due criteri?
17-9. In che caso si distingue la variazione in ripetizioni (  )
?
)
?
Riepilogo
Il meccanismo considerato per concretizzare i risultati dell'analisi della dispersione ci consente di dargli una forma finita. Prestare attenzione alle limitazioni quando si utilizza il test Q di Tukey. Il materiale ha anche delineato i principi di base per la classificazione dei modelli di analisi della varianza. Va sottolineato che questi sono solo principi. Uno studio dettagliato delle caratteristiche di ciascun modello richiede uno studio più approfondito separato.
Compiti di prova per la lezione
Quali caratteristiche statistiche sono ipotizzate nell'analisi della varianza?
Relativo a due dispersioni
Per quanto riguarda una media
Per quanto riguarda diverse medie
Relativo a una varianza
Qual è il contenuto dell'ipotesi alternativa nell'analisi della varianza?
Le varianze comparabili non sono uguali tra loro
Tutte le medie confrontate non sono uguali tra loro
Almeno due mezzi generali non sono uguali
La varianza intergruppo è maggiore della varianza intragruppo
Quali livelli di significatività vengono utilizzati più spesso nell'analisi della varianza
Se la variazione all'interno del gruppo è maggiore della variazione tra i gruppi, l'analisi della varianza dovrebbe essere continuata o dovremmo accettare immediatamente H0 o HA?
1. Dovremmo continuare determinando le varianze necessarie?
2. Dobbiamo essere d'accordo con H0
3. Dovrebbe essere d'accordo con NA
Se la varianza intragruppo fosse uguale alla varianza intergruppo, quali dovrebbero essere le azioni dell'ANOVA?
D'accordo con l'ipotesi nulla che le medie della popolazione siano uguali
Concordare con l'ipotesi alternativa sulla presenza di almeno una coppia di mezzi disuguali tra loro
Quale varianza dovrebbe sempre essere nel numeratore quando si calcola il test F di Fisher?
Solo intragruppo
In ogni caso, intergruppo
Intergruppo, se è maggiore dell'intragruppo
Quale dovrebbe essere il valore effettivo del criterio F-Fisher?
Sempre meno di 1
Sempre maggiore di 1
Uguale o maggiore di 1
Da cosa dipende il valore tabulare del criterio F-Fisher?
1. Dal livello di significatività accettato
2. Sul numero di gradi di libertà della variazione generale
3. Sul numero di gradi di libertà di variazione intergruppo
4. Sul numero di gradi di libertà di variazione intragruppo
5. Dal valore del valore effettivo del criterio F-Fisher?
Aumentare il numero di osservazioni in ciascun gruppo con varianze uguali aumenta la probabilità di accettare ……
1. Ipotesi nulla
2.Ipotesi alternativa
3. Non pregiudica l'accoglimento sia dell'ipotesi nulla che alternativa
A che serve concretizzare i risultati dell'analisi della varianza?
Chiarire se i calcoli delle varianze sono stati eseguiti correttamente
Determina quale delle medie generali si è rivelata uguale tra loro
Chiarire quali delle medie generali non sono uguali tra loro
L'affermazione è vera: "Quando si concretizzano i risultati dell'analisi della varianza, tutte le medie generali si sono rivelate uguali tra loro"
Può essere vero e falso
Non è vero, ciò potrebbe essere dovuto a errori nei calcoli
È possibile, nel concretizzare l'analisi della varianza, giungere alla conclusione che tutte le medie generali non sono uguali tra loro?
1. Abbastanza possibile
2. Possibile in casi eccezionali
3. Impossibile in linea di principio.
4. Possibile solo se ci sono errori nei calcoli
Se l'ipotesi nulla è stata accettata secondo il test F-Fisher, è necessario specificare l'analisi della varianza?
1. Richiesto
2.Non richiesto
3.A discrezione dell'ANOVA
In quale caso viene utilizzato il criterio di Tukey per concretizzare i risultati dell'analisi della varianza?
1. Se il numero di osservazioni tra i gruppi (campioni) è lo stesso
2. Se il numero di osservazioni per gruppi (campioni) è diverso
3. Se sono presenti campioni con numeri uguali e diversi
pigrizia
Qual è la NSR quando si concretizzano i risultati dell'analisi della varianza basata sul criterio di Tukey?
1. Il prodotto dell'errore medio e il valore effettivo del criterio
2. Il prodotto dell'errore medio e il valore tabulare del criterio
3. Il rapporto di ciascuna differenza tra il campione significa a
errore medio
4. Differenza tra le medie campionarie
Se il campione è diviso in gruppi in base a 2 caratteristiche, in quante fonti dovrebbe essere suddivisa almeno la variazione totale della caratteristica?
Se le osservazioni per campioni (gruppi) sono dipendenti, in quante fonti dovrebbe essere suddivisa la variazione totale (attributo di raggruppamento uno)?
Qual è la fonte (causa) della variazione tra i gruppi?
gioco d'azzardo
Azione congiunta del gioco d'azzardo e di fattore
Azione del/dei fattore/i
Sarà chiaro dopo l'analisi della varianza
Qual è la fonte (causa) della variazione intragruppo?
1. Gioco d'azzardo
2. L'azione congiunta del gioco del caso e del fattore
3. Azione del fattore (fattori)
4. Diventerà chiaro dopo l'analisi della varianza
Quale metodo di trasformazione dei dati di origine viene utilizzato se i valori caratteristici sono espressi in condivisioni?
Logaritmo
estrazione della radice
Trasformazione Phi
Lezione 8 Correlazione
annotazione
Il metodo più importante per studiare la relazione tra le caratteristiche è il metodo di correlazione. Questa lezione svela il contenuto di questo metodo, si avvicina all'espressione analitica di questa relazione. Particolare attenzione è rivolta a tali indicatori specifici come indicatori della vicinanza della comunicazione
Parole chiave
Correlazione. Metodo dei minimi quadrati. Coefficiente di regressione. Coefficienti di determinazione e correlazione.
Questioni in esame
Comunicazione funzionale e di correlazione
Fasi di costruzione dell'equazione di correlazione della comunicazione. Interpretazione dei coefficienti di equazione
Indicatori di tenuta
Valutazione di campioni di indicatori di comunicazione
Unità modulare 1 L'essenza della correlazione. Fasi di costruzione dell'equazione di correlazione della comunicazione, interpretazione dei coefficienti dell'equazione.
Scopo e obiettivi dello studio dell'unità modulare 1 consiste nel comprendere le caratteristiche della correlazione. padroneggiare l'algoritmo per costruire un'equazione di connessione, comprendere il contenuto dei coefficienti dell'equazione.
L'essenza della correlazione
Nei fenomeni naturali e sociali, ci sono due tipi di connessioni: una connessione funzionale e una connessione di correlazione. Con una connessione funzionale, ogni valore dell'argomento corrisponde a valori rigorosamente definiti (uno o più) della funzione. Un esempio di relazione funzionale è la relazione tra circonferenza e raggio, espressa dall'equazione  . Ogni valore di raggio r corrisponde a un unico valore di circonferenza l
.
Con una correlazione, ogni valore di un attributo fattore corrisponde a diversi valori non del tutto certi dell'attributo risultante. Esempi di correlazione possono essere il rapporto tra il peso di una persona (carattere risultante) e la sua altezza (carattere fattoriale), il rapporto tra la quantità di fertilizzante applicato e la resa, tra il prezzo e la quantità dei beni offerti. La fonte dell'emergere di una correlazione è il fatto che, di regola, nella vita reale, il valore della caratteristica effettiva dipende da molti fattori, compresi quelli che hanno una natura casuale del loro cambiamento. Ad esempio, lo stesso peso di una persona dipende dall'età, dal sesso, dall'alimentazione, dall'occupazione e da molti altri fattori. Ma allo stesso tempo è ovvio che, in generale, è la crescita il fattore decisivo. Alla luce di queste circostanze, la relazione di correlazione dovrebbe essere definita come una relazione incompleta, che può essere stabilita e valutata solo se c'è un numero medio di osservazioni elevato.
. Ogni valore di raggio r corrisponde a un unico valore di circonferenza l
.
Con una correlazione, ogni valore di un attributo fattore corrisponde a diversi valori non del tutto certi dell'attributo risultante. Esempi di correlazione possono essere il rapporto tra il peso di una persona (carattere risultante) e la sua altezza (carattere fattoriale), il rapporto tra la quantità di fertilizzante applicato e la resa, tra il prezzo e la quantità dei beni offerti. La fonte dell'emergere di una correlazione è il fatto che, di regola, nella vita reale, il valore della caratteristica effettiva dipende da molti fattori, compresi quelli che hanno una natura casuale del loro cambiamento. Ad esempio, lo stesso peso di una persona dipende dall'età, dal sesso, dall'alimentazione, dall'occupazione e da molti altri fattori. Ma allo stesso tempo è ovvio che, in generale, è la crescita il fattore decisivo. Alla luce di queste circostanze, la relazione di correlazione dovrebbe essere definita come una relazione incompleta, che può essere stabilita e valutata solo se c'è un numero medio di osservazioni elevato.
1.2 Fasi di costruzione dell'equazione di correlazione della comunicazione.
Come una connessione funzionale, una connessione di correlazione è espressa da un'equazione di connessione. Per costruirlo, devi seguire in sequenza i seguenti passaggi (fasi).
Innanzitutto, dovresti capire le relazioni di causa ed effetto, scoprire la subordinazione dei segni, cioè quali di loro sono cause (segni fattoriali) e quali conseguenze (segni effettivi). Le relazioni di causa ed effetto tra le caratteristiche sono stabilite dalla teoria del soggetto in cui viene utilizzato il metodo di correlazione. Ad esempio, la scienza dell'"anatomia umana" permette di dire qual è la fonte del rapporto tra peso e altezza, quale di questi segni è un fattore, quale risultato, la scienza dell'"economia" svela la logica del rapporto tra prezzo e offerta, stabilisce quale e in quale fase è la causa e qual è l'effetto. Senza una tale prova teorica preliminare, l'interpretazione dei risultati ottenuti in seguito è difficile e talvolta può portare a conclusioni assurde.
Stabilita la presenza di relazioni di causa ed effetto, queste relazioni dovrebbero poi essere formalizzate, cioè espresse utilizzando un'equazione di connessione, scegliendo prima il tipo di equazione. Per selezionare il tipo di equazione, possono essere consigliati diversi metodi. Puoi passare alla teoria dell'argomento in cui viene utilizzato il metodo di correlazione, ad esempio la scienza dell'"agrochimica" potrebbe aver già ricevuto una risposta alla domanda su quale equazione dovrebbe esprimere la relazione: resa - fertilizzante. Se non esiste una risposta del genere, per selezionare un'equazione, è necessario utilizzare alcuni dati empirici, elaborandoli di conseguenza. Va subito detto che, avendo scelto il tipo di equazione sulla base di dati empirici, si deve comprendere chiaramente che questo tipo di equazione può essere utilizzata per descrivere la relazione dei dati utilizzati. La tecnica principale per elaborare questi dati è la costruzione di grafici, quando i valori dell'attributo fattore sono tracciati sull'asse delle ascisse e i possibili valori dell'attributo effettivo vengono tracciati sull'asse delle ordinate. Poiché, per definizione, lo stesso valore dell'attributo factor corrisponde a un insieme di valori incerti dell'attributo di quello effettivo, a seguito delle azioni di cui sopra, otterremo un certo insieme di punti, che prende il nome di campo di correlazione. La forma generale del campo di correlazione consente in alcuni casi di fare un'ipotesi sulla possibile forma dell'equazione. Con lo sviluppo moderno della tecnologia informatica, uno dei metodi principali per scegliere un'equazione è enumerare diversi tipi di equazioni, mentre l'equazione che fornisce il coefficiente di determinazione più alto viene scelta come migliore, discorso che verrà discusso di seguito. Prima di procedere ai calcoli, è necessario verificare se i dati empirici coinvolti nella costruzione dell'equazione soddisfano determinati requisiti. I requisiti si applicano alle caratteristiche dei fattori e alla totalità dei dati. I segni fattoriali, se ce ne sono diversi, devono essere indipendenti l'uno dall'altro. Per quanto riguarda l'aggregato, deve essere prima omogeneo
(il concetto di omogeneità è stato considerato in precedenza) e, in secondo luogo, è piuttosto ampio. Per ogni segno del fattore, dovrebbero esserci almeno 8-10 osservazioni.
Dopo aver scelto un'equazione, il passo successivo è calcolare i coefficienti dell'equazione. Il calcolo dei coefficienti dell'equazione viene spesso effettuato sulla base del metodo dei minimi quadrati. Dal punto di vista della correlazione, l'uso del metodo dei minimi quadrati consiste nell'ottenere tali coefficienti dell'equazione che  =min, cioè in modo che la somma delle deviazioni al quadrato dei valori effettivi della caratteristica risultante (
=min, cioè in modo che la somma delle deviazioni al quadrato dei valori effettivi della caratteristica risultante (  ) da quelli calcolati secondo l'equazione (
) da quelli calcolati secondo l'equazione (  ) era il valore minimo. Questo requisito si realizza costruendo e risolvendo un noto sistema di cosiddette equazioni normali. Se, come equazione della correlazione tra y e X si sceglie l'equazione di una retta
) era il valore minimo. Questo requisito si realizza costruendo e risolvendo un noto sistema di cosiddette equazioni normali. Se, come equazione della correlazione tra y e X si sceglie l'equazione di una retta  , dove è noto che il sistema di equazioni normali è:
, dove è noto che il sistema di equazioni normali è: 

Risolvere questo sistema per un e b
,
otteniamo i valori richiesti dei coefficienti. La correttezza del calcolo dei coefficienti è verificata dall'uguaglianza 
- In contatto con 0
- Google+ 0
- OK 0
- Facebook 0